AI炼丹小站
-
来团队两年了,借最近准备研究岗面试的DDL,来push自己开心填坑,也和大家分享一些深度学习相关的知识和项目总结,请多多指教。
-
一、卡片识别项目
- 项目说明:对不同姿态、不同背景的卡片分类系统,于 2018 年 11 月结题。
- 项目解析:用mobilenet v2(width multi=0.35)网络,对输入448*448的图片进行500类分类,使用softmax交叉熵损失函数,最终在卡片与摄像头距离1米范围内,测试达获得98.6%的精度。
- 项目细节:
-
1、与一般分类问题,本项目的难点在于背景比例过高,卡片面积比例从1/25~1/4。
-
2、数据集创新,利用卡片原稿制作训练集。 共有3000张测试集,50000张训练集(其中5000张是拍摄的,45000张是手动生成,将卡片贴在上网扒取的背景熵)。单5000张训练集,准确率仅为78%。需要调整卡片的亮度和背景亮度统一,在卡片上增加噪点(对卡片像素值随机加减一个范围内的随机数),并图片做平移、旋转、仿射变换及边缘缺失各种变换以模拟拍摄角度的变化。
-
3、针对儿童应用对app特殊优化,增加发音之类的。
-
4、投票机制,说得更好听一点的话,叫图像分隔策略。将一张图片划分成五个区域,上下左右中,分别对五个区域进行分类预测,最终投票出结果。由于这种操作将计算量提升了四倍卡,最终并没有采用。
-
5、参考tflite量化并部署。
-
6、尝试的其他模型有shufflenet v1,nasnet等。
-
(注:特别感谢优秀蔡联飞的解答)
-
二、LittleLights: 移动端实时人脸关键点定位项目
- 项目说明:与上海微芒教育科技有限公司合作,106 点人脸关键点定位,对标商汤科技 API。
- 人脸关键点定位:
- 数据集:商汤API打标+人工筛选
- 涉及:人脸角度预测、Mimic、测试kalman滤波防抖效果
- 防抖问题:使用KCF人脸追踪解决MTCNN抖动问题
- 部署:Mace、ncnn、SDK优化(线程调度)
- 相关模型:squeezenet、PFLD、MobileNet
- 人脸跟踪
- LK光流跟踪算法、用lucas kanade光流跟踪替换kcf跟踪
- 人脸框检测:
- 相关模型:mtcnn、ThunderNet、CenterNet、LFFD
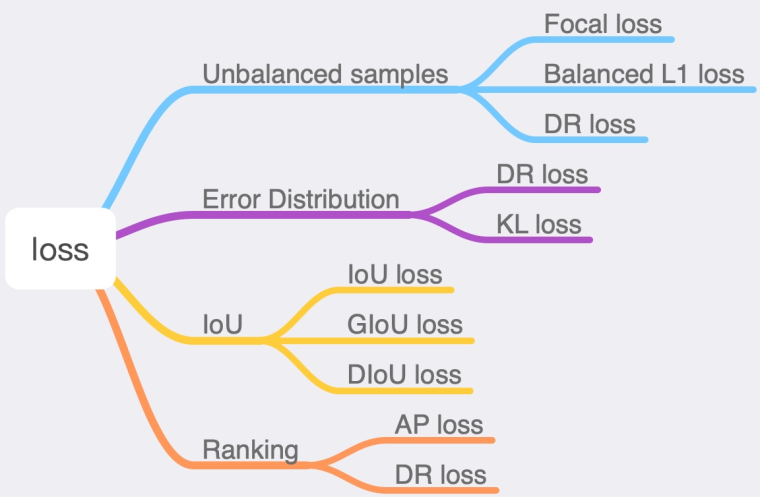
- 目标检测领域的loss设计
-
三、AI Mooc: 基于知识图谱的领域自适应慕课智能问答调研
- 项目说明:与达闼科技合作;知识工程;语义理解;智能问答;于 2019 年 9 月结题。
-
四、AIbot: 贝贝集团智能客服项目
- 项目说明:与贝贝集团合作;母婴电商智能客服系统;检索式问答方式;准确率 95% 左右,各项指标略高于追一科技 Yibot 系统,已在贝贝、贝店上线;于 2018 年 7 月结题。
- 涉及:预训练的TextCNN模型训练Multitask
- 一些实验:
DilaTextCNN: 0.7855
DoubleCNNTextBNDeep: 0.7979
TextCNNInc: 0.7903
TextCNNIncDeep: 0.7917
DilaTextCNNRes: 0.7889
-
五、2019 CCF 大数据与计算智能大赛 (多人种识别赛道):TOP 2.5%
- 比赛描述: 同时优化人脸识别模型在不同人种上的性能,提高在低误识率情况下不同人种的通过率。
- 解题思路: 使用 arcface 模型,提取人脸的特征向量,再通过向量距离进行比对。
- 创新点:种族后验概率校正,人脸重对齐,GANs 数据增强。
-
六、2018年津南数字制造算法挑战赛:TOP 1.8%
- 比赛描述: 物流货物限制品监测,属于目标检测与语义分割任务。
- 解题思路: 使用RetinaNet、Faster RCNN、Mask RCNN、Mask Scoring RCNN等模型得到检测框或mask。
- 创新点:mask结果修正,多感受野级联,新标签数据增强,引入多尺度训练。
- 完善细节:
- 多尺度训练:
- 1.用于解决过拟合问题,在图像数据集不是特别充足的情况下,可以先训练小尺寸图像,然后增大尺寸并再次训练相同模型,这样的思想在Yolo-v2的论文中也提到过。
- 2.通过输入不同尺度的图像数据集,因为神经网络卷积池化的特殊性,这样可以让神经网络充分地学习不同分辨率下图像的特征。
