强化学习 学习心得(2)
-
PG
从这里开始就与上面的value-based方法不一样了,value-based方法最后输出的action的一个Q表,policy-based方法输出的直接是一个动作,而且还可以在连续的分布上选取动作。PG是回合更新的。采取随机性策略:
,其中 是产生随机性动作的策略网络的参数 .
$$
\theta \leftarrow \theta+\alpha \nabla_{\theta} \log \pi_{\theta}\left(s_{t}, a_{t}\right) v_{t}\
\theta就是GD网络的参数\
这样可能看的懂一些:\theta \leftarrow \theta+\alpha \nabla_{\theta} \log p_{\theta}\left(s_{t}, a_{t}\right) r_{t}\
p就是概率,r_t就是reward \
loss = \frac{1}{N} \sum r*\log p
$$下一步a根据最后的概率来选择
关于代码中的一些问题:
-
PG算法中间有一个预测动作的神经网络,最后输出的张量的shape:[None,n_actions],然后再求这个预测值与现实中的动作的cross-entropy误差
公式:
$$H_{y^{\prime}}(y)=-\sum_{i} y_{i}^{\prime} \log \left(y_{i}\right) ;y_i是预测值,y_i'是真实值$$ (最大化r*logp就是最小化—r*logp)。因为强化学习中现实的动作并不一定都是正确的,所以后面还要乘以每一回合reward用来更正预测。<u>如果不用cross-entropy来计算误差,能否不用log?</u> 这里的loss函数是为了配合policy gradient ,因为输出是概率,所以 需要一个概率之间进行比较的函数,选择了cross entropy。莫烦老师代码中的实现是用的tf.nn.sparse_softmax_cross_entropy_with_logits,这个函数包含了“-” 号。
这里也可以从优化的角度思考,loss =-log(p)*r, p和r都是向量,如果如果p小,则-log(p) 大,r大则loss 更大。r的值和p的值没有关系,所以为了让loss小,只能让r最大的位置的p最大,即收益最大的位置的概率最大
这个地方看了台大李宏毅老师的讲解之后,我发现这个地方的log是直接算出来的:这个地方就和莫烦老师的想法不是很一样。
$$
\bar{R}{\theta}=\sum{\tau} R(\tau) p_{\theta}(\tau)\
\nabla \bar{R}{\theta}=\sum{\tau} R(\tau) \nabla p_{\theta}(\tau)=\sum_{\tau} R(\tau) p_{\theta}(\tau) \frac{\nabla p_{\theta}(\tau)}{p_{\theta}(\tau)}\
=\sum_{\tau}R(\tau)p_{\theta}(\tau) \nabla \log p_{\theta}(\tau)\
#依据是:\nabla f(x)=f(x) \nabla logf(x)\
