基于MCTS和神经网络的AI五子棋
-
本次分享我们聚焦基于MCTS和神经网络实现AI五子棋算法。本算法就是AlphaZero的核心算法。
Alpha系列

2016年,AlphaGo一举击败围棋世界冠军李世石,让全世界都为之一振。此后掀起人工智能的热潮和一波关于人工智能的讨论。当时AlphaGo是通过学习人类历史上的棋谱从而不断学习成为围棋大师。可是令人出乎意料的是一年后,2017年,AlphaGo Zero在完全不依靠人类知识的前提下,从零开始从一个围棋小白开始,自我对局不断学习,竟然在3天内以100:0的战绩战胜AlphaGo。同年12月,AlphaZero诞生,这是AlphaGo Zero的升级版,同样不借助人类历史棋谱和经验,仅仅通过自身学习即可以在短时间内,在围棋、将棋、国际象棋等多种棋类中达到世界顶级水平。
而AlphaZero使用的就是MCTS和神经网络结合的算法。MCTS
MCTS是蒙特卡洛树搜索。MCTS有传统的版本,同时针对AI五子棋进行了一部分的改进。
传统MCTS
传统MCTS分为四个部分:选择,扩展,仿真,反向传播。
MCTS流程图
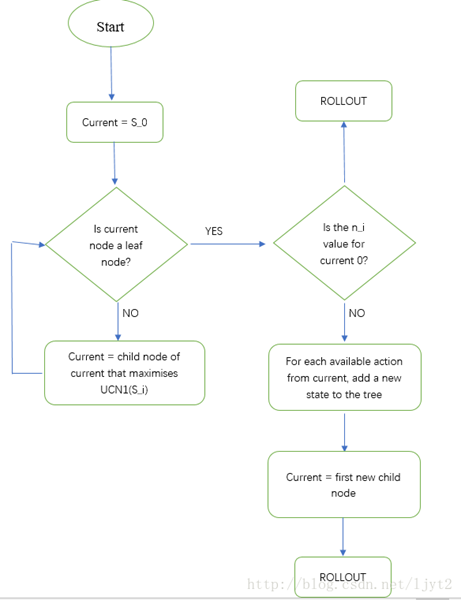
(原图出处:https://blog.csdn.net/qq_16137569/article/details/83543641)
由于不是本次分享的重点因此略过。此处给出传统MCTS的详细介绍链接。
https://blog.csdn.net/ljyt2/article/details/78332802改进MCTS及应用
去除Rollout
我们知道,传统MCTS的rollout就是一种玄学措施,如果对于井字棋这样落子次数有限的棋类而言,随机落子尚可实现。但是像围棋、五子棋等等,随机落子分出胜负的方案实在是不太可行。而我们知道,rollout的意义就在于给出一个节点的value值。因此我们最终选择用神经网络给出value值,以取代rollout。
修改UCB公式
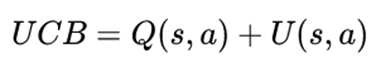
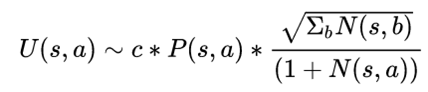
- Q即平均value,由神经网络给出
- P即落子概率,,由神经网络给出
- c是一个用于调节置信度和探索度平衡的超参数
- N是该节点的探索次数
在这里我们看到,有了神经网络的加持,MCTS在计算UCB式子的时候可以对一个节点进行更好的Q值和P值的估测,一方面省去了rollout的玄学打分,另一方面对于神经网络计算得出来的概率大的棋子有优先仿真的权力。
应用
首先注意,我们现在处在测试阶段,也就是说神经网络的训练已经结束,现在我们处于人机对战的阶段。
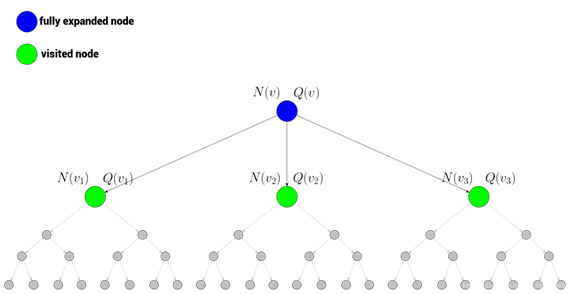
我们假设现在处于根节点的局面,即图中蓝色节点处。此时我们有下方三个子节点(原则上子节点的个数是棋盘上所有可落子位置和),现在我们进入第一步仿真。- 仿真
在仿真的过程中,每次调用UCB公式,选择UCB最大的节点。如果当前节点未被选择过,则由神经网络给出value,如果当前节点已经被访问过,则此节点扩展,扩展之后继续由神经网络给出value。所有给出的vlaue值都会叠加到父辈身上,同时每一次迭代之后自己和父辈的访问次数加一。当仿真次数达到限制或者计算要求时间到时,仿真停止。