- 比赛分为正常图与异常图
- 在检测前,加入了一个vgg二分类网络。
- 多尺度训练:
- mask结果修正:
- 参考2019年mask scoring rcnn。(2020年也有一篇cvpr oral, 叫做BlendMask。在SOTA 目标检测算法FCOS基础上,改进得到BlendMask。检测分支得到目标包围框和attns注意力区块,其和Bottom 模块的结果Bases 经Blender模块blend成最终的分割结果。)
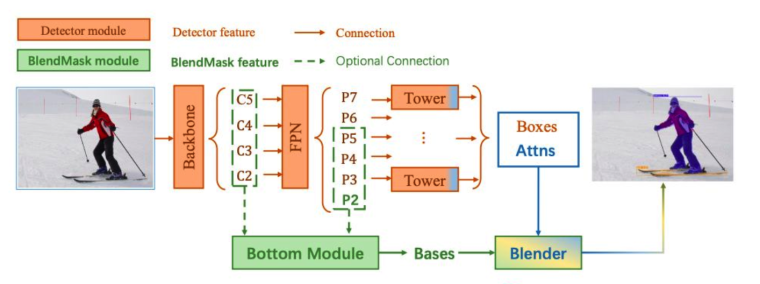
- 参考2019年mask scoring rcnn。(2020年也有一篇cvpr oral, 叫做BlendMask。在SOTA 目标检测算法FCOS基础上,改进得到BlendMask。检测分支得到目标包围框和attns注意力区块,其和Bottom 模块的结果Bases 经Blender模块blend成最终的分割结果。)
-
七、Django 后台开发
想起那个实训,五个人还一人拿了100的奖金,感觉很快乐~后台部分代码
-
概述:Django是一个开放源代码的Web应用框架,由Python写成。采用了MVC的软件设计- 模式,即模型M,视图V和控制器C。
-
任务:青蛙记账,qt+微信小程序+web+Django后台+MySQL。
-
运用要点:
Django 模板
Django 模型
Django 表单
Django Admin 管理工具 -
一览全貌:
-
urls.py
网址入口,关联到对应的views.py中的一个函数(或者generic类),访问网址就对应一个函数。 -
views.py
处理用户发出的请求,从urls.py中对应过来, 通过渲染templates中的网页可以将显示内容,比如登陆后的用户名,用户请求的数据,输出到网页。 -
models.py
与数据库操作相关,存入或读取数据时用到这个,当然用不到数据库的时候 你可以不使用。 -
forms.py
表单,用户在浏览器上输入数据提交,对数据的验证工作以及输入框的生成等工作,当然你也可以不使用。 -
templates 文件夹
-
views.py 中的函数渲染templates中的Html模板,得到动态内容的网页,当然可以用缓存来提高速度。
-
admin.py
后台,可以用很少量的代码就拥有一个强大的后台。 -
settings.py
Django 的设置,配置文件,比如 DEBUG 的开关,静态文件的位置等。
-
-
-
八、Python、JAVA
8-1 Python基础
- 1.copy和deepcopy
- 2.lambda
- 3.生成器、迭代器、装饰器
- 迭代器:可以使用 for 来循环遍历的对象。比如常见的 list、set和dict。
- 生成器:生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。它不需要再像上面的类一样写__iter__()和__next__()方法了,只需要一个yiled关键字。Python对协程的支持是通过generator实现的。
- 装饰器:装饰,顾名思义就是在原来的基础上进行美化及完善,器这里指函数,所以说装饰器就是装饰函数,也就是在不改变原来函数的代码及调用方式的前提下对原函数进行功能上的完善。其核心原理其实是利用闭包。装饰器
- 4.列表和元组
- 相同点:list 与 tuple 都是序列类型的容器对象,可以存放任何类型的数据、支持切片、迭代等操作;
- 不同点:
- tuple是不可变类型,大小固定,而 list 是可变类型、数据可以动态变化。
- tuple 用于存储异构(heterogeneous)数据,当做没有字段名的记录来用,比如用 tuple 来记录一个人的身高、体重、年龄,person = (“zhangsan”, 20, 180, 80)。list一般用于存储同构数据。
8-2 JAVA基础
-
九、深度学习框架,解析PyTorch, Tensorflow, Mxnet
-
十、2019 年“创青春·交子杯”新网银行高校金融科技挑战赛 (唇语识别, TOP 2.5%)
-
十一、2018 年之江杯全球人工智能大赛 视频识别 & 问答:TOP 1.3%
- 比赛描述: 本比赛属于 VisualQA 下的 VideoQA 方向,要求根据视频内容及提问预测回答。
