CenterNet(ctdet)学习笔记
-
自己的理解啦,先列参考吧,感觉参考比我的有价值
参考:
centerNet特别好的一篇解读
高斯半径理解
高斯半径代码存在的一个问题
focal loss实现的要点我一开始是写在石墨,可以用石墨看着比较舒服一点
https://shimo.im/docs/gGkQgv9JRQgqd89y/ 《CenterNet(ctdet)学习笔记》
-
Anchor Box缺点
(1)Anchor的设置需要手动去设计,对不同数据集也需要不同的设计,相当麻烦;
(2)anchor的生成是预先设定好的,对于较大或者较小的目标检测效果较差。
(3)Anchor的数量过多使得存在严重的样本不平衡问题。
(4)训练时需要计算anchor和真实框的IoU,占用大量内存和时间论文创新点
- “anchor”只考虑位置,没有尺寸框,不用手动分前后景
- 每个目标只有一个正“anchor”,不用NMS
- 仅缩放4倍,采用了更大分辨率的feature map
- 对于关键点,只考虑左上右下这两个点
模型
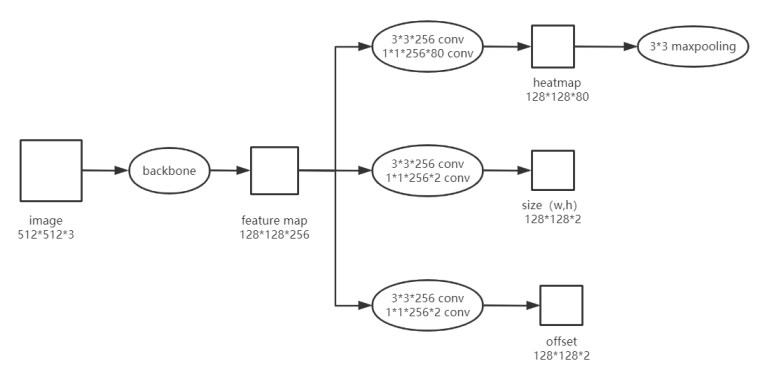
-
★heatmap
centerNet的heatmap应该是跟cornetNet的生成方式是差不多一样的.
这张图来自cornerNet,可以看到左上右下两点在一定半径内的生成的预测框和真实框的IoU是很大的,所以在设置heatmap时,直接将距离GT左上右下两点很近的点设置为0太绝对了,所以采用二维高斯核和设置IuO用一种温和的方式过度一下比较好。

论文里的一些表示
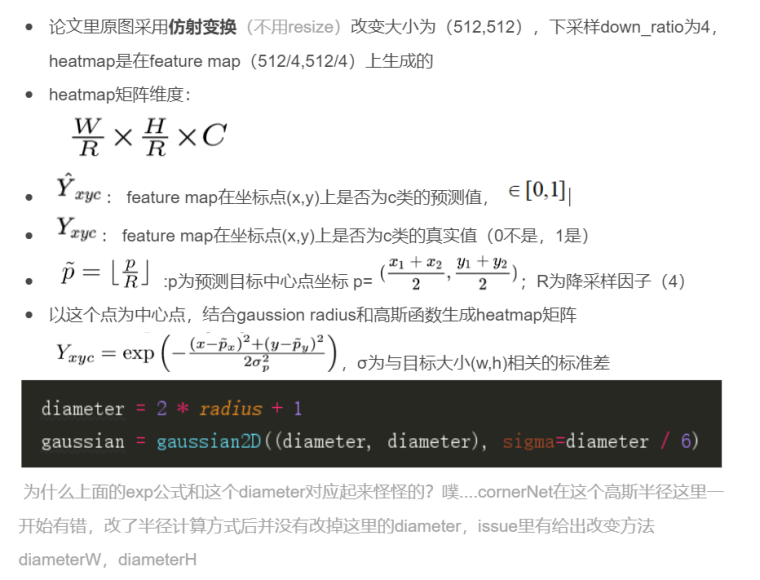
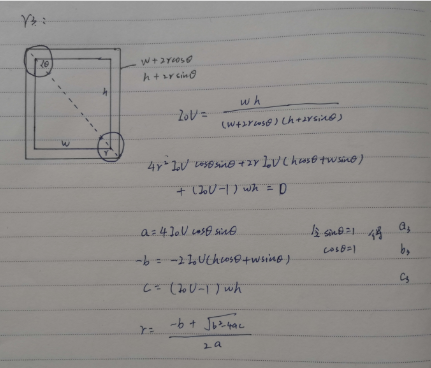
高斯半径生成(corner net)
代码来自corner net