- 落子
此时选择要真实落子的位置。本次选择与UCB公式无关。在根节点的三个子节点中,选择访问次数最多的节点作为真正落子的节点。这是一种把频率当做概率的想法,访问的频率越大代表赢的概率越大。
这就是MCTS在测试中所实现的方案。
策略价值神经网络
棋局输入
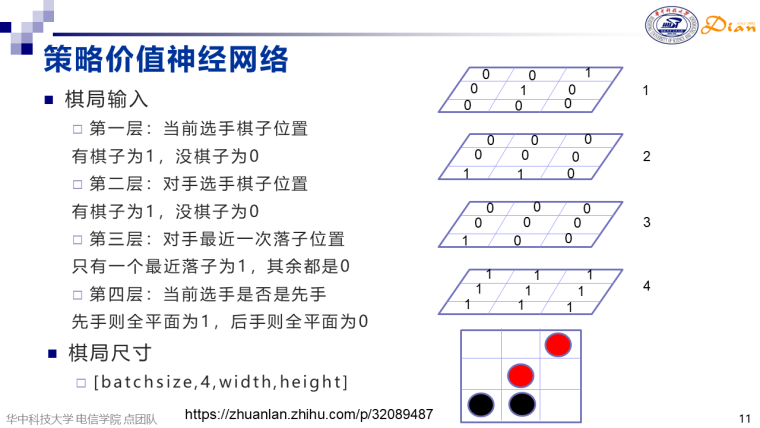
在棋局输入的时候把当前棋局进行一个四通道的扩展,分别为当前选手棋子位置、对手选手棋子位置、对手最近一次落子位置和当前选手是否是先手。如果batch_size是1,棋盘大小是15*15,那么棋局信息输入维度为[1,4,15,15]。把棋局分为四通道主要是因为我们落子位置大概率会在对手最后一次落子位置的附近,同时先后手也是非常重要的。网络结构
网络结构分为两个部分,策略网络部分和价值网络部分。
策略网络
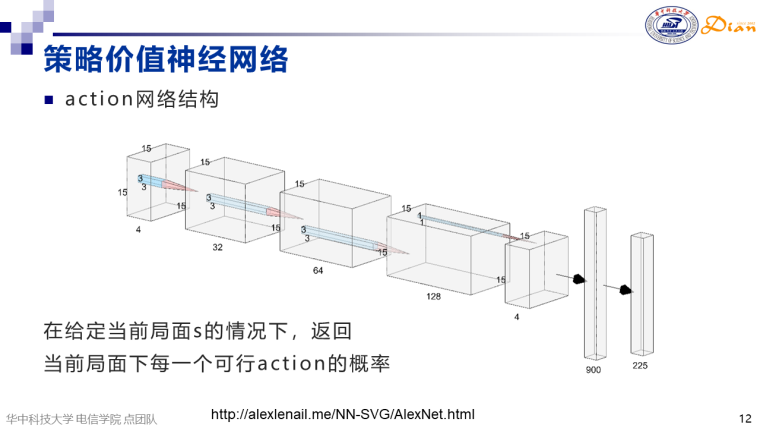
在策略网络中,棋局[1,4,15,15]先后通过三个通道为32、64、128,尺寸为3*3的卷积层,然后通过一个通道为4,尺寸为1*1的卷积层,接下来接一个全连接层实现900到225的变换。其中225代表15*15也就是说棋盘上每一个位置可能落子的概率probs都计算出来,结果保存在[1,225]维的一个向量中。价值网络
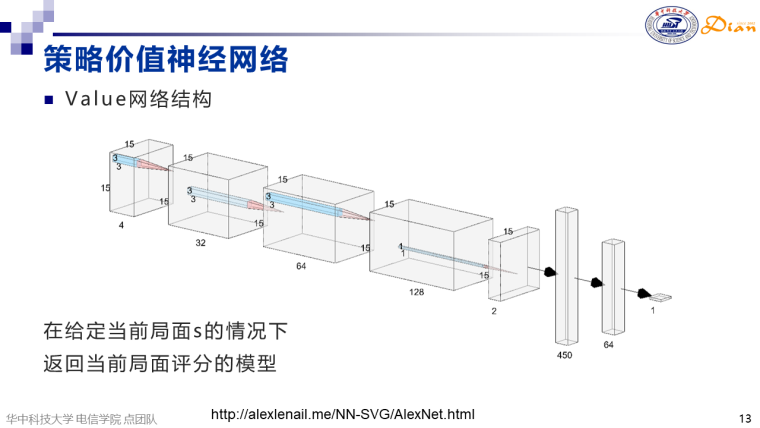
与策略网络前端类似,棋局[1,4,15,15]先后通过三个通道为32、64、128,尺寸为3*3的卷积层,然后通过一个通道为2,尺寸为1*1的卷积层,接下来通过两个全连接层实现450维向量到1维向量的映射。其中1维即当前落子之后的局面评分value。测试方案
在上述probs和value的共同作用下计算UCB值,从而完成对MCTS选择过程的优化。原则上MCTS在神经网络的帮助下能够更好地选择落子位置(还是先仿真选择UCB值高的多此访问,在落子阶段选择访问次数多的进行真正落子)。
训练方案
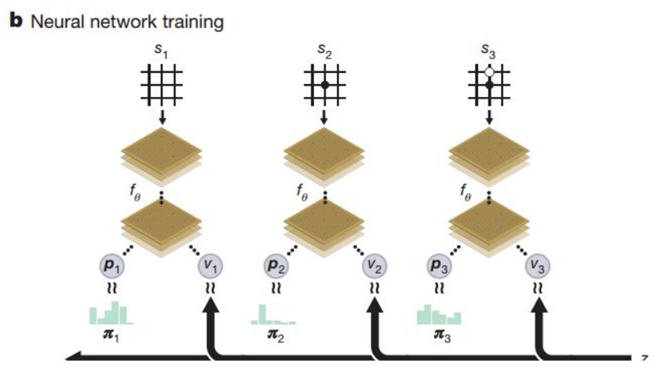
(原图来源:https://zhuanlan.zhihu.com/p/32089487)要注意,我们之前一直在讲的是测试方案,比如人和电脑对战,也就是神经网络通过给出probs和value影响UCB值从而影响MCTS仿真。而接下来我们要将神经网络如何训练。
self-play数据来源
训练的数据来源是self-play的棋局。我们假设现在AI自己和自己下了一局并且分出胜负,我们假设一共下了10步棋,最后黑棋胜利,红旗失败,现在我们把这10步棋的历史记录一一切片拿出来,也就是说每一步代表一个棋局可供神经网络学习。我们给出的数据结构为[S,pi,z]。
-
S代表当前棋局形式,即按照最上面网络输入格式的方式形成一个[batch_size,4,width,height]的输入模型。
-
pi代表棋盘上每一个点的落子概率,这个概率是由MCTS在self-play进行中给出的,当时把这个pi值保存下来
-
z代表棋局胜利与否,针对本期局玩家身份而言。如上所述,如果本期局落子玩家是黑棋,那么z取1;如果是红旗,那么z取-1。
同时我们将S输入到神经网络中,神经网络给出probs(记作p)和value(记作v)。