- 解题思路: 使用 Bottom-up and Top-Down、Memory Networks 等模型提取视频与文本的联合特征并预测分类。
- 创新点:Attention 机制,先验掩码,信息融合。
- 细节:Co-Attention、Memory-Augmented Network、two-stream
-
十二、科研课题:Anchor-Free 在目标检测领域的应用
- 2020的一些前沿工作
- anchor free in segmentation
- PolarMask
- anchor free in segmentation
- 2020的一些前沿工作
-
十三、机器学习
-
1.聚类算法,
- k-means:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中。

- 对比高斯混合模型:GMM 和 k-means 很像,不过 GMM 是学习出一些概率密度函数来(所以 GMM 除了用在 clustering 上之外,还经常被用于 density estimation ),简单地说,k-means 的结果是每个数据点被分配到其中某一个 cluster 了,而 GMM 则给出这些数据点被分配到每个 cluster 的概率,又称作 soft assignment,也称为软聚类 。
- PCA:实现的两种方式,其中SVD的好处
- k-means:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中。
-
2.分类算法
核心的是随机森林,比如它属于集成模型,每颗树选取部分特征,类似于dropout
bagging与boast对比理解 -
逻辑回归与线性回归
- 逻辑斯蒂回归是一种对数线性模型。经典的逻辑斯蒂回归模型(LR)可以用来解决二分类问题,但是它输出的并不是确切类别,而是一个概率。
- 在分析LR原理之前,先分析一下线性回归。线性回归能将输入数据通过对各个维度的特征分配不同的权重来进行表征,使得所有特征协同作出最后的决策。但是,这种表征方式是对模型的一个拟合结果,不能直接用于分类。
- 在LR中,将线性回归的结果通过sigmod函数映射到0到1之间,映射的结果刚好可以看做是数据样本点属于某一类的概率,如果结果越接近0或者1,说明分类结果的可信度越高。这样做不仅应用了线性回归的优势来完成分类任务,而且分类的结果是0~1之间的概率,可以据此对数据分类的结果进行打分。对于线性不可分的数据,可以对非线性函数进行线性加权,得到一个不是超平面的分割面。
-
LR缺点和优点
- 优点:
1)预测结果是界于0和1之间的概率;
2)可以适用于连续性和类别性自变量;
3)容易使用和解释; - 缺点:
1)对模型中自变量多重共线性较为敏感,例如两个高度相关自变量同时放入模型,可能导致较弱的一个自变量回归符号不符合预期,符号被扭转。需要利用因子分析或者变量聚类分析等手段来选择代表性的自变量,以减少候选变量之间的相关性;
2)预测结果呈“S”型,因此从log(odds)向概率转化的过程是非线性的,在两端随着log(odds)值的变化,概率变化很小,边际值太小,slope太小,而中间概率的变化很大,很敏感。 导致很多区间的变量变化对目标概率的影响没有区分度,无法确定阀值。
- 优点:
-
svm
- SVM是一种二类分类模型。它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器。
- 硬间隔最大化(几何间隔)---学习的对偶问题---软间隔最大化(引入松弛变量)---非线性支持向量机(核技巧)
-
-
十四、深度学习中的经典模型
-
YOLOv3改进之处:
-
1.多尺度预测 (类FPN)
-
2.更好的基础分类网络(类ResNet)和分类器 darknet-53
-
3.分类器-类别预测:
-
-
YOLOv3 不使用 Softmax 对每个框进行分类,主要考虑因素有两个:
-
a.Softmax 使得每个框分配一个类别(得分最高的一个),而对于 Open Images这种数据集,目标可能有重叠的类别标签,因此 Softmax不适用于多标签分类。
-
b.Softmax 可被独立的多个 logistic 分类器替代,且准确率不会下降。
-
c.分类损失采用 binary cross-entropy loss.