=E_{\tau \sim p_{\theta}(\tau)}\left[R(\tau) \nabla \log p_{\theta}(\tau)\right] \approx \frac{1}{N} \sum_{n=1} R\left(\tau^{n}\right) \nabla \log p_{\theta}\left(\tau^{n}\right)=\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_{n}} R\left(\tau^{n}\right) \nabla \log p_{\theta}\left(a_{t}^{n} | s_{t}^{n}\right)
$$ -
关于每一回合的reward,最后的reward是一个list,通过归一化,我们可以看到每一回合的reward使如何变化的。对于CartPole-v0的第一回合,图如下:
这只是第一回合的reward,不是全部回合的reward,可以看到前面的reward很大,说明前面的行为要重视,后面的reward很小(杆子要掉下来了),所以后面的行为要惩罚。
对于MountainCar-v0的第30回合的图如下:
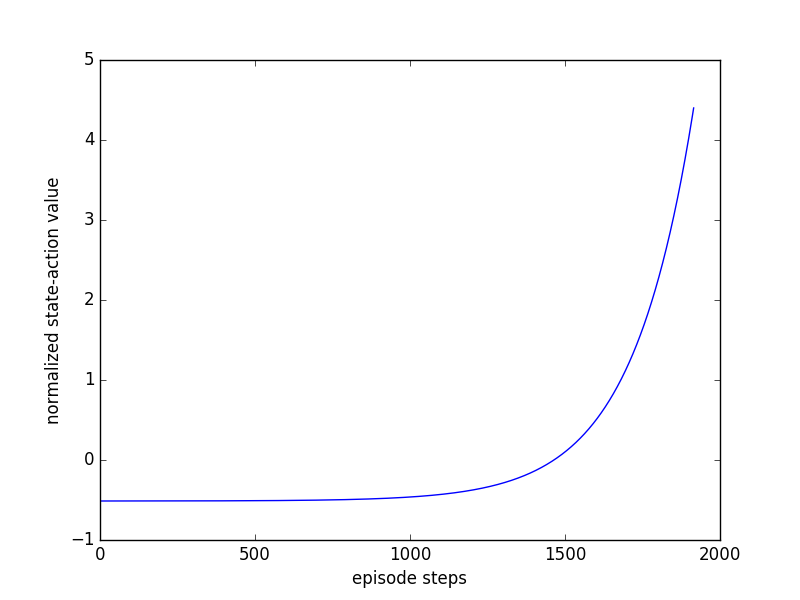
这是第30回合的reward,不是整个回合的reward,可以看到通过前29轮的训练,在第30轮,小车已经可以到达终点了,所以后面的行为要重视。
<u>这里有一个问题,每一回合所有的reward都经过了衰减的处理,而且是倒序的衰减处理,第一个reward反而衰减越小,这个的意思是每一回合的reward都与最后一个reward关系最大,同时考虑之前reward的影响吗?</u>
reward的衰减是与游戏本身有关系的:
如果是目标到达类的游戏,比如到达某个点才有最大的收益,我们会用这种在最终才有较大收益的曲线
如果是保持状态类的,在保持状态的初期有较大的收益,但是偏离了状态,则收益大幅下降。
当然在李宏毅教授的课件当中还提到了一个叫做baseline的东西,用于对reward都为正数的游戏,在这种情况下,我们将简单的
变成 , 可以用 来代替。让reward也有负的时候,这样的好处我在这个地方不知道如何描述,具体可看李宏毅教授课件中的讲解( https://www.bilibili.com/video/BV1iE411e7KQ?p=1 ),这样有正有负的reward对训练也很有帮助!在莫烦老师代码中我还看到一种方法就是对reward归一化,我觉得这样也可以! 还有一个地方就是在上面的
也可以变化为 的样子,前面的 就是一个小于1的衰减系数, 就是一个从当前开始到最后的一个reward。当然这个地方我也有点奇怪,啥从当前开始到最后的reward,后来我想了一下,n就是一回合中总的步数, 就是所有的回合数,这样就是指当前这个回合中所有的reward的和,这样就和莫烦老师代码中的含义一样了。 还有一个地方就是关于cross_entrop的地方,这个交叉熵到底做了什么,为什么里面会用到one-hot编码,最后的为什么只有logp,而不是qlogp这样的交叉熵的形式。
AC
AC算法也是一个很重要的算法,后面的ddpg,dppo,a3c等算法都与它有关。Actor就是PG算法,Critic就是评判函数。AC是单步更新的。(有人说:AC就是PG加Q-learning)
Actor中与PG不一样的地方就是,用现实和估计的差距(TD error)代替了原来的一回合的reward,Actor网络输出的是所有动作的概率值。
这里的td_error就是A 优势函数,那么什么是优势函数?