Loss函数
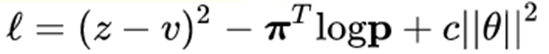
我们来理解一下这个损失函数。首先第一项z和v的均方差误差,我们希望神经网络能在给出一个棋局的情况下尽可能地给出正确的胜利或者失败的值。可以想象,如果这个值足够正确,那么我们在测试阶段进行预测的时候,落一个字就能一清二楚地判断棋局最后是胜是负,从而给出一个合理的value去决定这个落子位置的价值。
第二项是p和pi的交叉熵。当p和pi越接近,l的值就越小,模型就越好。理解的方法是,我们在仿真的时候会给出p值,p值越大则我们去访问的概率就越大,最后我们选择落子的概率就越大。我们知道,pi是MCTS在一系列的仿真之后选择出来的最优解,如果p和这个值接近那么我们就可以直接选择最优解而不用绕弯路。我们可以想象,当我们在回顾的过程中计算出来一个落子概率分布p,而真实的pi则和p很接近,也就是说我们走了最应该走的道路,从而l的值就很小。反过来说,当我们的模型足够优秀的时候,我们应该可以直接给出落子最优解,因为从“未来”的角度看,我一定会选择这种落子方案。
第三项是一个L2惩罚项,防止过拟合。
总而言之,第一项是希望神经网络能够在已知棋局的条件下给出最精确的胜或者负的值,作为value。在仿真阶段往往都是先模拟下了这个节点对应的落子,然后再根据新的棋局进行一个评估,以此作为此位置落子的value值。第二项则是以一种“超预测”的方案直接给出落子概率,我们走最优解道路。
这就是整个神经网络训练的原理。
MCTS和神经网络结合流程
测试阶段
在MCTS进行仿真的时候,先选定一个节点,把新棋局输入神经网络,由神经网络给出全局落子概率和新棋局的棋局评估,从而影响UCB公式的值。MCTS选择UCB高的节点,UCB高的节点访问次数就越多。在真正落子阶段,MCTS选择根节点子类中访问频率最大的节点作为最终落子的节点。
训练阶段
AI先进行一段时间的self-play以获得训练数据。对于每一局self-play都以步为单位切片形成不同棋局。每一步历史棋局都保存为[S,pi,z]格式,其中pi和z都已经是确定值。针对每一个棋局由神经网络重新计算得到p和v,优化的意义在于让p趋近于pi,让v趋近于z。这是因为让p趋近于pi可以在测试阶段让MCTS一开始就选择最好的节点而不用绕路,让v趋近于z可以在测试阶段让MCTS对棋局评估更加准确,对于每一步的后果更加清楚。
完!
参考文献
-
https://zh.wikipedia.org/wiki/%E8%92%99%E7%89%B9%E5%8D%A1%E6%B4%9B%E6%A0%91%E6%90%9C%E7%B4%A2
-
https://blog.csdn.net/ljyt2/article/details/78332802
-
https://zhuanlan.zhihu.com/p/59567014
-
https://zhuanlan.zhihu.com/p/32089487
-
http://alexlenail.me/NN-SVG/AlexNet.html
-
https://blog.csdn.net/ljyt2/article/details/78332802
-
https://blog.csdn.net/qq_16137569/article/details/83543641