Deep Pyramid Convolutional Neural Networks for Text Categorization论文笔记
-
概述
关于nlp的文本分类,textCNN是一个非常棒的模型,但是textCNN的本质还是词袋的模型,小瑶(夕小瑶的卖萌屋)总结说,textCNN较之前模型的收益来源于textCNN对词进行了embedding,这使得能够学习出词之前的近语义关系。那么问题来了,我们能否通过卷积获得长距离的关系呢,本文DPCNN给出了答案。
关于特征层和分类层
传送门:https://www.zhihu.com/question/270245936/answer/356176790
关于知乎上一个问题,主要讨论在图像或者文本领域,提升特征层的复杂度和提升分类层的复杂度哪个性价比高一点的问题。里面小瑶的回答已经非常不错了,这里我提出一点自己的看法。
首先看数据,如果我们假设数据足够充足的情况下,那么提取词袋词嵌入特征,那么我们利用多层fc是可以对这些相对低纬度的特征进行组合的。其等价于抽取了高纬度特征。然而,重点在于数据一般没那么好,没那么全,高层分类里面会学习出来不存在的特征,也就是过拟合,小瑶在回答中提到fc*3可以得到很好的效果,但是这个说法并不通用,在贝贝智能客服上使用不同层fc得到的效果为1层效果最佳。个人分析,1层本来就可以很好的分类拟合了,过复杂的分类层引入了针对该训练集的一些特征组合。那么如果使用复杂的特征抽取层,好像可以一定程度避免这个问题,抽取的特征在这些数据集上存在,也就是用复杂的特征层抽取的高纬度特征是真实存在的,并不是为了强行拟合训练集产生的(个人想法,也就方便理解)。这点在之后,会给出dpcnn在现有贝贝客服数据集上的表现来佐证。论文阅读
论文观点
图像领域通过不断加深网络,抽取了高纬度特征,效果提升显著。文本领域一直没有很好的抽取高纬度特征的思路,另一方面,很多人认为文本的特征就是词语,所以浅层网络就可以很好的抽取特征。本文解决两个问题:
- 使用多层网络抽取长距离的文本特征(类似于RNN)
- 类比ResNet使用深层网络抽取特征(越深越好呗)
论文关键点
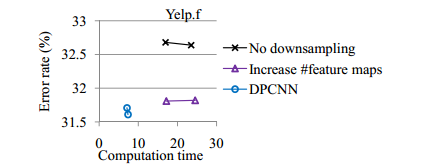
- 下采样控制特征图的数量,这样计算复杂度得到了控制,始终为一个卷积块的2倍左右(每层除2,加起来刚好2倍),同时测试也证明,如果不做这样一层下采样,复杂度提升的同时并不能带来准确率的提升。
- 短连接,类似于ResNet中的跨层恒等映射。
- 使用非监督的词向量提升准确率,比如预先使用log数据训练word2vec。
下图是文章的结构图,左边为DPCNN,中间是TextCNN,右边是ResNet
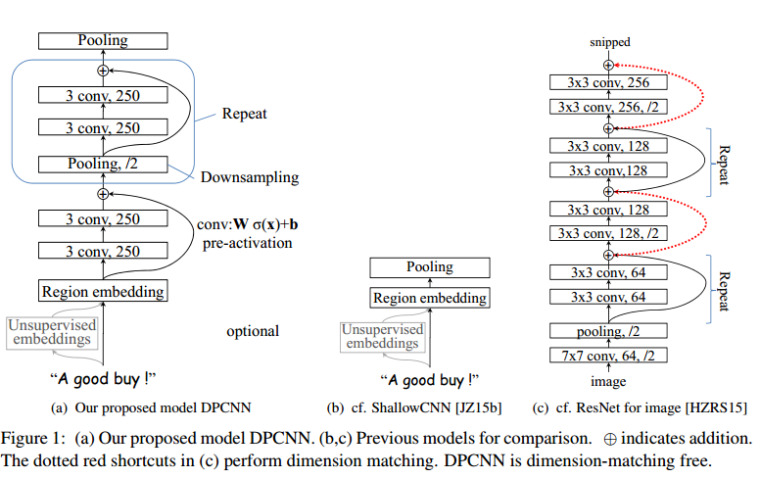
网络结构
下采样层(Downsampling with the number of feature maps fixed)
在每一个卷积层之后,使用max-pooling(size=3,stride=2)来进行采样。对于采样这个操作,一个降低计算复杂度,另一个就是很多之前不进行下采样的模型效果都不好,采样之后的图如下,一个金字塔形,这也就是论文中Pyramid的含义。
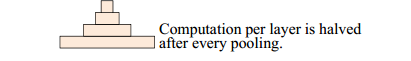
