CS294-112 2018课程笔记-1
-
CS294-112 2018课程笔记-1
课程主要讨论强化学习和深度强化学习的内容
-
什么是强化学习
深度学习已经(大致)解决了识别环境的问题,这只是帮助人类做出决策的手段。强化学习的目的是不只是识别,而是得出当前状态下应该采取的行动。
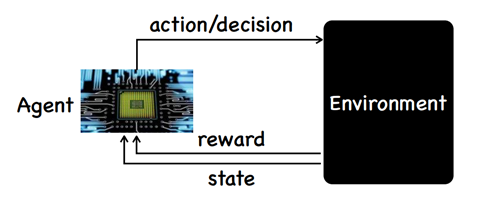
agent decisiongs environment rewards -
TD gammon
第一个使得强化学习在游戏领域获得成功的方案。他是一种将强化学习与神经网络相结合,得到网络的价值函数。模型采用的算法成为集合值迭代算法(fitted value iteration)。(与alpho GO类似)。
-
什么是deep RL
十五年前,cv关注的内容是得到图片的fearure,在图片中得到图片的各种人为规定的feature。通过预定的feature,再学习到高层的组合feature,学习只在最后的几层达到。
deep learning 是端到端的,feature 是自动得到的。
关于RL,是将当前的状态得到feature,然后使用当前的状态feature和各种价值函数得到当前的决策。这就导致获得当前的feature就是使得RL达到更高的水平的瓶颈。
deep RL 可以使得RL变得end2end,使得feature 的获得变成一个自动的过程。高质量的feature提升了RL系统的上上限。
-
examples
机器人系统,使得机器人学会一个功能。
-
关于价值函数
价值函数是模型优化的目标,为了打成确定的目标,需要根据要求设定与目标相同的价值的函数。
所以无论是什么问题,只要精确的设计了价值函数,总能通过强化学习的方法解决。
-
rewards
可能是game的score,但是生活中的事情并没有score,没有明确的意义和价值表达,And:
You konw as human agents we are accustomed to operating with rewards thar are so sparse that we only experienced them once or twice in a lifetime if at all.
如果只有完成一件事情才能得到reward,则有的事情根本不会开始。所以模仿也是获得经验的一种方式。观察学习。迁移学习。
-
预测
预测动作后环境的样子。以此获得在未经理的事情下的动作能努力。
-
how to build intelligent machines
假设
learning as the basis if intelligence
-
至今RL仍然存在的问题
- 人类学习的学习速度相较机器incredibly quickly
- 人类可以使用以往的学习经验
- 并不清楚reward function 的作用
- production 在RL的中的定位并不明晰,我们不知道是否应该发展model-free RL还是model-based RL还是他们本质上是相同的东西。
-
-
CS294-112 2018课程笔记-2
主要内容
-
definition of sequential decision problems
序列决策问题的定义
-
Imitation learning: supervised learning for decision making
模仿学习
- does direct imitation work
- how can we make it work more often
-
case studies of recent work in (deep) imitation learning
-
what is missing from imitation learning
课程
###一些定义

因为我们不能一次性观察所有的
,所以使用的是 进行预测,我们从 得到 的分布。 另一个重要的条件(or 假设):
是独立于 的,这表明,如果只知道当前的状态而根本不知道过去的状态,如果能精确的知道当前的状态,那么之前的状态并不能帮助model or agent预测之后的状态。所以在状态决策问题中,如果能知道当前的状态的所有信息,则之前的信息对当前的决策不会有任何帮助,当前的知识就是所有需要用来预测动作的所有需要的信息。 在这里,如果知道
的所有信息,则之前的 的信息对做出 并不能有任何帮助。但是,观察之间并不是独立的,下一条观察取决于之前所有的观察的总和。 所以在这里,这个决策链是马尔可夫的,即
仅仅条件依赖于 ,这个性质叫做马尔可夫性质。 
不同的表达形式:
在控制论中:之前的
表示为 , 表示为 。 具体的问题
-
克隆学习
完全模仿人类的动作。有时并不可行,why?