优势函数表达在状态s下,某动作a相对于平均而言的优势。
从数量关系来看,就是随机变量相对均值的偏差。
使用优势函数是深度强化学习极其重要的一种策略,尤其对于基于policy的学习。TD error:
,v就是在s下得到的value(相当于q值吧),v和v_都由由Critic得到。 因为不是回合更新的,所以用
$$
loss= \log p_{\theta}\left(s_{t}, a_{t}\right) td_error\
\theta \leftarrow \theta+\alpha \left(R_{t+1}+\gamma \hat{v}\left(S_{t+1}\right)-\hat{v}\left(S_{t}\right)\right) \nabla_{\theta} \log \pi\left(A_{t} \mid S_{t}, \theta\right)
$$
的时候p概率只是针对单次的state做出的action的概率,action根据概率随机选择选择得到的。要求loss的最大值,就是求—loss的最小值。(actor的loss和PG算法的loss非常相似,可以看到,这里就是把PG中的V换成了td_error。负号也是和PG一模一样)Critic的
,Critic的作用就是计算v_和优化前面的loss。优化loss部分和之前的DQN类似哎。Critic网络输出的是s的v值。<u>这个网络中状态s的价值和DQN中q值有什么不同?</u> AC的特点就是有两个网络分别学习,一般情况下,会要求A的学习率大于C的学习率,这里的目的是让A对于动作的更新更准确
这里的V值和Q值,其实没什么区别,这里的critic网络就是直接对Q值的直接估计
<u>前面的DQN,GD,AC网络最后的reward值是:_reward * 0.95 + ep_rs_sum * 0.05,想知道为什么是这个样子?</u>
首先,这个曲线是一个指数衰减的曲线,比较平滑,一般这样做的目的是为了平滑曲线
另外这里的running reward 你是否指的是:
ep_rs_sum = sum(RL.ep_rs) if 'running_reward' not in globals(): running_reward = ep_rs_sum else: running_reward = running_reward * 0.99 + ep_rs_sum * 0.01 if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering print("episode:", i_episode, " reward:", int(running_reward)) # 这段代码的目的是评估当前的学习器是否达到了一个比较好的水平,如果达到了,则可以进行render 渲染,就是把图像打印出来,因为打印图像一般比较耗时 # 使用running_reward是因为进行了平滑之前的曲线,可能有部分步达到了比较好的水平,但是是炸胡,平滑保证能持续达到比较好的水平才进行渲染和打印数值Actor Critic优点:可以进行单步更新, 相较于传统的PG回合更新要快.
Actor Critic缺点:Actor的行为取决于 Critic 的Value,但是因为 Critic本身就很难收敛和actor一起更新的话就更难收敛了。(为了解决收敛问题, Deepmind 提出了 Actor Critic 升级版 Deep Deterministic Policy Gradient,后者融合了 DQN 的优势, 解决了收敛难的问题)。下面提到的A3C也是早期对AC算法的优化,也有很多值得我们学习的地方。A3C
Asynchronous Advantage Actor-critic 异步优势 AC算法
相比Actor-Critic,A3C的优化主要有3点,分别是异步训练框架,网络结构优化,Critic评估点的优化。其中异步训练框架是最大的优化。
下面是A3C的框架,可见global network的下面有很多的小网络,这就是异步。公共部分的网络模型就是我们要学习的模型,而线程里的网络模型主要是用于和环境交互使用的
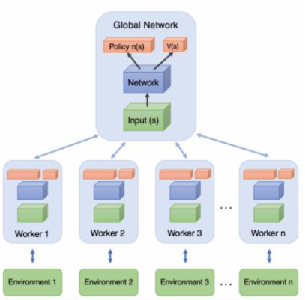
关于第二个优化,网络结构的优化。之前在 Actor-Critic中,我们使用了两个不同的网络Actor和Critic。在A3C这里,我们把两个网络放到了一起,即输入状态SS,可以输出状态价值VV,和对应的策略ππ, 当然,我们仍然可以把Actor和Critic看做独立的两块,分别处理
第三个优化是Critic评估点的优化。原来AC算法的优势函数(就是td_error)是
在A3C中,采用了N步采样来加速收敛,优势函数是:
于Actor和Critic的损失函数部分,和Actor-Critic基本相同。有一个小的优化点就是在Actor-Critic策略函数的损失函数中,加入了策略π的熵项(这不是和SAC想法一样了吗),系数为c, 即策略参数的梯度更新和Actor-Critic相比变成了这样:

这个A3C论文里面还有涉及了很多的其他要点,我觉得很有意思,来说一下。