短连接(Shortcut connections with pre-activation)
为了训练更深的网络,我们使用shortcut connections(后以短连接代替)。加号的地方表示Wσ(x)+b,W的行数为特征图的数量,这里是250。σ我们使用ReLU,σ(x)=max(x,0)。这里不太过多介绍,有兴趣的去看ResNet的文章,这里只要知道这种短连接的方式可以使网络加深而不至于无法训练就Ok。
无需维度匹配
这里是ResNet中的一个章节,大家看ResNet的网络结构,每层的输出尺度都不一样,那恒等变换就需要让不同尺度的特征图相加,ResNet中使用如下公式进行匹配,而我们这里可以看到,我们是的短连接是没有过采样层的,这样避免了这个维度匹配问题,当然这里文章也考虑这样是否有不好的影响,做了相应的测试,发现还ok啦。
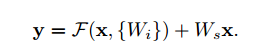
词区域嵌入(Text Region embedding)
从最上面图中的a和c的对比可以看出,DPCNN与ResNet差异还是蛮大的。同时DPCNN的底层貌似保持了跟TextCNN一样的结构,这里作者将TextCNN的包含多尺寸卷积滤波器的卷积层的卷积结果称之为Region embedding,意思就是对一个文本区域/片段(比如3gram)进行一组卷积操作后生成的embedding。对一个3gram进行卷积操作时可以有两种选择,一种是保留词序,也就是设置一组size=3*D的二维卷积核对3gram进行卷积(其中D是word embedding维度);还有一种是不保留词序(即使用词袋模型),即首先对3gram中的3个词的embedding取均值得到一个size=D的向量,然后设置一组size=D的一维卷积核对该3gram进行卷积。显然TextCNN里使用的是保留词序的做法,而DPCNN使用的是词袋模型的做法,DPCNN作者argue前者做法更容易造成过拟合,后者的性能却跟前者差不多(其实这个跟DAN网络(Deep averaging networks)中argue的原理和结论差不多,有兴趣的可以下拉到下一部分的知乎传送门中了解一下)。
通过预训练词向量增强(Enhancing region embedding with unsupervised embeddings)
这一点借用了textCNN的思路,类似语言模型的预测,输入一个词,预测左右相邻的词,然后通过这个与训练的词向量初始化模型的词向量。类似word2vec,这里仅仅使用单层网络来训练。
实验
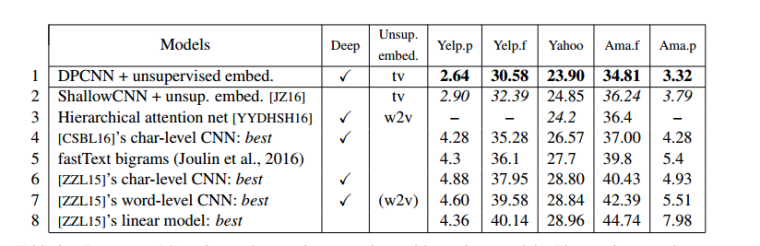
测试1:大数据集,验证有效性
测试2:耗时测试,验证计算复杂度

测试3:验证下采样的效果
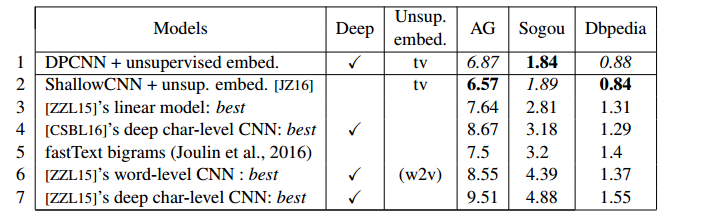
测试4:小数据集测试
测试5:非监督预训练
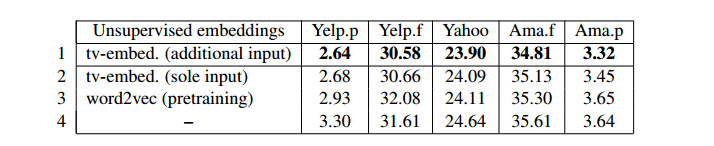
又看到了小瑶的文章:传送一个https://zhuanlan.zhihu.com/p/35457093
关于DPCNN实践与贝贝客服项目
经过一段时间的调参,回头看dpcnn原文数据使用了2分类数据。在贝贝数据集上,多分类很难调试,且二分类上特别容易过拟合。可能提取维度过高,最终放弃该方案。