-
-
-
十五、羊羊的面经,开始攒人品
思谋科技&直面
——2020.03.31 其实前几天拿到了澳大利亚很喜欢的暑研,所以面试的心态就变得超级无敌好。
面试官是华科的学长,知道种子班、知道刚哥,之前是白老师的学生,很舒服的一个学长。接到电话就开始问我的规划了,说对我的简历特别感兴趣,和我说了很多公司的情况,
(一)面试官的提问
- 介绍一下做过的项目
- 人脸的项目提问点:
- mimic:teacher是shufflenet,student是shuffernet v2的stage 5输出加一个卷积,之后把训好的teacher与student的stage5的输出做loss,回传整个网络。
- 项目中遇到的最难的问题:我说了thundernet的复现和数据集的一些处理
- 问了mmdet框架
- retinaface、centernet、thundernet等等的优化。
- 比赛
- 没怎么问,提了下arcface
- 后来成功把面试官的注意力转移到anchor free上
- anchor的优缺点
- 说一下自己的研究
- fcos和centernet有什么不同
- densenet 2015
- cornernet、Centernet(涉及的两篇最近两次面试都有提到)
- 最熟悉的框架
- 其他
- 这些东西没教过,你都是怎么学到(哈哈哈当然就是github大法)
- 种子班可以实习吗
- 怎么这么早就接触这些技术
(二)我的提问
- 公司有哪些部门
- 贾佳亚老师和公司是什么关系呢
- 有机会发论文吗
- 公司的专注点
- 哈哈反正正式面试前聊了很多,可能在家待太久了,所以被面试很开心
(三)答的不好的地方:
- focal loss:
- 我的原回答:解决样本不均衡的问题,根据样本数目调整权重,使网络对少量样本也保持注意力。
- 答:focal loss,这个损失函数是在标准交叉熵损失基础上修改得到的。这个函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。为了证明focal loss的有效性,作者设计了一个dense detector:RetinaNet,并且在训练时采用focal loss训练。实验证明RetinaNet不仅可以达到one-stage detector的速度,也能有two-stage detector的准确率(就是说样本数量少的类,只是难分类中的一个子集)。
- shufflenet的部署真的友好吗
- 因为我提到了优化centernet时,用了shufflenet做移动端部署的优化。
- 答:待完善

- mimic最后的效果
- 我只说了loss的改善12降到9,评估不够具体。
- 答:代填!