-
我们所说的policy-based和value-based其实是有算法基础依据的。他们统统归纳与policy-gradient methods 和 action-value methods中。
我们把去估计动作值函数(action-value)然后利用其进行决策的方法叫做action-value methods
而把将策略参数化,并且每次依照当前策略参数和环境反馈,去更新参数的方法叫做policy-gradient methods,一种常见的更新方法就是策略梯度上升(gradient ascent)。
-
我们来说说policy-gradient methods的目标函数,policy-method就是根据目标函数对策略参数的导数进行优化的。
通常我们定义的目标函数是:
它的导数就是:所有a和所有s的组合
$$
\nabla J(\theta)=\sum_{s} \mu_{\pi}(s) \sum_{a} q_{\pi}(s, a) \nabla_{\theta} \pi(a \mid s, \theta)\
\text { 其中 } \mu_{\pi}(s) \text { 是值在策略 } \pi \text { 下任意时间 } t \text { 状态 } s \text { 的出现的期望 }
$$
然后我们就可以对上面的公式进行简化:
$$
对于某一个episode:\nabla J(\theta)=E_{\pi}\left[\sum_{a} q_{\pi}\left(S_{t}, a\right) \nabla_{\theta} \pi\left(a \mid S_{t}, \theta\right)\right] \
\nabla \log (f(\theta)) * f(\theta)=\nabla f(\theta)\
\nabla J(\theta)=E_{\pi}\left[q_{\pi}\left(S_{t}, A_{t}\right) \nabla_{\theta} \log \pi\left(A_{t} \mid S_{t}, \theta\right)\right]\
\theta \leftarrow \theta+\alpha \gamma^{t} q_{\pi}\left(S_{t}, A_{t}\right) \nabla_{\theta} \log \pi\left(A_{t} \mid S_{t}, \theta\right)
$$
式子中的q_{\pi}(S_t,A_t)的不同改进形成了各种的算法 -
对于REINFORCE算法就是policy-gradient methods下的一个具体的算法:
每次取样一个回合(MC算法)对参数进行更新,q(s,a)函数变为:
$$
G_{t}=\sum_{k=t+1}^{T} \gamma^{k-t} R_{k}\
\theta \leftarrow \theta+\alpha \gamma^{t} G_{t} \nabla_{\theta} \log \pi\left(A_{t} \mid S_{t}, \theta\right)
$$
REINFORCE还有扩展方法:REINFORCE with baseline
利用了等式:
这样可以在q(s,a)后面减去任意的与动作a无关的项b(s),这样可以减少算法的方差(variance)
我们可以看到,这里用的都是回合的更新,所以REINFORCE用的是MC的思想,如果改用TD的思想的话,我们就得到了AC算法。将REINFORCE中更新时使用的Gt 改为
$$
R_{t+1}+\gamma \hat{v}\left(S_{t+1}\right)-b\left(S_{t}\right)\
\text { 其中 } \hat{v}(s) \text { 是我们对状态值函数的估计,一般我们可以直接用 } \hat{v}\left(S_{t}\right) \text { 来确定 } b\left(S_{t}\right) \
\theta \leftarrow \theta+\alpha \gamma^{t}\left(R_{t+1}+\gamma \hat{v}\left(S_{t+1}\right)-\hat{v}\left(S_{t}\right)\right) \nabla_{\theta} \log \pi\left(A_{t} \mid S_{t}, \theta\right)
$$为什么减去一个b,就会减少方差呢??
-
强化学习的很多算法都是向前看的算法,即当前状态或动作的价值更新是依赖于未来状态或动作的,这样的算法称为forward view (前向视角)。前向视角实施起来多少有些不方便,毕竟未来的事,当前并知道。还有另外一种思路是所谓的backward view (后向视角),通过eligibility trace来考虑最近刚刚访问过的状态或动作。
-
熵正则化?
这到底是什么东西,我知道熵,交叉熵,相对熵,怎么不知道这个熵正则化?
看名字就知道,这个就是熵作为后面的正则化项了。那什么又是正则化?那就要你自己去了解之间的基础知识了。
-