r1,r2,r3来自三种可能的预测框和GT的覆盖方式


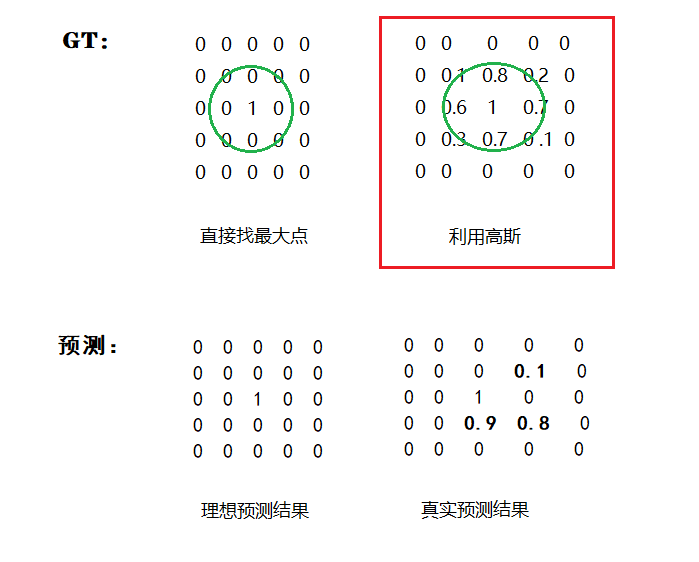
高斯核生成heatmap

简单矩阵描述一下,也方便后面loss理解
点变框(detector)
-
网络的输出结果是对每个预测坐标点有 class_num + 4(w,h,offset_x,offset_y)个值
-
总是要有个操作来代替nms的作用,对heatmap选取某个点的值比周围8个点值都大或等于的点(3*3 max pooling),然后score排序 不考虑类别(? )响取top-100