- OHEM
-
这是啥??看了答案突然想起来了,faster rcnn里边,好像在计算roi输出损失的时候有用到,我在做point link net的时候还写过代码的,听英文没反应过来太可惜了。
-
答:OHEM是CVPR2016的文章,它提出一种通过online hard example mining 算法训练Region-based Object Detectors,其优点:
- 1.对于数据的类别不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强。
- 2.当数据集增大,算法可以在原来基础上提升更大。当我们遇到数据集少,且目标检测positive proposal少时,一般实验效果会不如人意,可以试试OHEM这个trick,也许可以带来不错的效果。
此外,在fast rcnn中,作者将OHEM应用在Fast RCNN的网络结构,如下图。这里包含两个ROI network,上面一个ROI network是只读的,为所有的ROI在前向传递的时候分配空间。下面一个ROI network则同时为前向和后向分配空间。
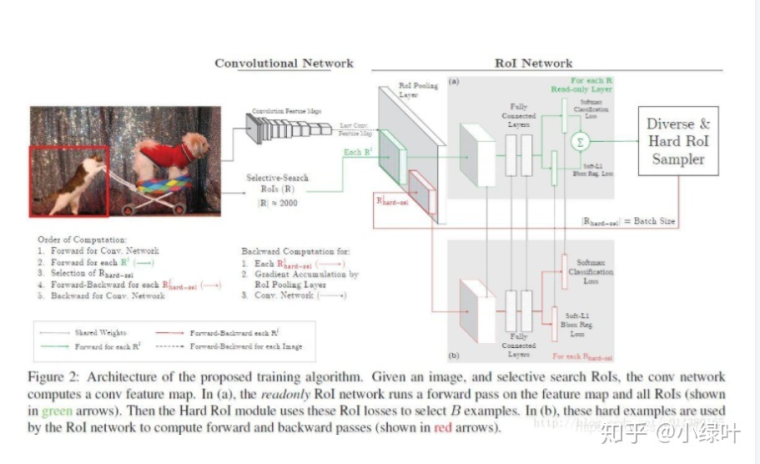
首先,ROI经过ROI plooling层生成feature map,然后进入只读的ROI network得到所有ROI的loss;然后是hard ROI sampler结构根据损失排序选出hard example,并把这些hard example作为下面那个ROI network的输入。
实际训练的时候,每个mini-batch包含N个图像,共|R|个ROI,也就是每张图像包含|R|/N个ROI。经过hard ROI sampler筛选后得到B个hard example。作者在文中采用N=2,|R|=4000,B=128。
-
(四)情商问题
虽然自己是想拿实习备用,但是不能被发现。想去做研究,也不能表现得太明显,毕竟是一个要谋生的公司。下次的话,可以说自己因为疫情和国际形势的一些原因,改变了出国的计划,想要毕业直接工作~(五)总结
其实主要也是想了解一下思谋科技和贾佳亚老师,才投了他们计算机视觉岗,据面试了解,他们专注于高清视频和工业检测。除了工业检测组之外,比较感兴趣的是他们的研究组,里边都是贾老师的phd,但是刘师兄说他们在创业初期,比较少招研究型实习生,噗,没错是因为缺卡。但是如果去的话,氛围应该很好,就相当于贾佳亚老师的学生都在那。过+1,面coding直接换了一个面试官,待更。-------------------------------------- 2020.04.02 更 ,已收offer---------------------------------------------------------
终面- 自我介绍
- 讲一下目标检测的发展
- bn与model.train()、model.eval()
- multi-scale在pytorch中的实现,涉及collate_fn
- gpu消费者、cpu生产者,如何调度
- 个人规划
其他笔试题单独列在下边的了,两个面试官真的都超级好的。概括来说,这个初创公司给我感觉是:这是一个很敏捷的团队!
