深度学习—你的数据够多么?
-
引用
谷歌研究文章:http://www.anyv.net/index.php/article-1427413
百度研究院文章:http://www.sohu.com/a/209748313_114877数据够多么?
这里两家巨佬的一致性结论,明确一下深度学习萌新们对于数据量的一个观点,这也是我之前一直考虑的事情:网络喂入的数据量大了之后会不会导致网络分不出来,或者到了无法解析的瓶颈。下面来解决大家这个疑惑!
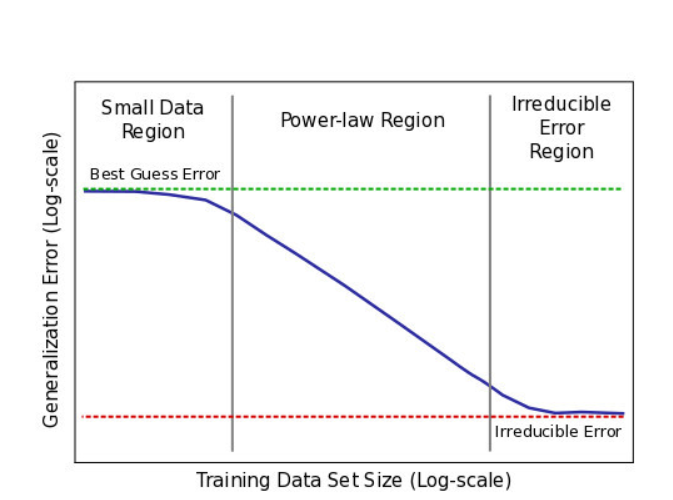
数据量不同阶段
通常使用的模型一样时,喂不同数量级的数据可以性能呈现3个阶段(下图横坐标取了对数)。
- 第一阶段:数据很少,网络学习不出东西。
- 第二阶段:数据多了,随着数据指数增长,性能线性提升。
- 第三阶段:饱和了,数据大到一定程度,上帝都分不清楚了,当前模型理论无法超越的底线。
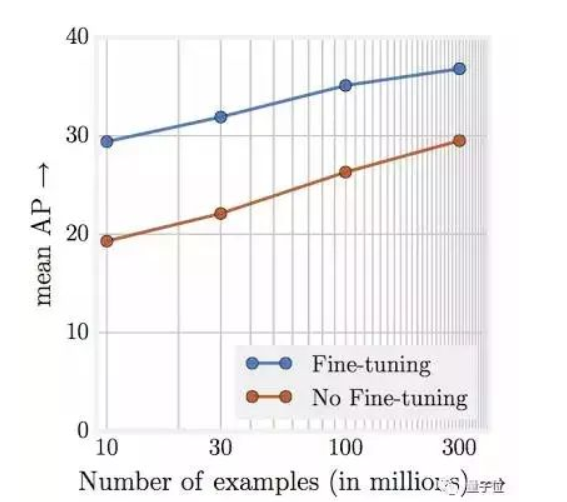
然而~,google在3亿张图片上进行了测试,发现这个数量级,仍然保持了这个规律,有点像摩尔定律哦~,说明对于很多深度学习问题来说,数据量永远不要担心太多。下图训练集中存在20%的噪声,但是大数据量还是掩盖了噪声的干扰(这一点没有去原文论证)。其次,随着数据的增大,网络的容量增大是必要的,不然无法满足其所需的复杂度。
一点结论
- 数据不怕多,目前的问题,数据越多越好
- 数据不怕噪声(一定程度内),数据噪声可以被数据量部分掩盖
- 数据越大,网络需要越大,这里的大不光是参数变多,同时也对应着更深的网络。(有人研究,相同复杂度的情况下,深层网络会比浅层宽网络更容易训练哦)
-
不够多不要紧,贝贝组标签队是您的忠实后盾。为您的深度学习保驾护航。
-
@hunto 这个回复和签名一样骚
-
@hunto 老铁厉害了,肝完论文,我就加入贝贝标签队。