人类犯错,没见过的情况,人类依据经验动作等等。
另外的问题,机器的误差会累积,机器偏移会累积。
需要解决的问题:让机器学会纠正自己的误差。
当前收集的数据, 模型的参数
让相当于让机器没有在data上的误差 如何做到,DAgger: Dataset Aggregaion
goal: collect training data from
instead of how? just run
but labels - 从人类的数据
训练 - 训练
得到新的dataset - 询问人类专家,打标
得到 的 - Aggregate:
- repeat 1
在这种情况下,可以解决样本分布不均的问题。这种训练方法收敛的条件是长时间的训练(在线训练)。
虽然也可以采用随机的策略进行初始训练,但是会导致训练困难,难以收敛的情况出现(不能保证收敛)。
 这种方法并没有使用价值函数
这种方法并没有使用价值函数 - 从人类的数据
DAgger的劣势:
-
需要大量的打标
-
有的时候会难以拟合人类的行为(因为马尔可夫假设)
-
...
-
为什么会无法拟合专家的行为?
-
非马尔可夫行为(Non-Markovian behavior)
相比于使用
只依赖于当前的观察 ,而是 ,将行为依赖于所有的观察。 但是并不能将所有的观察input到网络中,这个问题解决的方法老师推荐是使用LSTM
-
多模型行为(Multimodal behavior)
有的时候行为是离散且多样的,可以使用最后一层添加softmax获得(离散)行为的分布。
tips:平均平方误差是高斯分布的对数概率
可能的问题是如果输出是个高斯分布,会让模型同时采取两种行为。
解决方法:
- 输出混合高斯模型
- 使用隐变量模型
- 选择行动时,使用自动回归离散化
具体:
-
输出混合高斯模型
输出不是一个均值和方差,而是N个均值和N个方差,这里的
的和是1 这种方法称之为混合密度网络。
-
隐变量模型
输出仍然是一个单个的高斯分布,但是在模型的输入中增加一个随机数输入
这个随机数可以是高斯分布或者均匀分布中采样获得。增加网络的随机性,改变输出的分布。
具体的说,在面对离散选择时,模型将在噪声中学习,解决离散问题。
但是如果模型的优化方向不正确,可能难以训练。(如果只是将噪声引入,使用最大似然进行训练,效果可能并不理想)
让神经网络有效利用噪声的方法:
conditional variational auto-encoder
normalizing flow/realNVP
stein variational gradient descent
-
自动回归离散化
对于纬度较低的output,可以使用直接离散化的方法,但是如果输出的纬度较高,则很难将输出直接离散化。
自动回归离散的方法是将输出的某个维度直接离散化,然后将离散化的结果输入到另一个深度网络,用第一个维度的所有采样和第二个维度的条件来预测一个离散化的结果。
之后重复这个过程,对所有维度进行离散化。
(并没有看懂)
-
逆强化学习
-
模仿学习的问题还有啥?
- data是有限的,这可能限制了AI的上限
-
人类并不能示范所有的action,如控制机器人(大量参数,10条腿,20只手),或者超越人类等
- 机器能否自主学习?不断进化?
-
这里目标的概念:
在模仿学习中:复制示范的动作
可以定义reward function:
符合专家行为的对数概率
s状态下,选择的动作a等于
(专家)的动作的概率的对数(感觉应该是cost function) 或者其他的cost function: 01loss
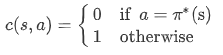
动作相同,0
动作不同,1
DAgger 方法可以最大化这里的reward function
在自主学习中:
$c(x,u) \ cost\ function 控制论\ r(s_t,a_t)\ reward \ function 强化学习$ 二者十分类似,只是在数值上互为相反数。
现在举一个例子:
对于cost function:
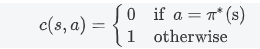
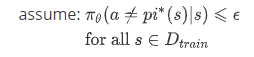
意思是在所有的traindata 中的结果都不会太差。
对于T个steps,所有的cost和的期望:
损失是T平方级
More general analysis
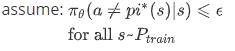
对于所有的和训练数据相同分布的
,犯错的概率的上限也只是 ,(这是一种非常强的假设) 如果使用DAgger , 数据分布不匹配的问题就会消失,所以看到的样本和P_train相同。
经过最良好的训练后,得到的cost function 的数量级应该是:T线性
-
-
-
我刚准备把285的笔记发论坛就看到你发了18年294的
-
@why 你这是最新课程,得发