-
十六、商汤面试准备
(一)了解面试官
开始谷歌:

- 说明面试官会很关注感受野的计算,从这一方面节约开销。

- 重视训练优化,很可能问到简历里的TTFNet中的高斯采样的训练优化。
- 我去,有点厉害的,一年高产5篇,两篇1作。

- 重点看了一下第四篇,解决的是一个不对齐的问题(misalignment between anchor boxes and convolutional features)。
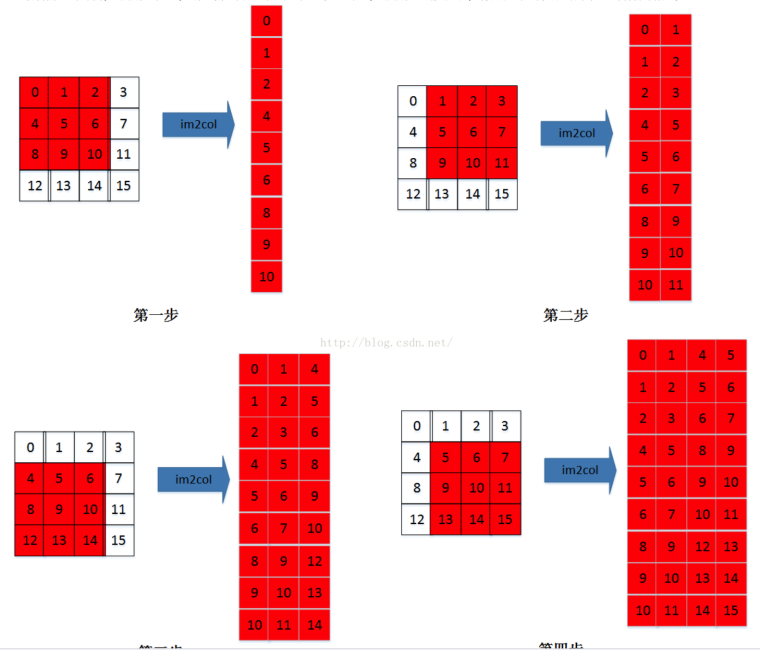
- 提到了 im2col operator(咦,这个不是mxnet里边,转格式的东西吗,好奇怪),RoIAlign operator(惨了,这个肯定会问的)。
- 查了一下,2019 谷歌研究院提出间接卷积算法:一种更省内存的卷积运算实现方案。im2col的作用是优化卷积,把卷积的摊开。我们把一个卷积核对应的值展开,到底应该展开为行还是列呢?卷积核的滑动先行后列还是相反?区别在哪?这其实主要取决于我们使用的框架访存的方式。计算机一次性读取相近的内存是最快的,尤其是当需要把数据送到GPU去计算的时候,这样可以节省访存的时间,以达到加速的目的。不同框架的访存机制不一样,所以会有行列相反这样的区别。在caffe框架下,im2col是将一个小窗的值展开为一行,而在matlab中则展开为列(学到了!)。所以说,行列的问题没有本质区别,目的都是为了在计算时读取连续的内存。
(二)复习一下比赛的一些细节
(三)准备两篇前沿的论文笔记
- 使用向心偏移来对同一实例中的角点进行配对的CentripetalNet向心网络(2020 cvpr)知乎笔记
- 向心网络可以预测角点的位置和向心偏移,并匹配移动结果对齐的角。结合位置信息,这种方法比传统的嵌入方法更准确地匹配角点。角池将边界框内的信息提取到边界上。
- 交叉星可变形卷积网络来适应特征,为了使这些信息在角落里更容易被察觉。
(四)修改自我介绍,特别是加入anchor free的技术细节,引导面试官。
(五)项目重点复习
-----------------------------------------------------2020.04.03 更商汤一面 ---------------------------------------------------------
- coding
- 二分查找的两种写法
- 自测测试用例,自动生成测试用例
- 操作系统
- 查找涉及的数据结构
- 子进程、父进程、fork函数
- 进程间通信,如多gpu上的gradient是如何共享的
- 进程有哪些可观测到的状态
(没准备操作系统这一块,大坑要填!)
-
十七、目标检测中的一些细节总结
-
十八、python攻克算法题的一些总结
一刷了剑指offer,趁写总结再复习一遍。
(一)链表与指针
二个指针的题:字符串替换空格、
四个指针:%k 的反转链表
易出错:1、变化前后要考虑指针原始值是会发生改变的,注意逻辑(二)斐波那契数列
注意优化
(三)二叉树
主要是对递归思想的熟练运行
3.1
#树的深度
def TreeDeep(self, pRoot):
if not pRoot:
return 0
left = self.TreeDeep(pRoot.left)
right = self.TreeDeep(pRoot.right)
return left+1 if left>right else right+1注:会扩展到平衡树,如果直接遍历求深度会超时
3.2 翻转
注意不要设计带return值的递归函数,在外部交换左右节点,而是在设计方法,在内部交换。(不好表述,见谅可跳过)
(四)面试经历过的一些算法题
这里是一个大漏洞,满满填补吧~
- 思谋科技(已收offer)
- 计算iou
- 开根号的计算
- 二分、注意考虑大于一与小于一的情况
- 商汤()
(五)DP
(终)Tip
-简化temp,多行变一行

- 优先队列调用
from Queue import PriorityQueue
q = PriorityQueue()
q.put((m, n))
m_, n_ = q.get() #按m_最小的取出---------------------------- 拿了三个offer然后这个帖子就木有更新啦 --------------------
- 思谋科技(已收offer)