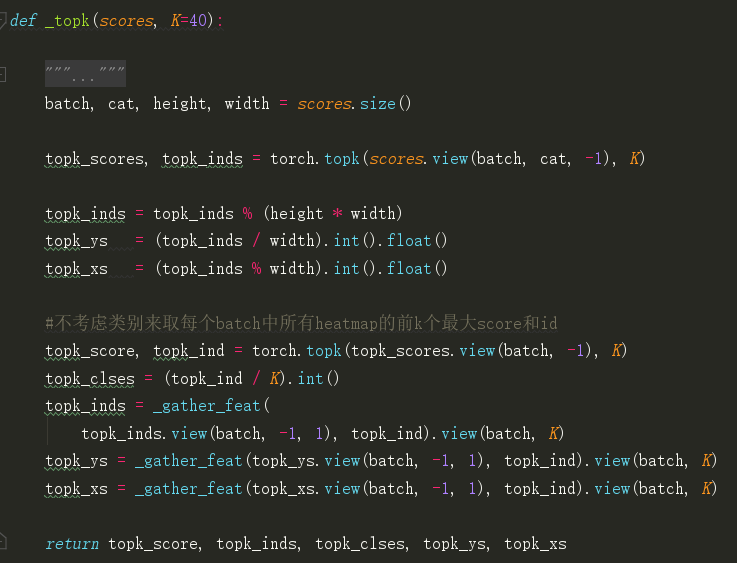


-
-
LOSS

OHME
仅将损失较大的部分反传,直接忽略简单样本损失
例:同一样本不同关键点的loss,排序,对其top-k的loss进行再训练Focal loss
二分类交叉熵
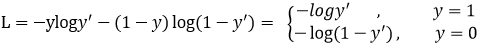
Focal loss
相当于加权重
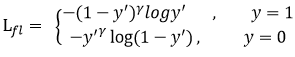
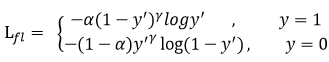
heatmap loss(目标中心点损失)
在focal loss结合实际做的改变
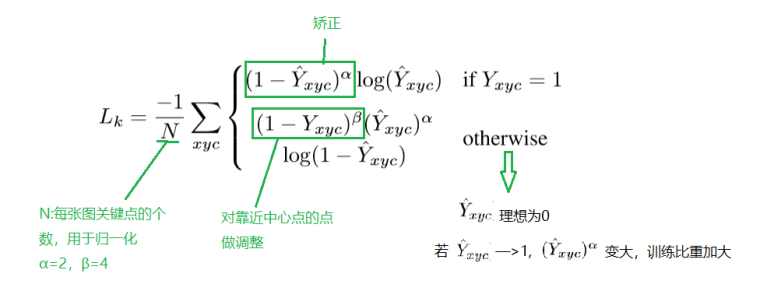
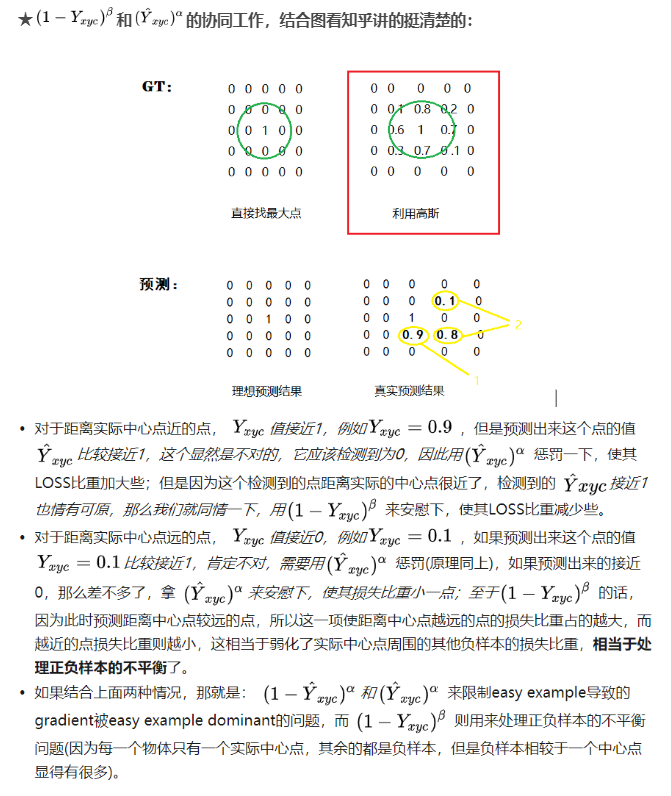
★实现focal loss的几个关键点
- 正确的公式
- 要有sigmoid确保数值稳定
- 输出层要设置正确的bias
size loss
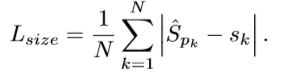
offset loss

-
结果

-
有太多图片放上来都说太大了。。。我就直接截图了
 ,然后截取的部分就越来越多,CV方向论文前沿变化太快了,但是经典还是经典,值得多次理解的!
,然后截取的部分就越来越多,CV方向论文前沿变化太快了,但是经典还是经典,值得多次理解的!
-
focal loss的bias的点在它的论文(RetinaNet)中有说:


