CS224n: Natural Language Processing with Deep Learning课程笔记
-
所有课件及Assignments可见我的Github:hunto/CS224n
论坛排版有点难看,可见我的博客: hunto.github.ioLecture 1 - 课程介绍
本讲主要内容
- 什么是自然语言处理?人类语言的本质
- 什么是深度学习?
- 课程架构
- 为什么理解语言是困难的?
- 深度学习在自然语言处理中的应用
1. 什么是自然语言处理
- 自然语言处理是以下领域的交叉:
- 计算机科学
- 人工智能
- 语言学
- 目的:使计算机能够处理或“理解”自然语言以用于需要的任务中,例如:
- 执行任务,例如建立日程表、购物
- 语言翻译
- 智能问答
- 完全理解和表示语言的意义(甚至是定义它)是一个困难的目标
- Perfect language understanding is AI-complete.出色的自然语言理解是一个AI完全问题。
[注:在人工智能领域,最困难的问题被非正式地称为AI-complete或AI-hard,这意味着这些计算问题的难度等同于解决中心人工智能问题 - 使计算机像人一样聪明。为了解决问题,AI-complete反映了一种态度,即它不能通过简单的特定算法来解决。 AI-完全问题包括计算机视觉,自然语言理解,以及在解决任何现实世界问题时处理意外情况。 目前,AI完全问题不能单靠现代计算机技术解决,但也需要人工计算。]
2. 什么是深度学习
- 深度学习是机器学习的一个分支
- 所有有很好的效果的机器学习方法均是因为对数据人为设计的表示和输入特征
- 机器学习通过调整权重来得到最好的最终预测结果
第一讲为简介,剩余内容可以自己看课件
-
Lecture2 - 词向量
1. 如何表示一个词语?
一个新词语的意思是通过已知词语来表示的

WordNet这样解释词语的问题
- 缺少对词语见细微差别的表示
- 缺少词语新的意思 -- 词的意思不是一成不变的,但是保证对词语的解释永远是最新的是不可能的
- 主观的
- 需要人为构建和适配
- 难以计算细微的词语相似度
因此,我们可以将词使用离散的数学标记来表示。
词语可以使用one-hot向量 [one-hot意思为向量中有1个1,其余为0] 的方式来表示,例如:辣鸡 = [1, 0, 0, 0] 优秀 = [0, 1, 0, 0]这样得到的向量的维度 = 词库中的词语数
但是,这样的表示方法也存在很多问题:
例如:辣鸡 = [1, 0, 0, 0] 垃圾 = [0, 0, 1, 0]但在具体语境中,
辣鸡zzy和垃圾zzy是相近或者说等价的,可他们放到one-hot中的表示却是不同的两个向量,因此,这样的表示方法无法表示出词语间的相似度(one-hot向量间的距离与他们的词语相似度无关)。解决方案:
- 可否依靠WordNet的词库来得到词语相似度?
- 或者使机器自己学会在向量中编码表示相似度
我们想到用词语所处的语境来表示词语。
- 核心思路:一个词的意思由频繁出现在它附近的词决定
- 使用大量含有目标单词的语句来建立目标单词的词向量表示

2. Word2Vec概览
Word2Vec(Mikolov et al. 2013)是一个训练词向量的框架。- 有大量的语料
- 适配的词典中的每一个词都由一个向量表示
- 遍历文本中出现单词
c的每一个位置,我们假设c周围的若干单词为o,使用o与c的词向量相似度来计算通过o推出c的概率。不断调整词向量以使概率最大化。
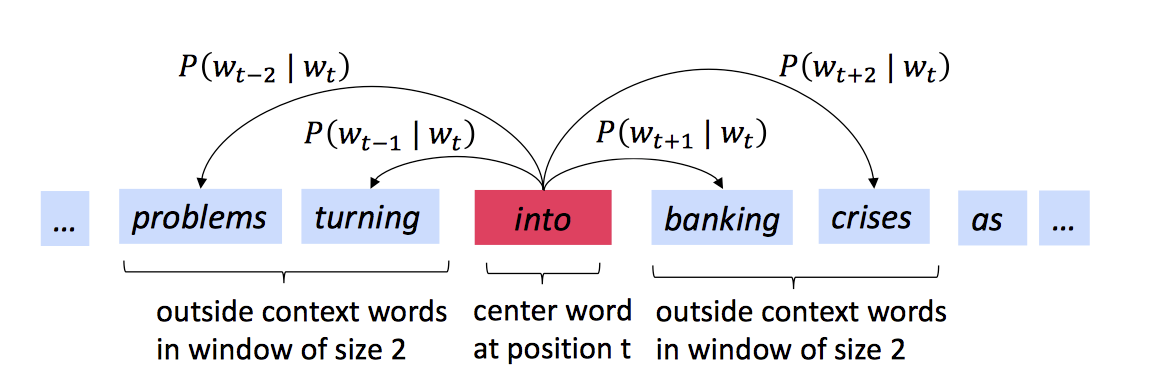
目标函数(损失函数)
其中,t=1,...,T为语句中的位置,m为周围词的范围,中心词为调整权重将损失函数值降到最低<=>使预测概率最大化
如何计算P?
对于每个词,我们将使用两个向量:
, 当w为目标单词(中心词) , 当w为周围单词
那么,对于一个中心词
c和周围词o,我们可以得到概率公式为:
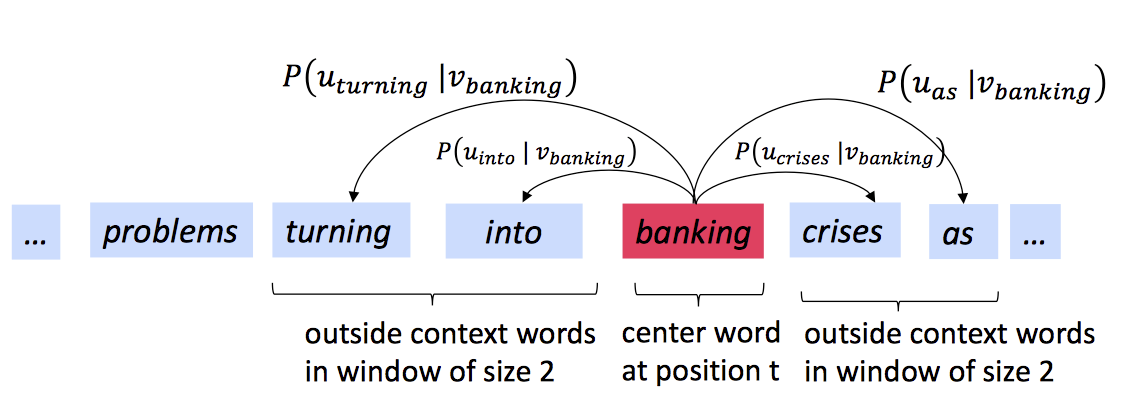

- 为什么要使用两个向量?
更容易优化。在最后求两者平均值。
两种类型的模型
-
Skip-grams(SG)
使用目标单词作为输入,预测目标单词周围的词,取概率最高的[8](窗口大小)个词 -
Continuous Bag of Words(CBOW)
使用目标单词周围的[8]个词作为输入,预测目标单词,取概率最高的
我们现在已经有一个需要最小化的损失函数了,但是如何使损失函数最小化呢?
Gradient Descent(梯度下降)
梯度下降是一个最小化损失函数的算法。
梯度下降法,当前θ值,计算其在损失函数中的梯度,再向梯度下降方向变化当前值,直到找到局部最小值。

Stochastic Gradient Descent(随机梯度下降)
我们一次对语料库中的所有词语使用梯度下降算法是不现实的,因此我们使用随机梯度下降算法来解决梯度下降的计算资源问题。在随机梯度下降法中,每次我们只取一段sample window,进行梯度下降。
-
Assignment1
q1_softmax
softmax函数很简单,每一个元素的e次幂除以所有元素的e次幂之和,即:
但是直接把公式放到计算机中使用numpy计算肯定是不行的。e的1000次方肯定爆,且计算量太大,于是我们根据定理:
可以令c=max(x),这样就不会产生计算错误出现无穷数infty的情况了。实现的代码如下:
if len(x.shape) > 1: # Matrix ### YOUR CODE HERE cal_softmax = lambda x: np.exp(x) / np.repeat(np.sum(np.exp(x), axis=1, keepdims=True), x.shape[1], axis=1) x = cal_softmax(x - np.reshape(np.max(x, axis=1), [x.shape[0], 1])) ### END YOUR CODE else: # Vector ### YOUR CODE HERE cal_softmax = lambda x: np.exp(x) / np.sum(np.exp(x), axis=0) x = cal_softmax(x - np.max(x)) ### END YOUR CODEq2
q2_sigmoid
首先需要实现sigmoid函数,sigmoid function定义如下:
q2_sigmoid.py实现代码如下:
- sigmoid(x)
s = 1 / (1 + np.exp(-x)) - sigmoid_grad(s)
ds = s * (1 - s)
q2_gradcheck
接着实现grad_check用于之后的测试。
x[ix] += h random.setstate(rndstate) new_f1 = f(x)[0] x[ix] -= 2 * h random.setstate(rndstate) new_f2 = f(x)[0] x[ix] += hq2_neural
最关键的地方,这里定义了一个简单的网络:
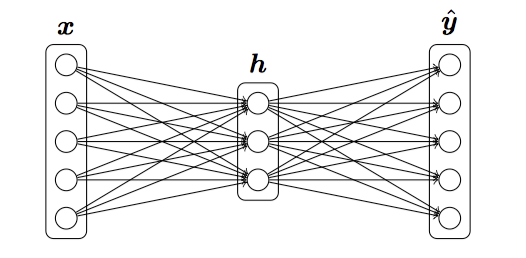
其中,
这些即为网络的前端部分。h = sigmoid(np.dot(X, W1) + b1) # hidding layer y_hat = softmax(np.dot(h, W2) + b2) # output y网络后端部分为loss与梯度。
cost = np.sum(-np.log(y_hat[labels == 1])) / X.shape[0] d3 = (y_hat - labels) / X.shape[0] gradW2 = np.dot(h.T, d3) gradb2 = np.sum(d3, axis=0, keepdims=True) dh = np.dot(d3, W2.T) grad_h = sigmoid_grad(h) * dh gradW1 = np.dot(X.T, grad_h) gradb1 = np.sum(grad_h, axis=0)到这里,一个简单的网络就定义完了
q3_word2vec
normalizeRows
首先需要实现一个normalizeRows函数用于将向量单位化(ljht这个名称我还给老师了),也就是向量元素平方和为1。
x = x / np.sqrt(np.sum(np.square(x), axis=1, keepdims=True))softmaxCostAndGradient
该函数与q2中实现的大致相同
y_hat = softmax(np.dot(predicted, outputVectors)) cost = np.log(np.sum(np.exp(np.dot(predicted, outputVectors)), axis=0)) - outputVectors[target].dot(predicted) gradPred = np.sum(y_hat.reshape(-1, 1) * outputVectors, axis=0) - outputVectors[target] grad = y_hat.reshape(-1, 1) * np.tile(predicted, (outputVectors.shape[0], 1)) grad[target] -= predicted后面的内容见github吧
- sigmoid(x)
-
Lecture3 - More Word Vectors
对Word2Vec实现的总结
- 遍历语料库中的所有单词
- 预测每个词周围的词
- 每一个相邻词语组合(如
I like中I与link为相邻词语)只会被捕获一次
那么,为什么不直接获取词语组合的个数?
例如:
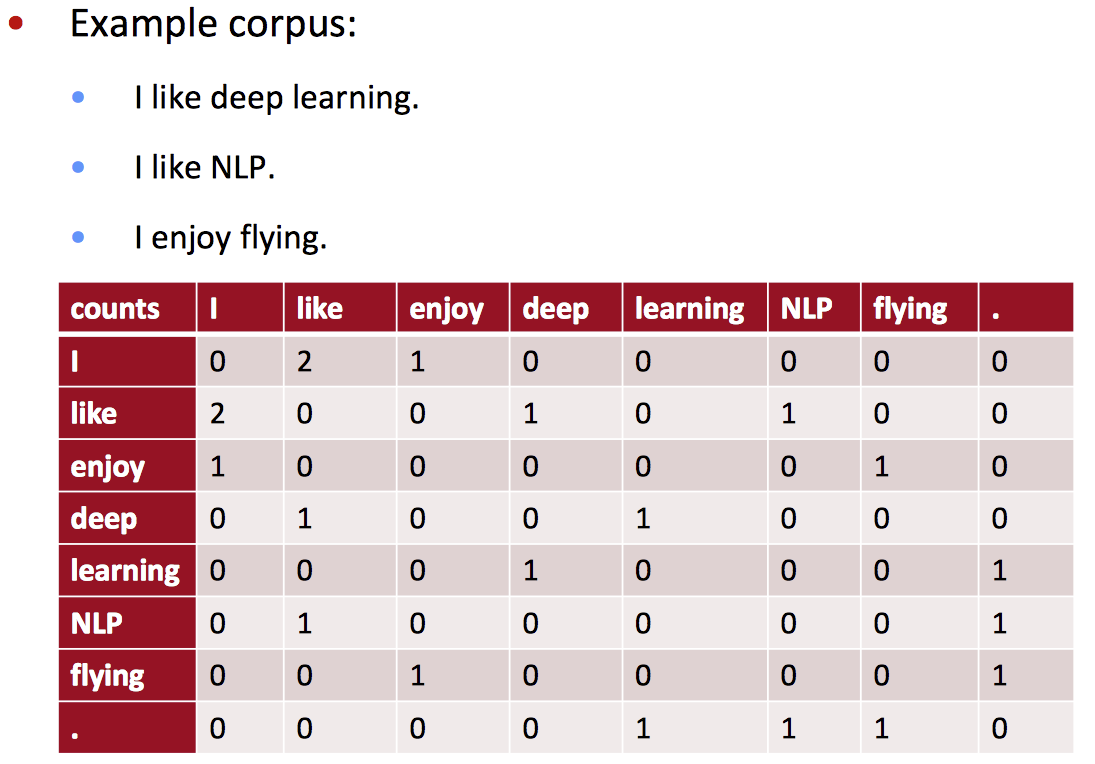
朴素共素向量的问题:
- 出现新的词时,旧向量的维度都需要改变
- 维度由词典大小决定 -- 高维度
- 高稀疏性
解决办法:将高维向量转为低维向量
例如SVD
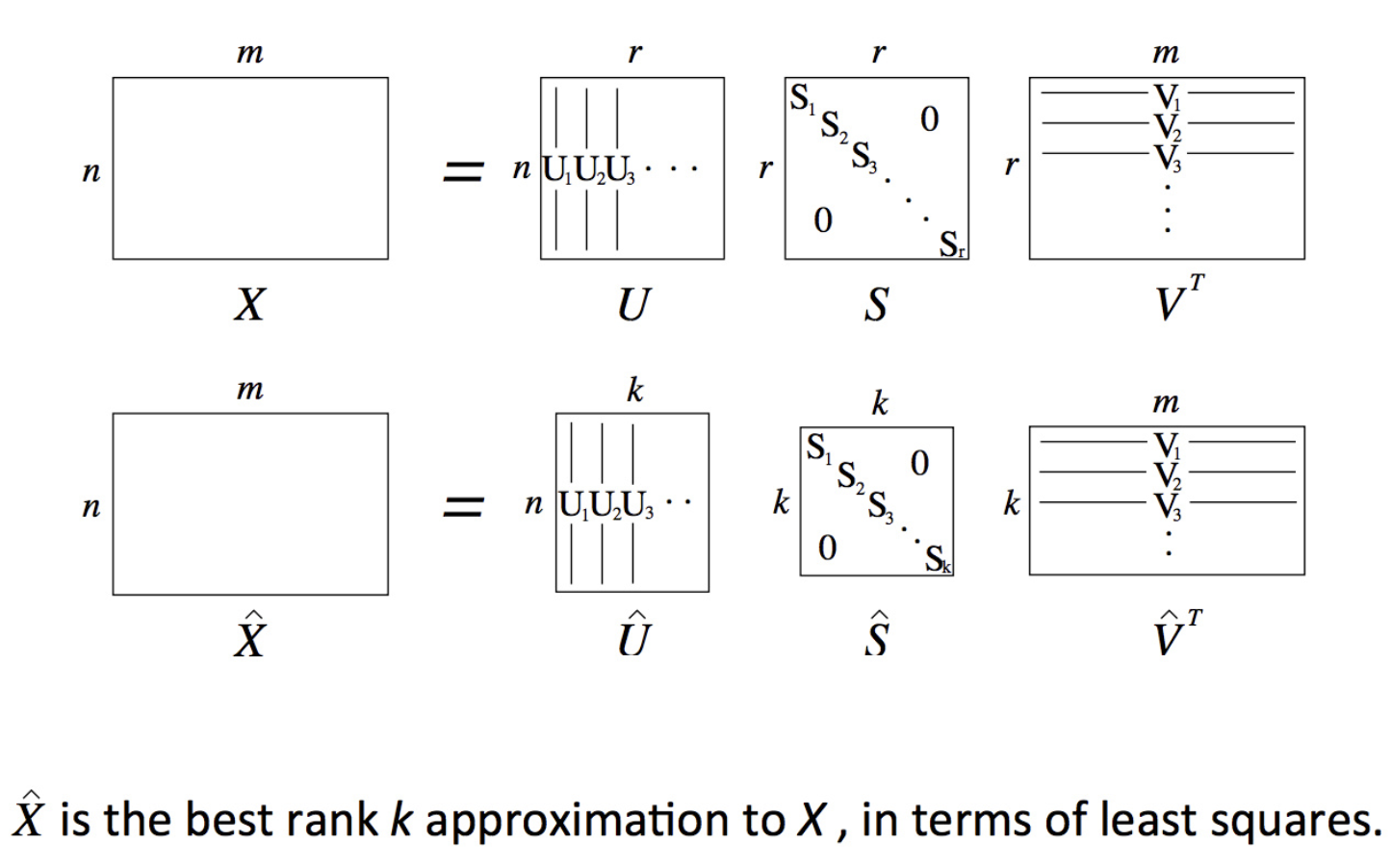
但SVD也有问题:
- 计算复杂度高:MxN矩阵复杂度为O(M x N)
- 增加词后还是需要更新整个矩阵
- 与其他的DeepLearning模型训练方式不同
两种方法的比较:
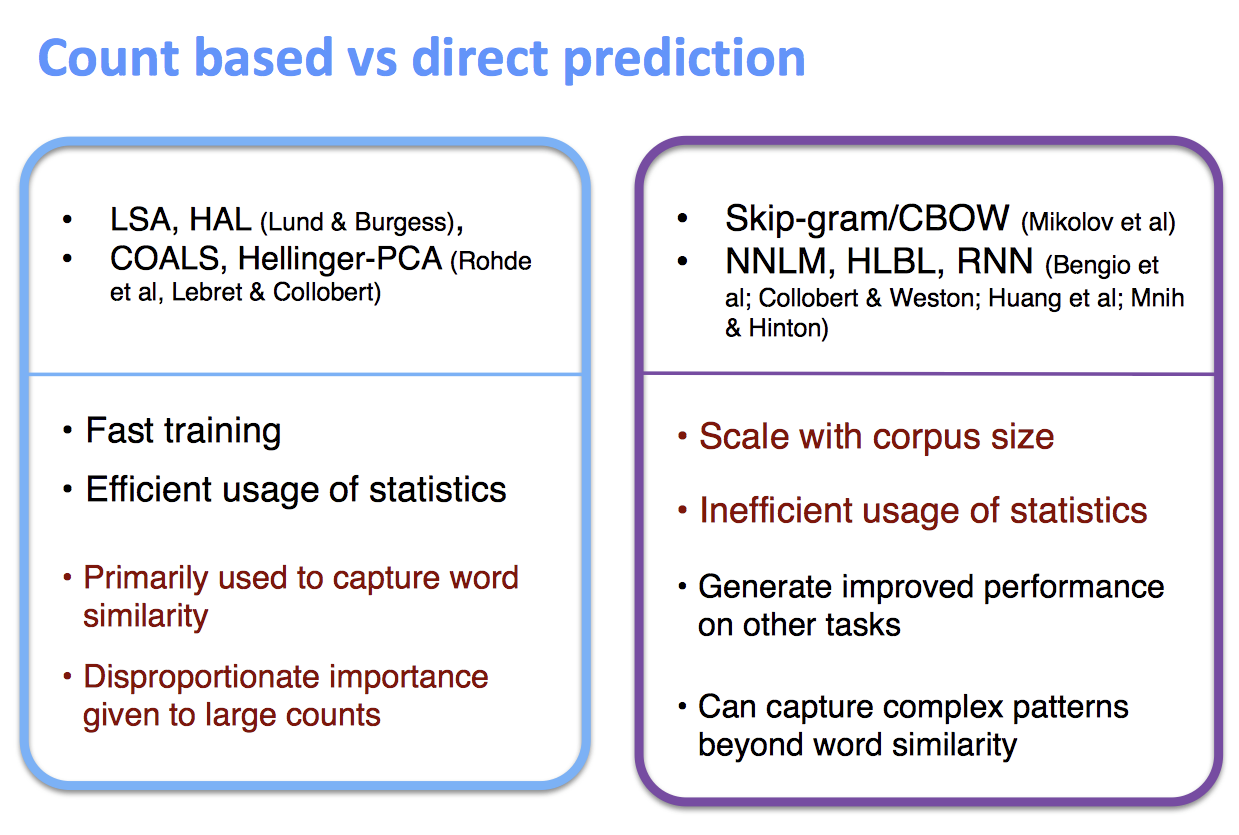
当然,也有两者结合的:GloVe

如何评价一组词向量
- 内部:在一个特定的子任务中评估
- 快速评估
- 帮助理解系统
- 不确定词向量对真实任务的效果
- 外部:在一个真实任务中评估
- 计算准确率可能需要花费很长时间
- 不确定结果是否为子系统的问题或者是词向量与子系统共同作用的问题
-
-------- 多公式预警 --------
Lecture4 - Word Window Classification and Neural Networks
传统机器学习分类一般使用Logistic Regression或SVM等模型来划分决策边界,即只改变分类间的分界线,而不改变输入的特征向量。
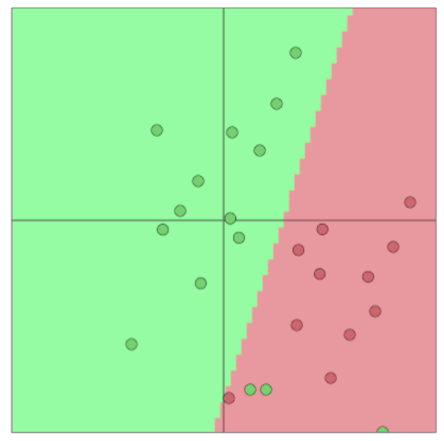
softmax分类函数
softmax分类函数取权值矩阵W的一行W_j乘上输入向量,归一化得到概率。
softmax与cross-entropy error(交叉熵误差)
我们的目标是最大化正确的y的概率。因此,最小化正确分类的概率的负对数。
因为分类y为one-hot向量,所以loss函数等价于交叉熵函数:
对N个点来说,总loss为:
平均后加上正则化项,为:
因此,我们可以得到真正的损失函数为:
当我们有很多特征时,正则化可以减轻过拟合
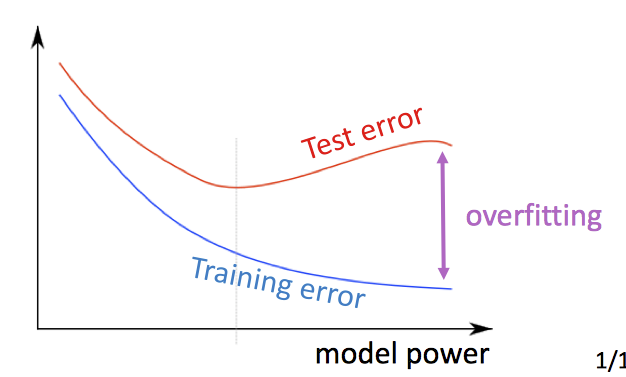
一般机器学习在词向量分类中的问题
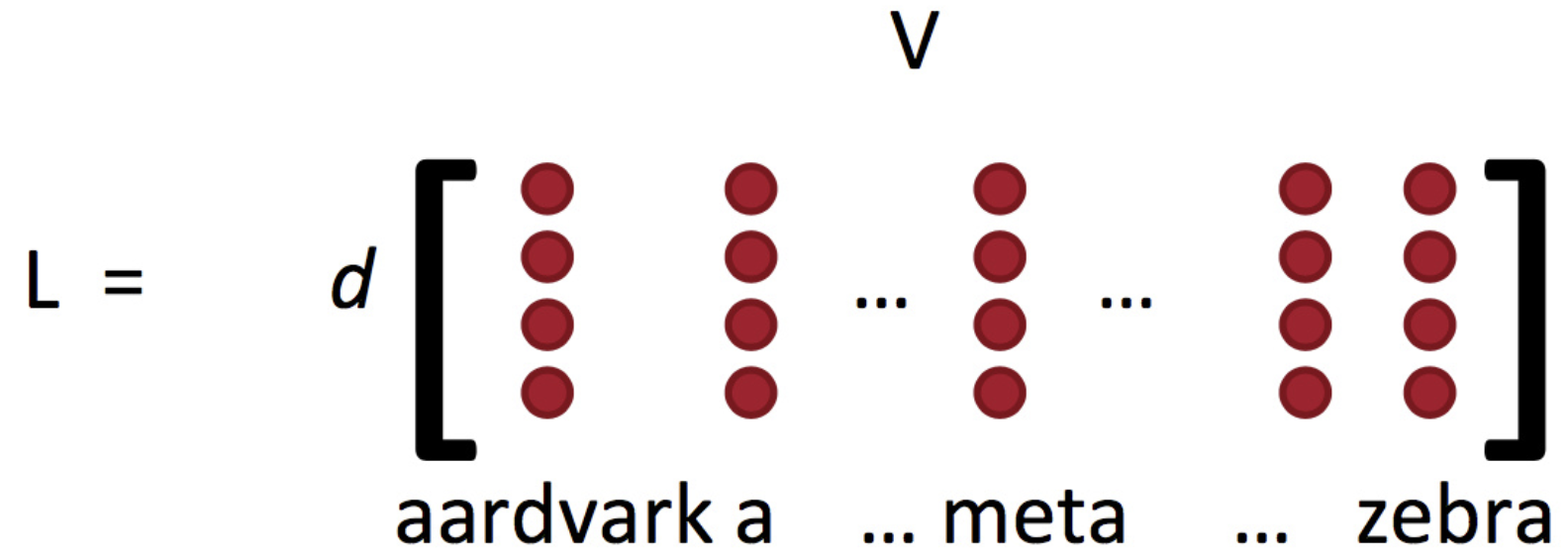
对于一般的机器学习,没有很多特征向量,权值矩阵维度低,只需要更新决策边界。但是在深度学习或词向量中,需要同时学习权值矩阵和词向量,特征维度很高,极其容易过拟合。
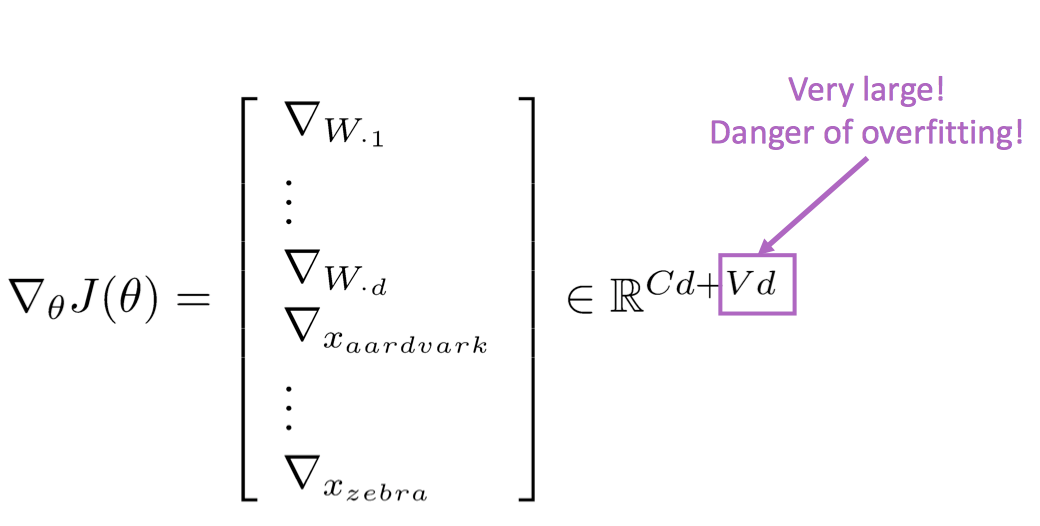
重新训练词向量中的陷阱
我们有一个预训练的词向量,结果较泛化。
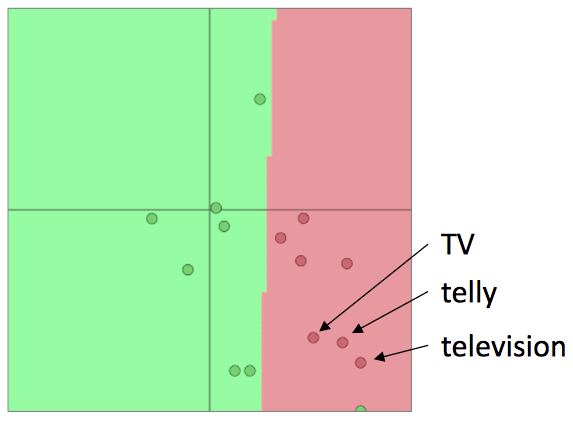
而当我们想用特定语料重新训练词向量时,极易产生分类错误的情况。
那么,我们该不该训练我们自己的词向量呢?
- 如果语料库很小==》不要重新训练词向量
- 如果有非常大的数据集==》训练词向量可能会得到更好的结果
side note:
- 词向量矩阵L常被称作lookup table
- Word vectors = word embeddings = word representations (mostly)
Window Classification
通过之前的介绍,我们对单个单词的分类已经几乎完成了。我们可以通过上下文给单个单词分类,以消除歧异。
所谓window classification,我们可以将特征向量X想象成一个固定大小窗口,内容为文本的一部分,我们直接将窗口内的词语的向量拼接可得到X。

由于我们的特征向量X只是原有X的拓展,损失函数与之前相同。
Oh! Neural Network
Softmax (等价于logistic regression)效果有限,只有线性决策边界,当问题变得复杂时,效果不好。但是神经网络可以学到复杂的多的特性和非线性决策边界。Neural Network, YES!

From logistic regression to neural nets
神经网络的每一个神经元都是一个二分类逻辑回归单元。

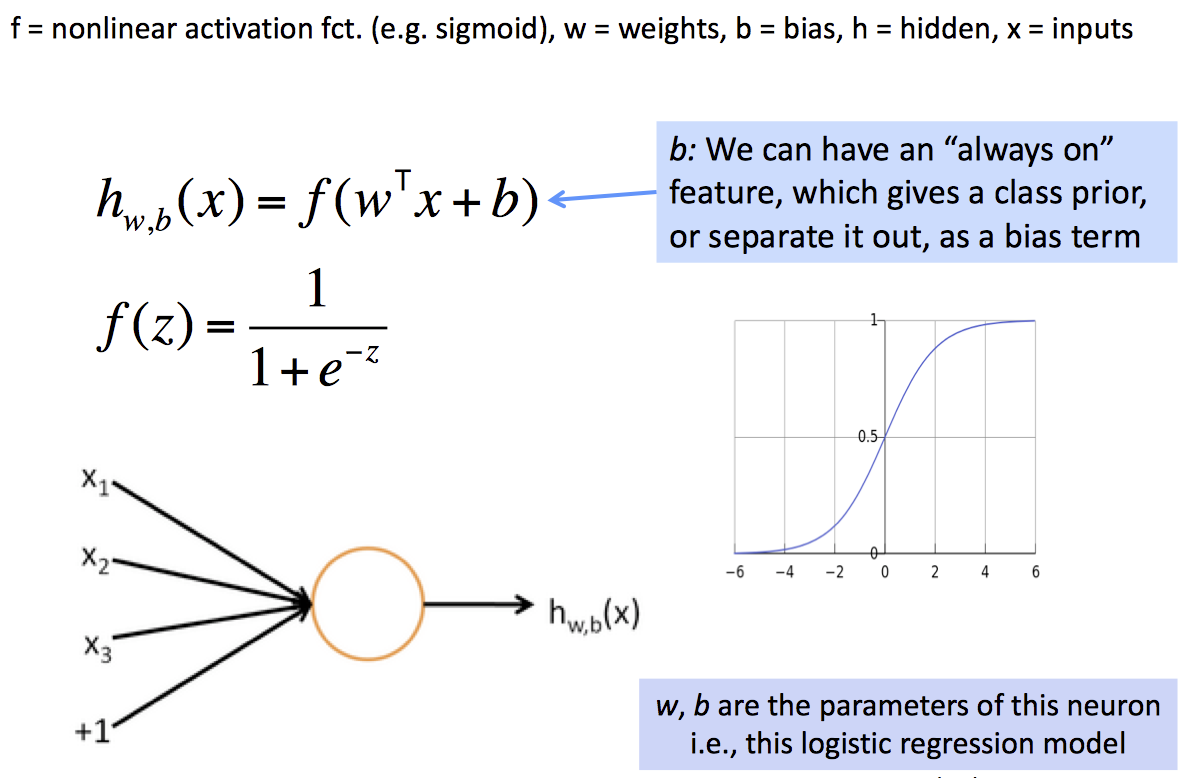
神经网络同时运行多个逻辑回归,但我们并不需要知道他们预测什么,只需要丢给下一层网络,由最终损失函数自动决定他们预测什么。多层并行逻辑回归网络就构成了多层神经网络。
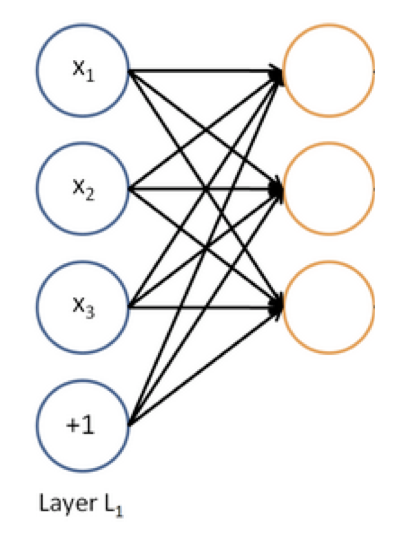
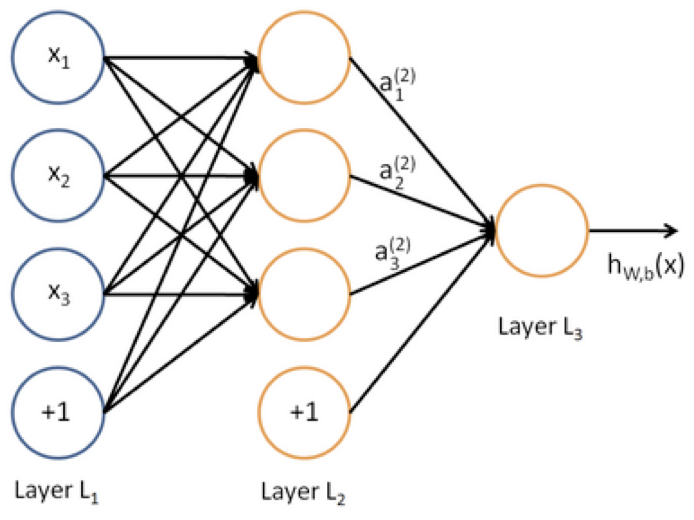
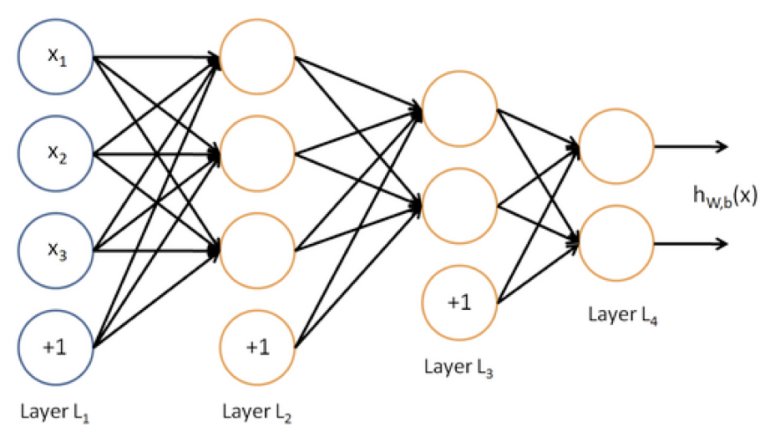
为什么要是非线性系统
因为多层线性系统叠加还是线性系统。

Feed-forward Computation 前向传播网络
课件中给了一个简单的网络作为例子:

这种红点图经常在论文里看到,大致代表单元数;中间的空格分隔开一组神经元,比如隐藏层单元数为2×4。U是隐藏层到class层的权值矩阵:
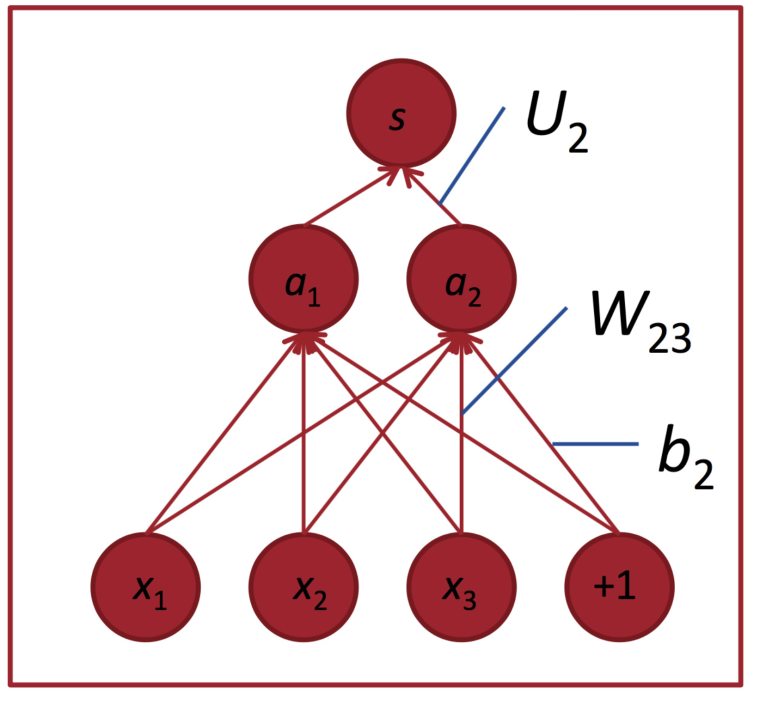
其中a是激活函数:
The max-margin loss 间隔最大化损失
怎么设计目标函数呢,记
代表误分类样本的得分, 表示正确分类样本的得分。则朴素的思路是最大化 $(s−s_c)$ 或最小化 $(s_c−s)$。但有种方法只计算 $s_c>s⇒(s_c−s)>0$时的错误,也就是说我们只要求正确分类的得分高于错误分类的得分即可,并不要求错误分类的得分多么多么小。这得到间隔最大化目标函数:
但上述目标函数要求太低,风险太大了,没有留出足够的“缓冲区域”。可以指定该间隔的宽度
$(s−s_c<\varDelta)$ ,得到:
可以调整其他参数使得该间隔为1:
在这个分类问题中,这两个得分的计算方式为:
通常通过负采样算法得到负例。另外,这个目标函数的好处是,随着训练的进行,可以忽略越来越多的实例,而只专注于那些难分类的实例。
反向传播训练
U的梯度:
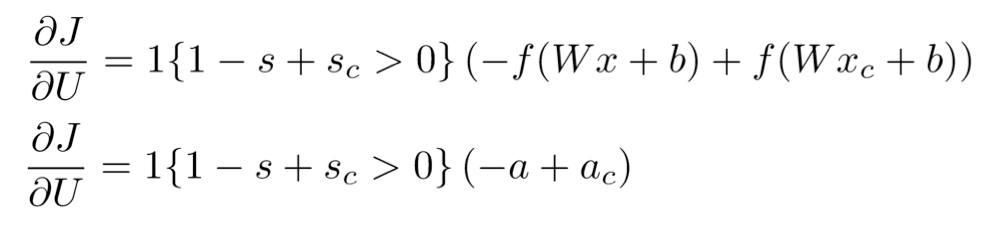
对于偏置的偏导数
:
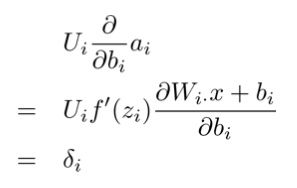
最后一片拼图是对词向量的偏导数,由于连接时每个输入单元连到了多个隐藏单元,所以对某个输入单元的偏导数是求和的形式(残差来自相连的隐藏单元):
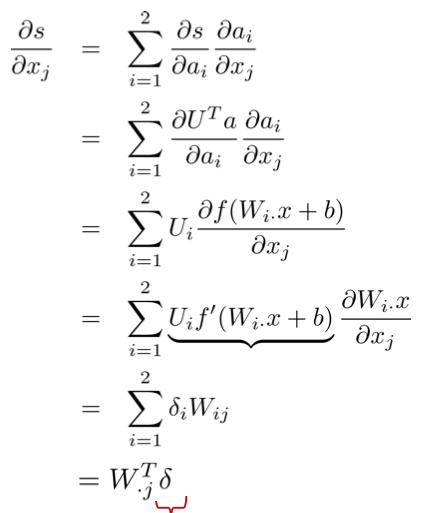
其中,
是第 列,转置后得到行向量;红色部分是误差,相乘后得到一个标量,代表词向量第 维的导数。那么对整个词向量的偏导数就是:
-
Python Review
-
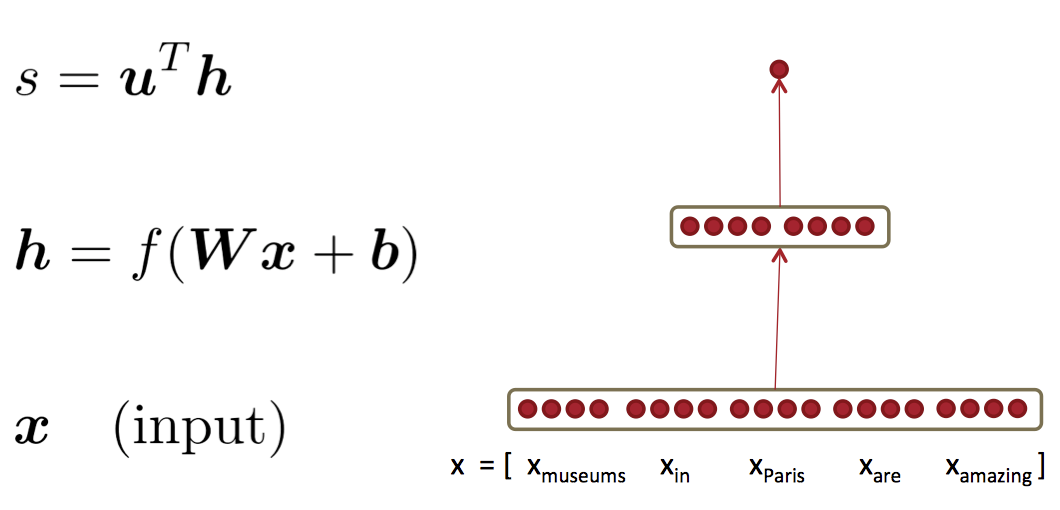
Lecture5 - backpropagation (反向传播)
单层神经网络
多层神经网络
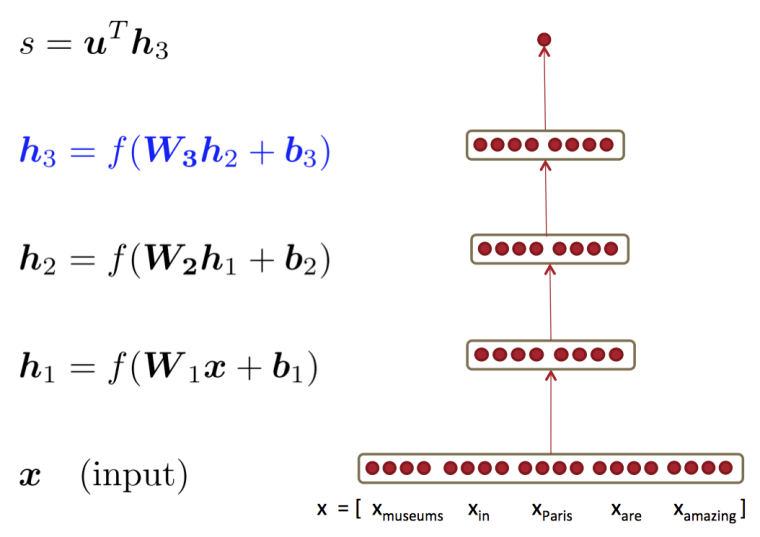
为什么需要更多层网络?
层数越多,可以表达的问题越复杂
Stochastic Gradient Descent 随机梯度下降
前向传播与反向传播
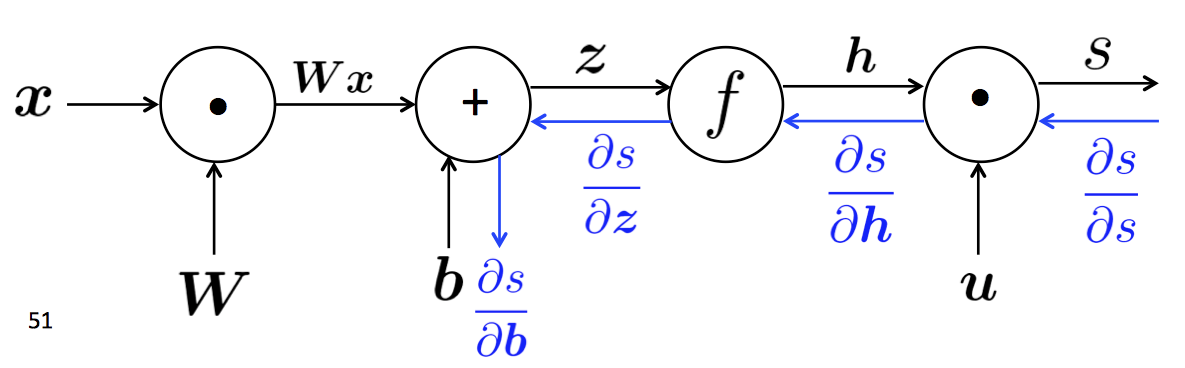
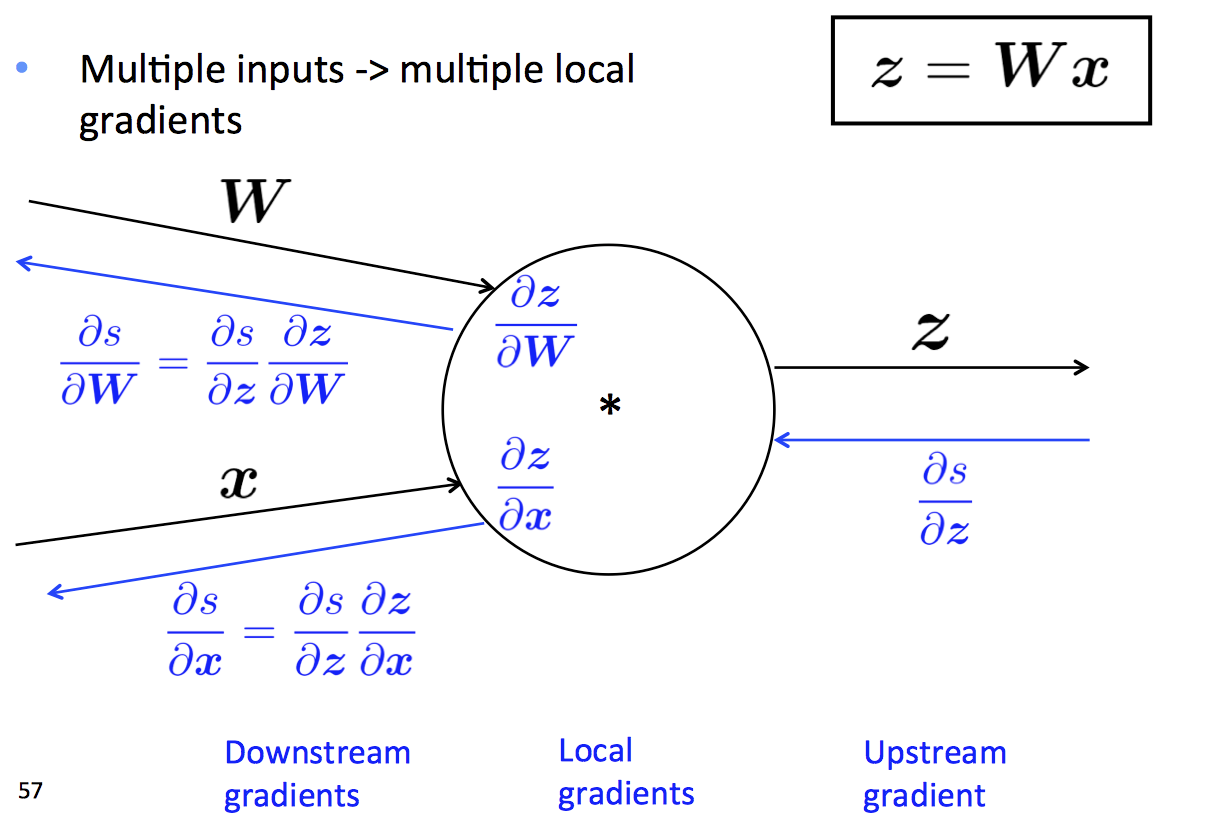
-
Lecture6 - Introduction to TensorFlow
YX TensorFlow.
-
-
此回复已被删除!
-
Lecture7 - Dependency parsing (句法分析)
-
Lecture8 - Recurrent Neural Networks (循环神经网络)
Language Modeling (语言模型)
语言模型是一个预测一段文字的下一个词是什么的任务。
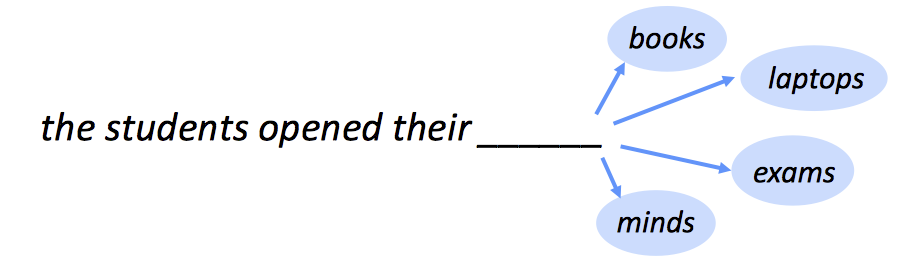
正式地说,Language Model就是,通过已给的词的序列{X_1, X_2, ..., X_t},计算出下一个词X_{t+1}的概率:
其中,W_j是词库中的一个词。
我们每天都在使用Language Model:
n-gram Language Models
我们该如何学习一个语言模型呢?
使用n-gram Language Model一个 n-gram 是一个由连续的词组成的序列:
- unigrams: "the", "students", "opened", "their"
- bigrams: "the students", "students opened", "opened their"
- trigrams: "the students opened", "students opened their"
- 4 - grams: "the students opened their"
n-gram的思路是统计每个gram出现的次数,用这些来预测下一个词。
具体实现
我们首先做一个简单的假设: 第t+1个词只由它之前的(n-1)个词决定,即:
但是,我们怎么得到这n个gram和n-1个gram的概率呢?
通过在大语料库中计算它们的个数n-gram Language Model Example
假设我们正在学习一个4-gram语言模型。

若在语料库中:students opened their出现了1000次students opened their books出现了400次 =>P(books|students opened their) = 0.4students opened their exams出现了100次 =>P(exams|students opened their) = 0.1
n-gram模型的问题
-
如果语料库中一个词从没有出现在某个词序列(
students opened their)后,那个词的概率就是0
解决方案:给每个词的count值加一个很小的量 —— smoothing(平滑处理) -
如果语料库中压根就没有这个词序列(
students opened their),所有词的概率都是0!
解决方案:使用更小的gram(opened their)来替代 —— backoff -
n-gram模型是巨大的,它需要给每个词都与预测序列计算一次概率,空间以及时间复杂度均很高。
那么,我们能不能用神经语言模型(neural Language Model)来实现呢?
当然可以。可以用一个固定大小的CNN来实现。
A fixed-window neural Language Model

这样的模型相较于n-gram的提升:
- 没有稀疏的问题
- 模型大小为O(n),相较于n-gram的O(exp(n))提升巨大
但是也存在问题:
- 固定的window太小
- 增加window大小的同时也会增加W的大小
- window永远不可能足够大
- 输入的4个x都有不同的W,当挪动window时,它们并不共享权值。例如
the students opened their与students opened their books虽然都有students,但是不是同一个位置,并不能共享权值。
因此,我们需要一个可以处理任何长度输入的神经模型。
OH! Recurrent Neural Networks (RNN)
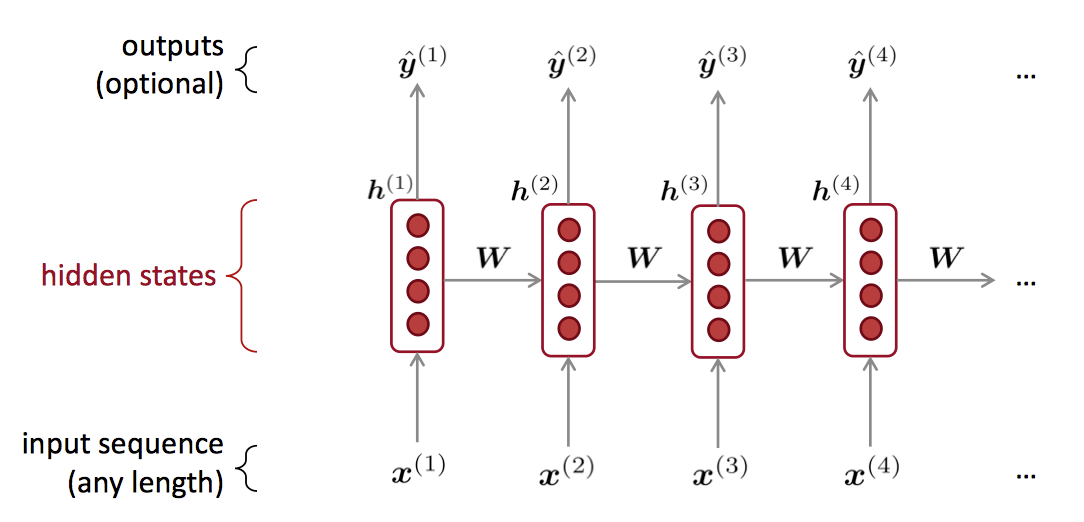
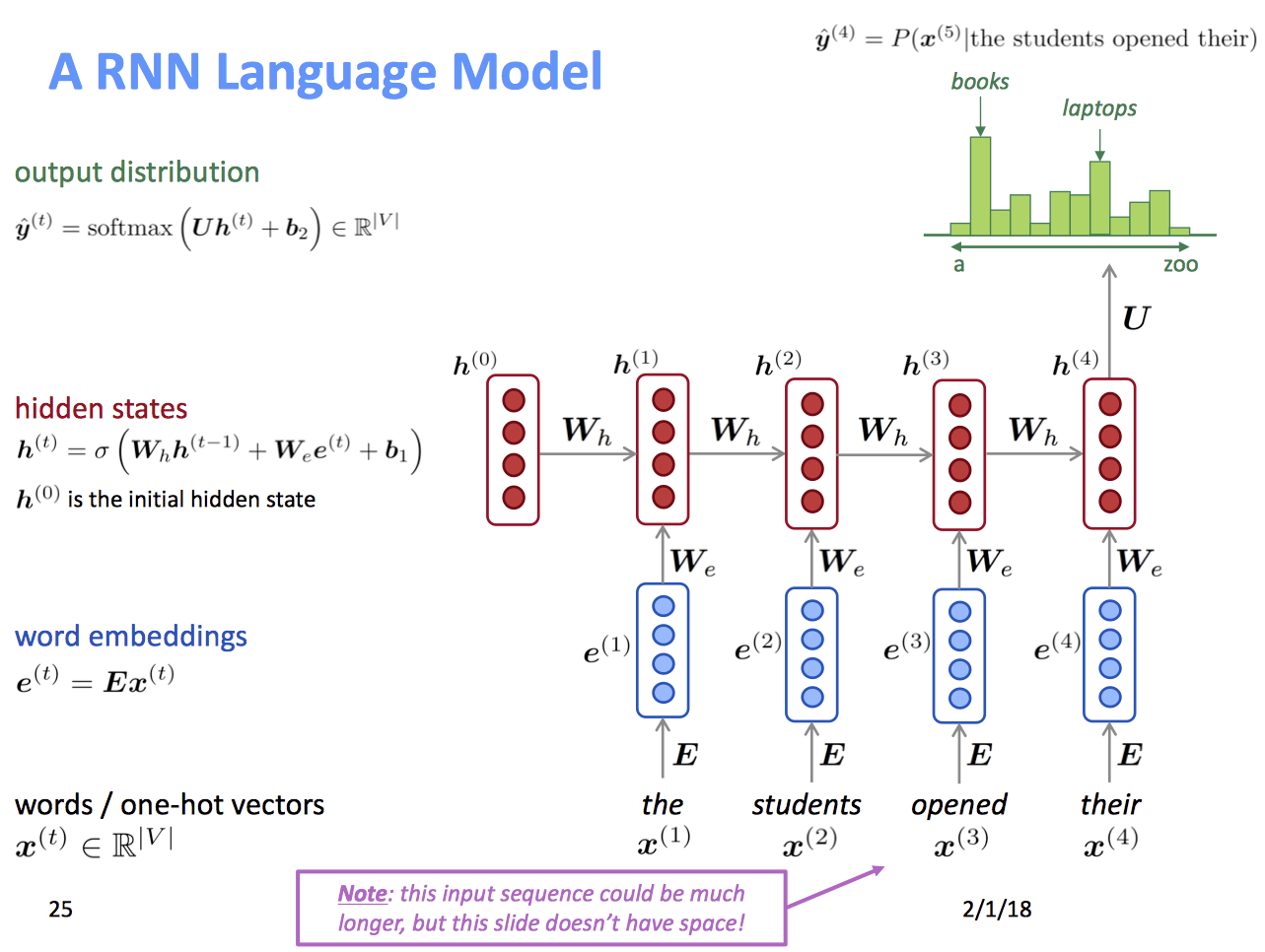
Loss Function损失函数
我们一般使用Cross-Entropy交叉熵作为损失函数。对于时间点t中预测得到的下一个词,以及真实的下一个词 ,有该节点的损失函数: 总损失函数为:
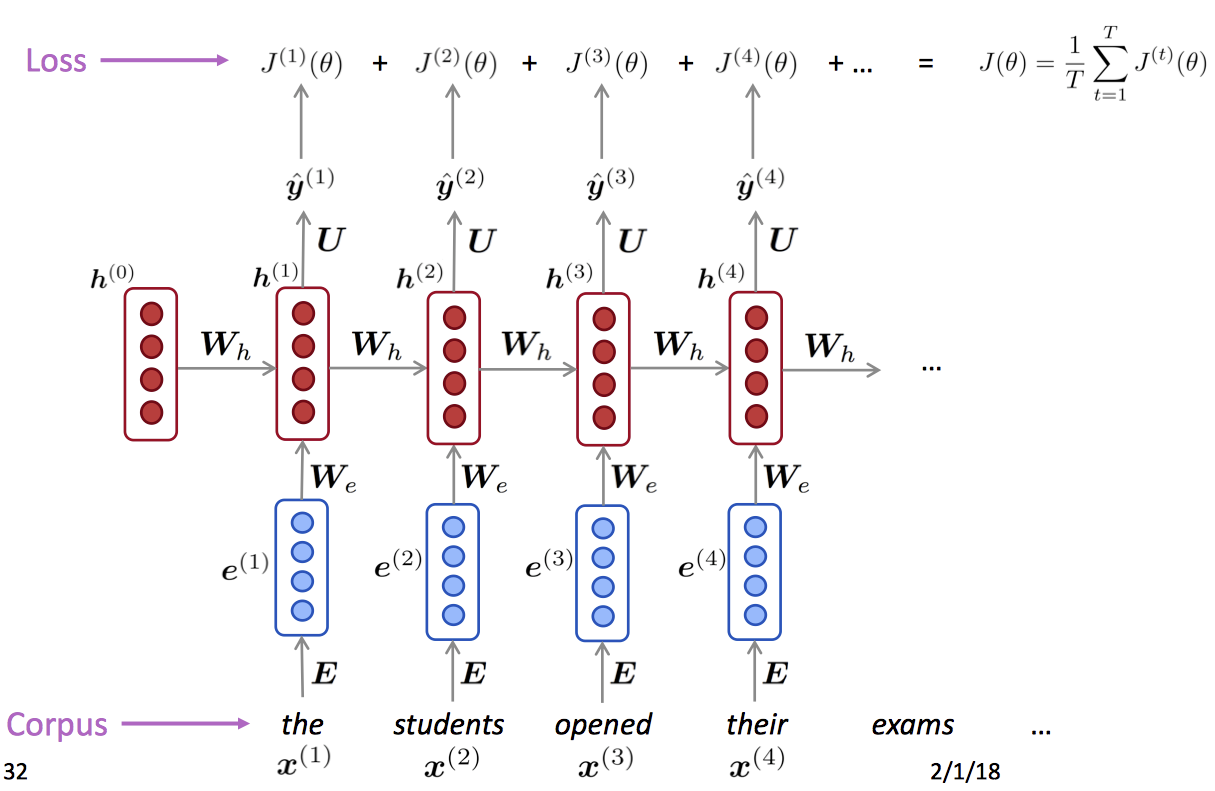
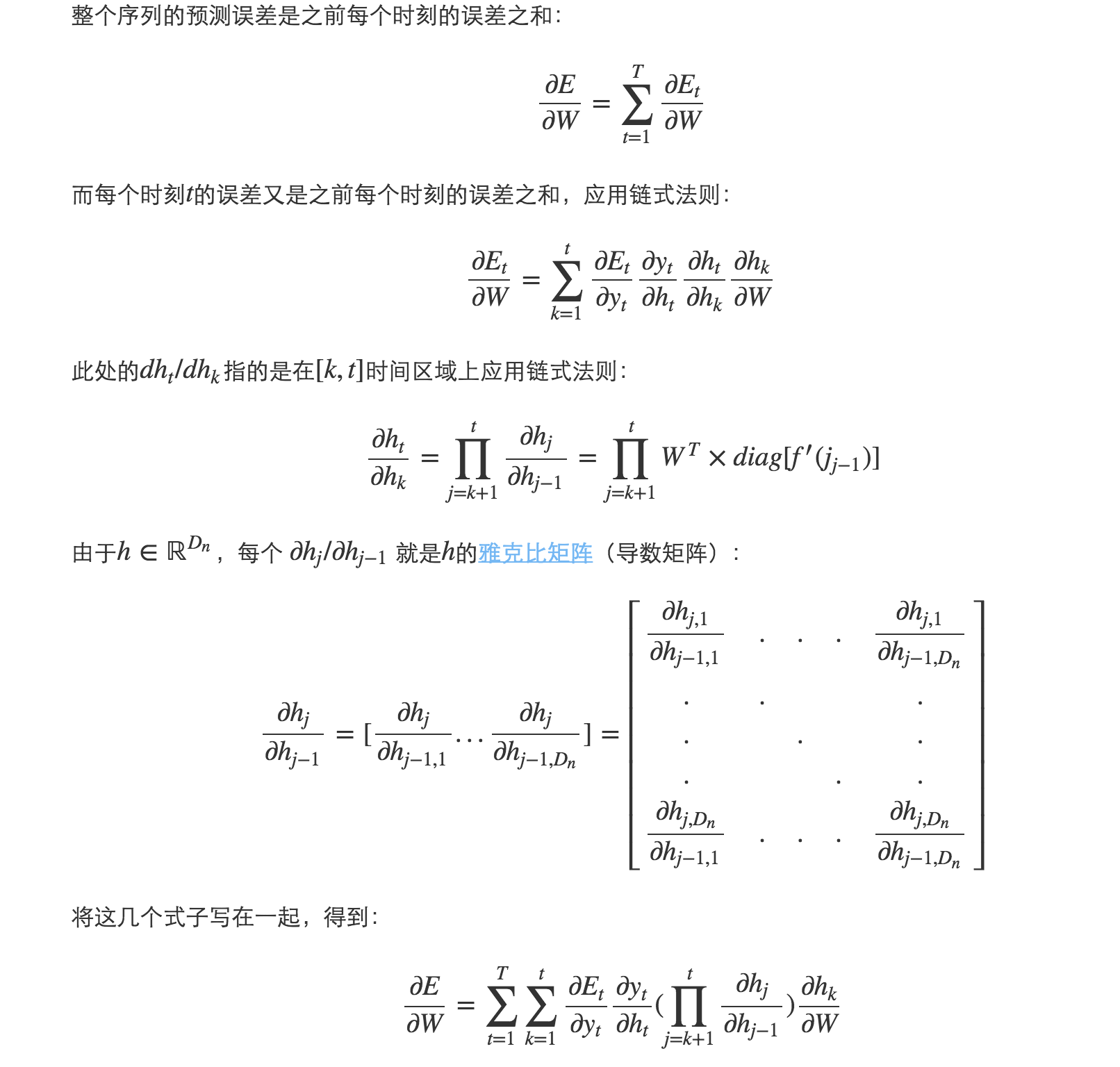
反向传播
这里可以参考CS224n笔记8 RNN和语言模型,写的很好

循环神经网络的优点
- 可以处理任意长度的输入
- 对于更长的输入,模型大小并不会增加
- 循环神经网络中某一步的计算可以使用之前计算结果。(受之前计算影响,与之前的有关)
循环神经网络的缺点
- 递归计算很慢,无法并行计算。
- 很难从中间的步骤中获取到有用的信息。
- 之后还会介绍更多的缺点
-
Lecture9 - Vanishing Gradients and Fancy RNNs(LSTMs and GRUs)
课件前半部分讲了梯度消失问题,我已在机器学习梯度消失与梯度爆炸问题详解中说明,不再赘述。
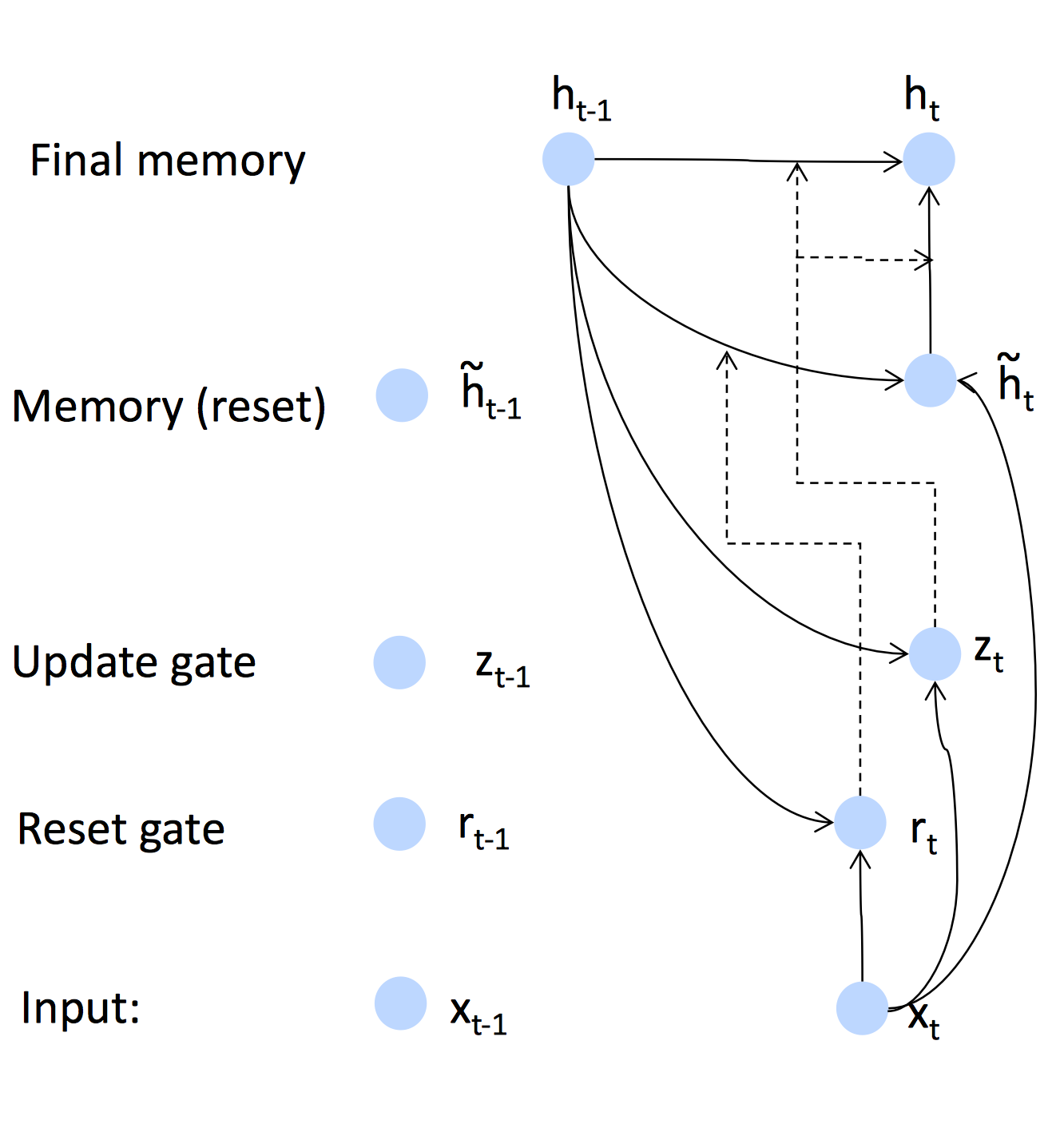
Gated Recurrent Units
为了改善梯度消失问题,引入了更复杂的隐藏单元,例如GRU。主要思想是
- 保留记忆以捕捉更长的关系,可以决定何时遗忘
- 误差可以根据输入的不同而不同
在标准的RNN中,隐藏层的计算直接基于前一层的输出以及输入x:
而GRU首先会基于当前输入和隐藏状态计算一个更新门(另一层):
再利用相同的方法不同的权值计算一个reset gate:
然后就可以得到与一般RNN之前不同的记忆内容:
如果reset gate的元素为0,则会遗忘之前的记忆,只会存储新输入的信息。
最后得到的隐藏层h_t为:
从这里我们可以看出,update gate决定的是当前输入是否改变隐藏层状态。如果z_t为1,则h_t仅会复制前一层的状态,与当前输入无关。而reset gate则是控制记忆是否被遗忘或遗忘的多少,如果r_t为0,则之前层的记忆会被遗忘。
用图示的方法更为直观:
GRU是如何改善梯度消失问题的?
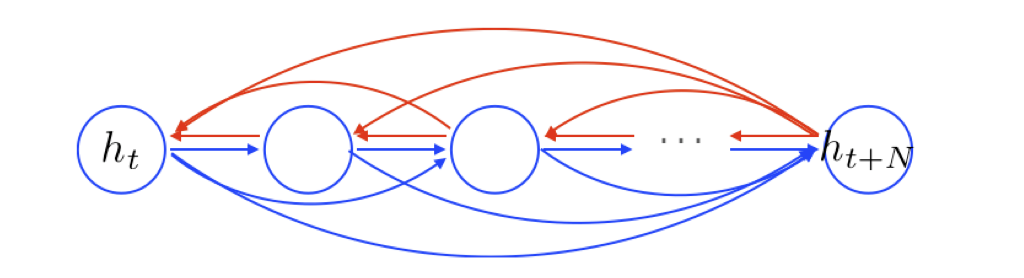
GRU可以让网络剪掉不必要的连接,减少反向传播的深度。
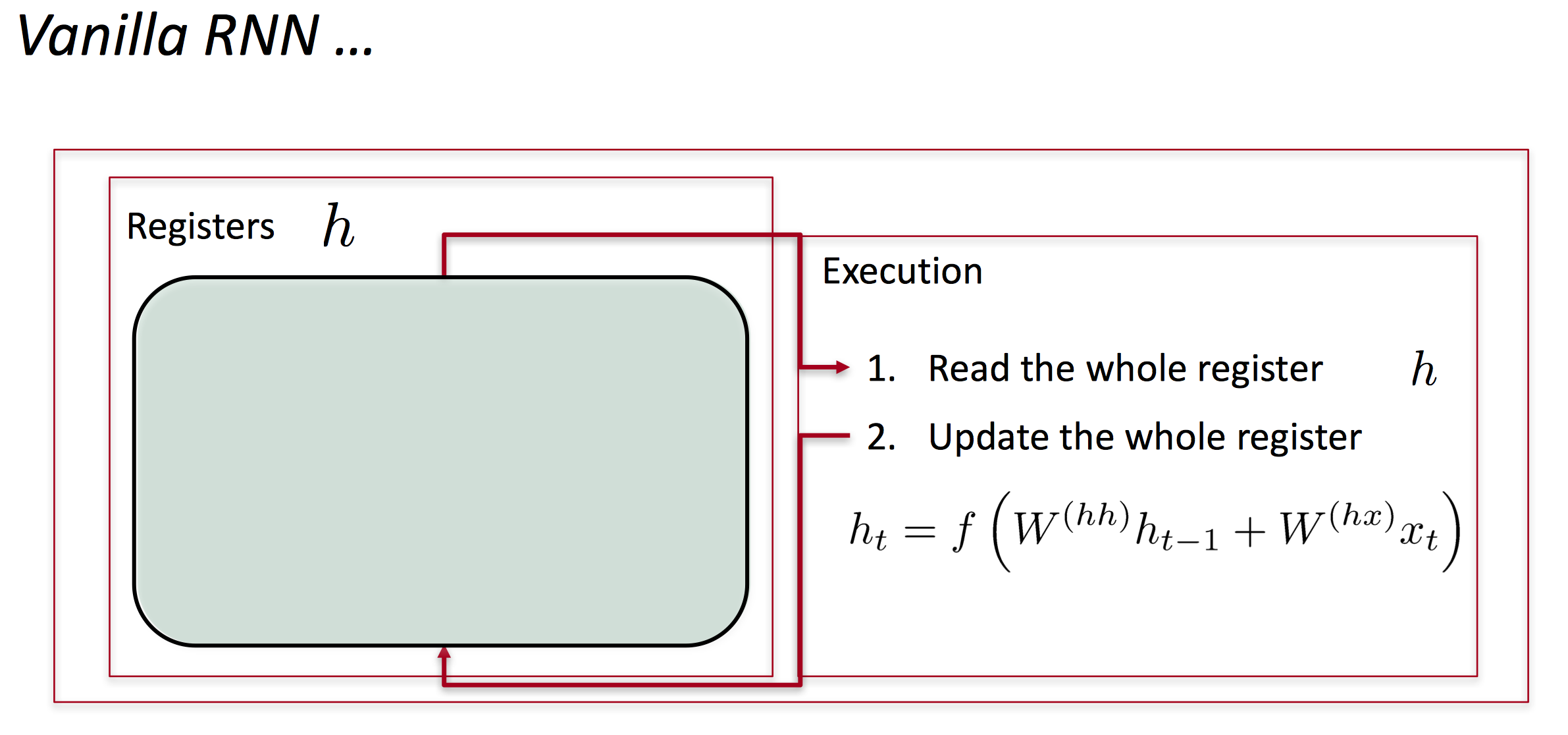
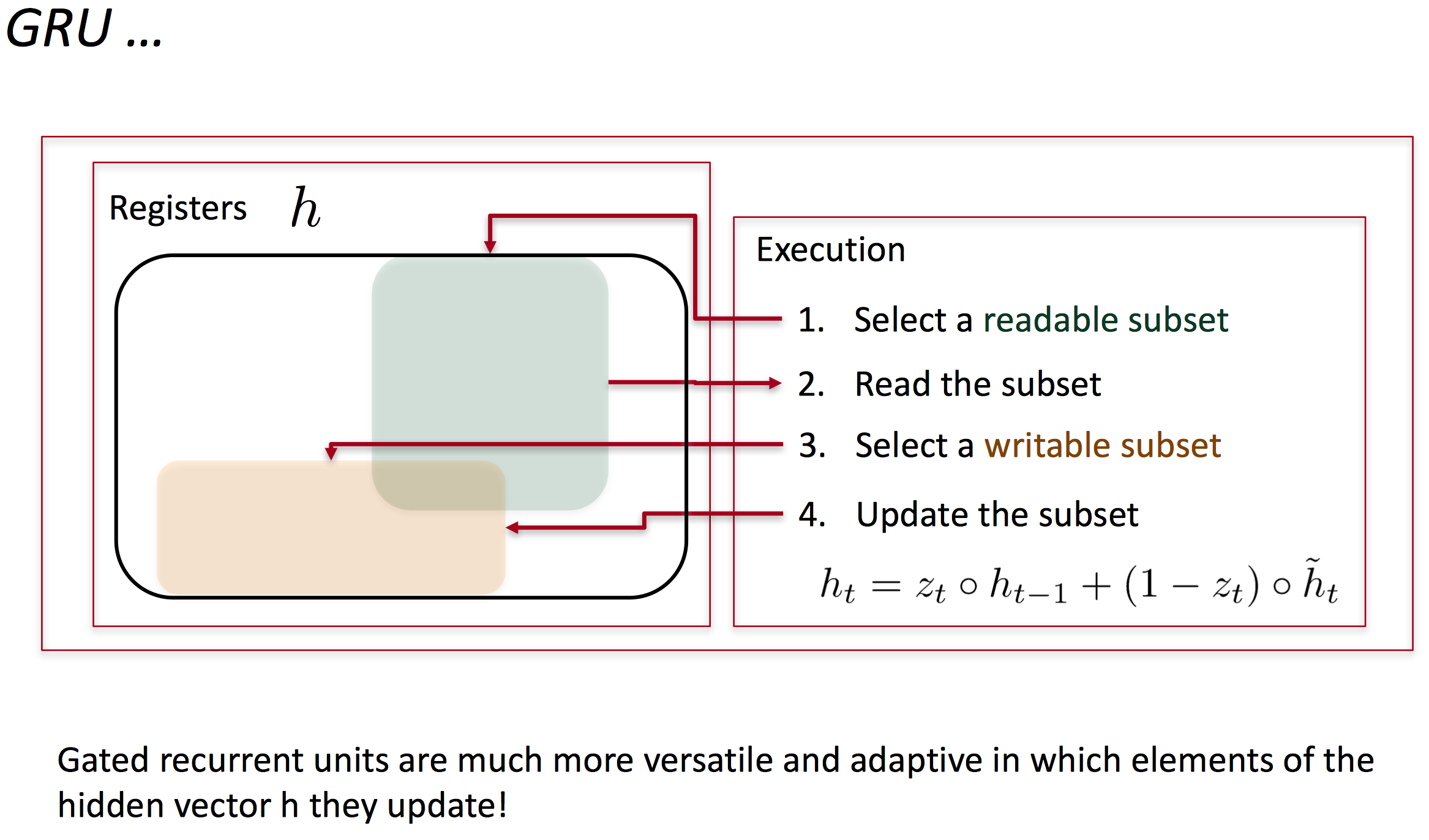
Long-short-term-memories (LSTMs)
LSTM是一个比GRU更复杂的RNN模型,它允许修改每一个时间节点。
-
Input gate
-
Forget
-
Output
-
New memory cell
由此得到的最终memory cell为:
最终的隐藏层状态为:
LSTM模型的可视化如下
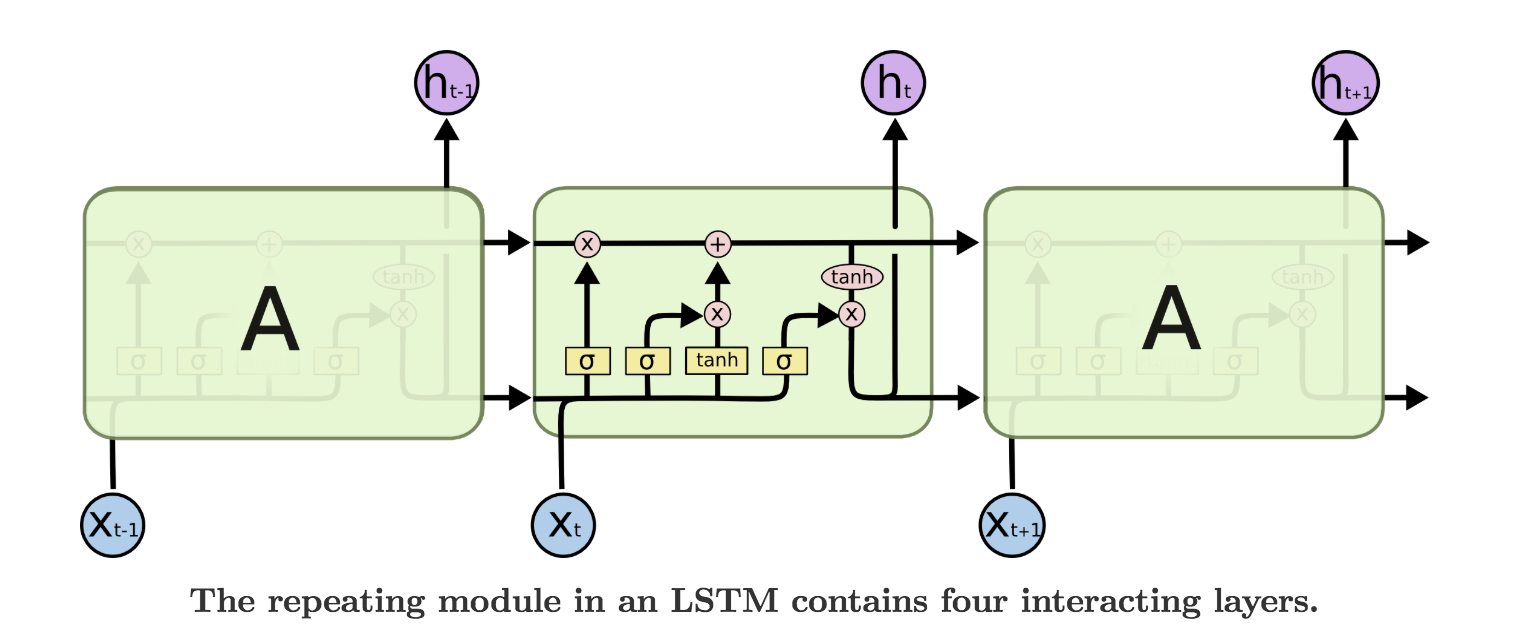

图片来自Understanding LSTMs,推荐阅读。
LSTM可以作为所有序列问题的优秀模型
- 非常powerful,特别是网络更深时。
- 对于大量数据很有用
Bidirectional RNNs (双向RNN)
文本分类时,我们同时需要前后文,因此使用双向RNN可以同时存储前后文信息。
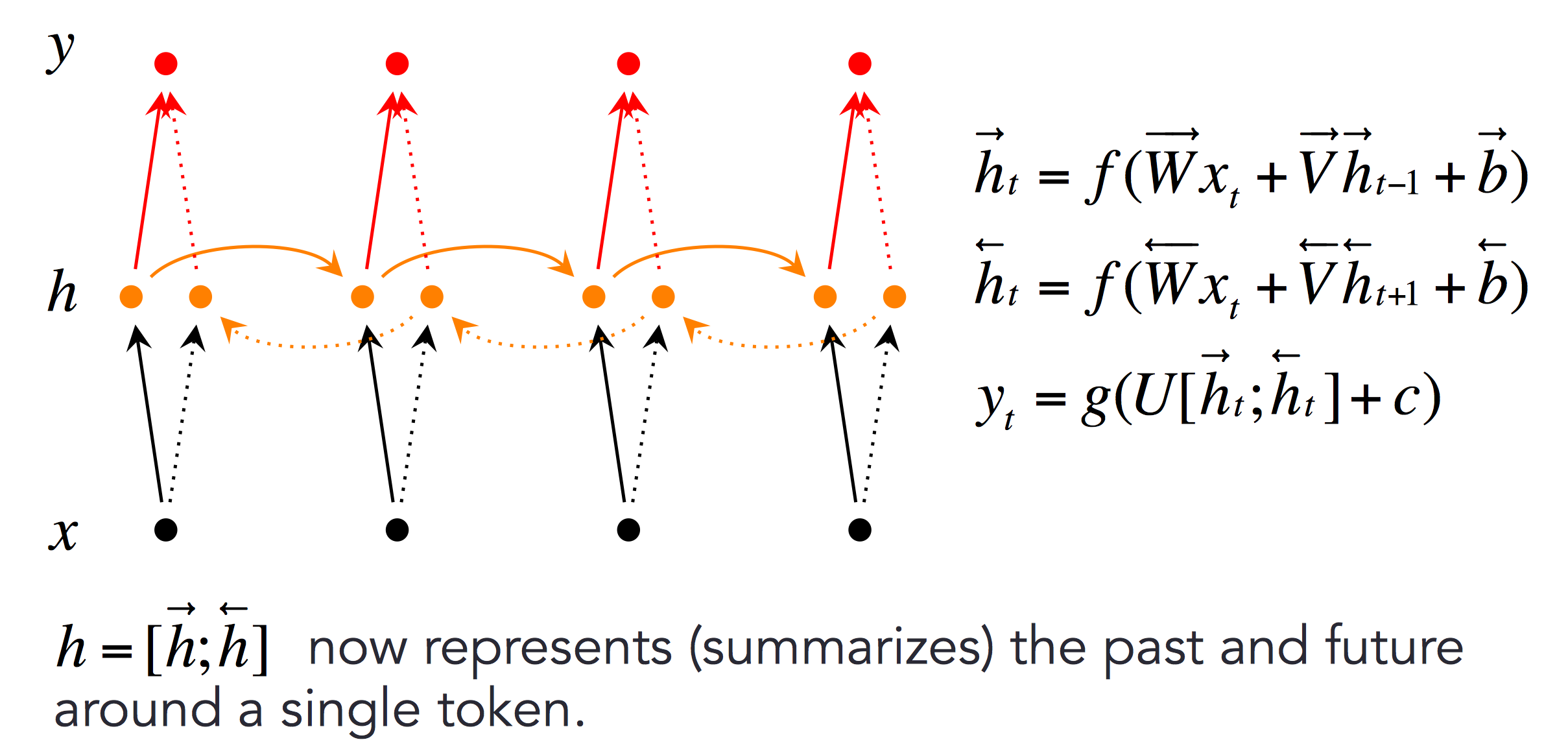
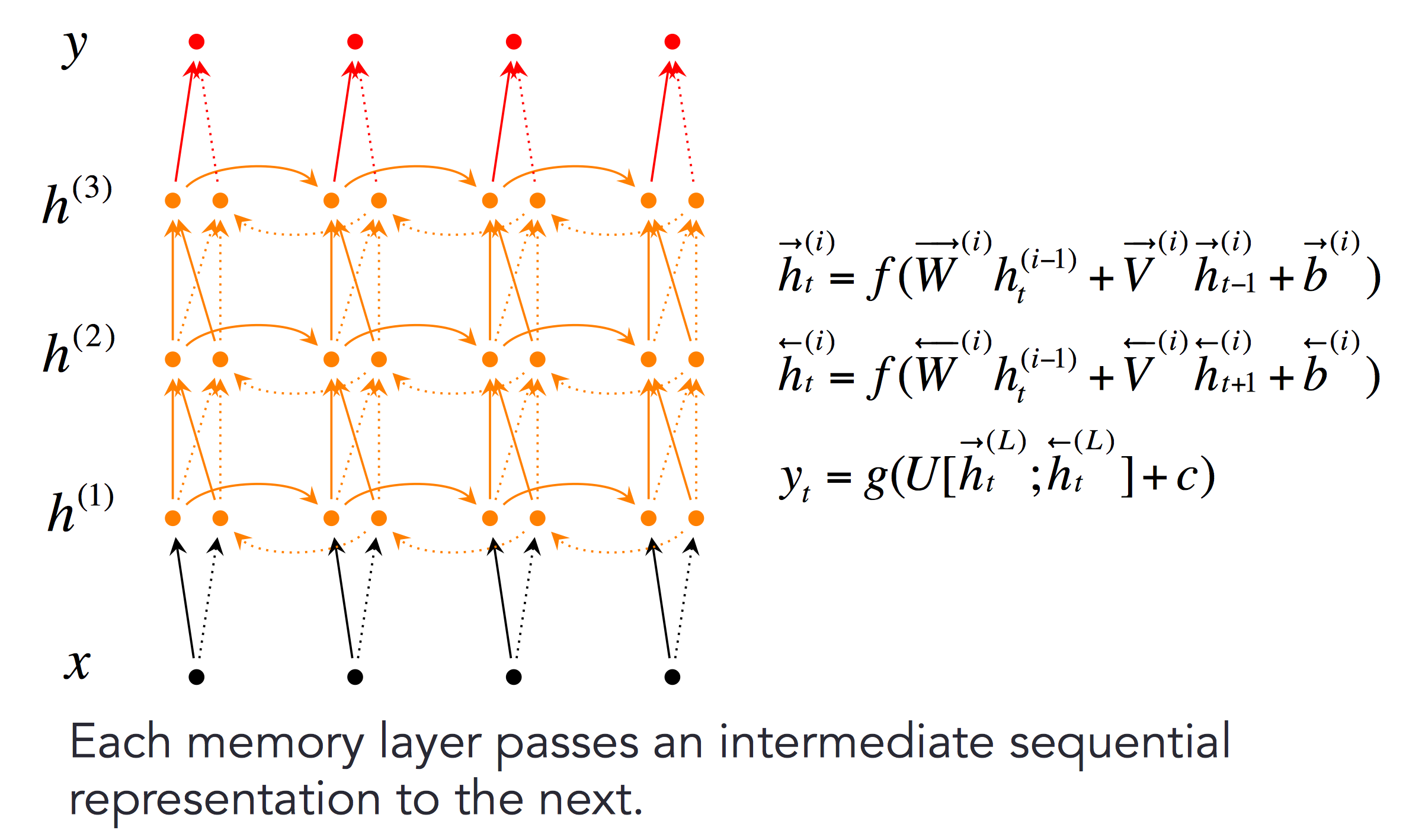
更深层的双向RNN如下:

-
Midterm Review
-
-
Lecture10 - Machine Translation, Sequence-to-sequence and Attention
机器翻译、seq2seq模型和注意力机制
到这里,课程已经过半了,剩余的课程几乎都是由项目驱动,我们将会学到NLP+DL的研究前沿。课程也会变得更高层:不再有梯度计算、有时我们只会对一些知识做概述。
这次的课程包含NLP深度学习的两项核心技术——seq2seq & Attention
Machine Translation
机器翻译是将一个语言的句子翻译成另一语言的任务。
例如将I love machine learning.翻译成我爱机器学习。早期机器翻译
早期的机器翻译更多的是基于语言规则、使用词典来构建。
1990s-2010s: Statistical Machine Translation
90年代到2010年左右,机器学习多基于统计。
传统统计机器翻译的核心思路是:从数据中学习一个概率模型,使用贝叶斯找到概率最大的句子:其中P(x|y)为翻译模型,指导词和短语翻译,训练数据为双语数据。P(y)为语言模型,指导如何写出好的翻译句子,训练数据为目标翻译语言。
那么,我们如何学习一个P(x|y)模型呢?
首先,我们需要大量的双语模型。
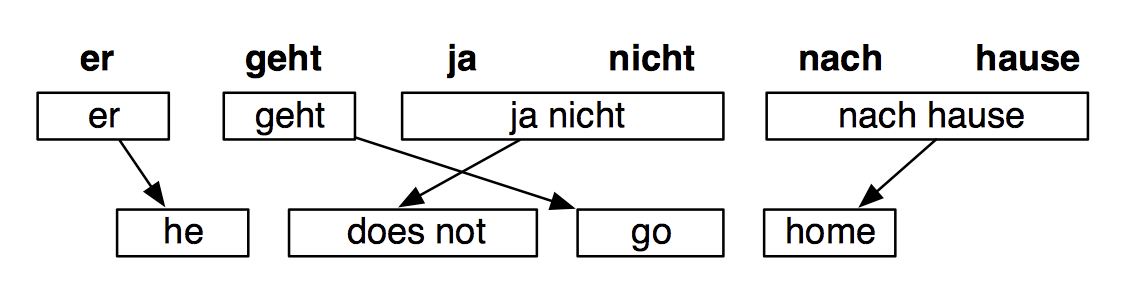
接着,我们需要的翻译模型其实是其中a用于对齐,因为中英文中语言的顺序是不一样的,例如
Chinese eat with chopsticks.的中文为中国人用筷子吃饭,这两句话的词语并不是按顺序对应的。
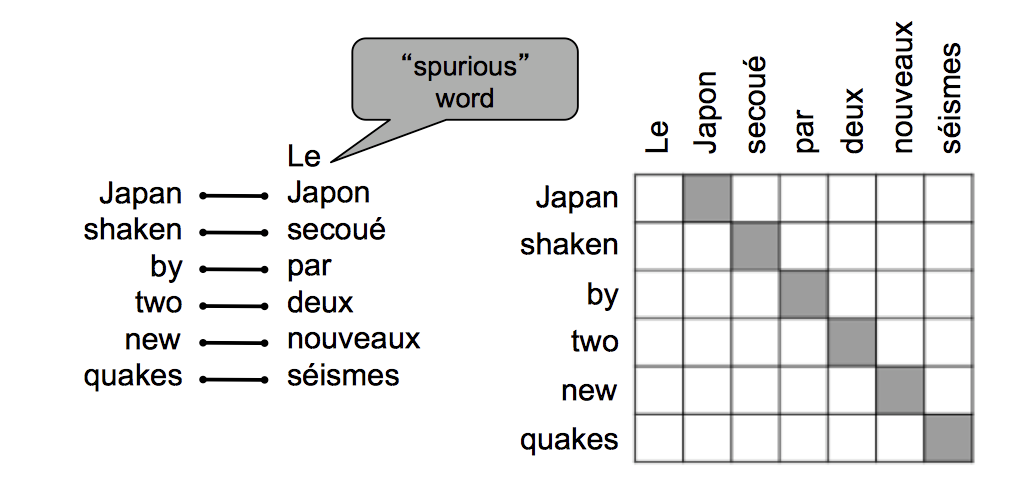
对齐
-
有一些词在另一语言中并没有与它对应的单词
-
有一些词可以翻译为多个词
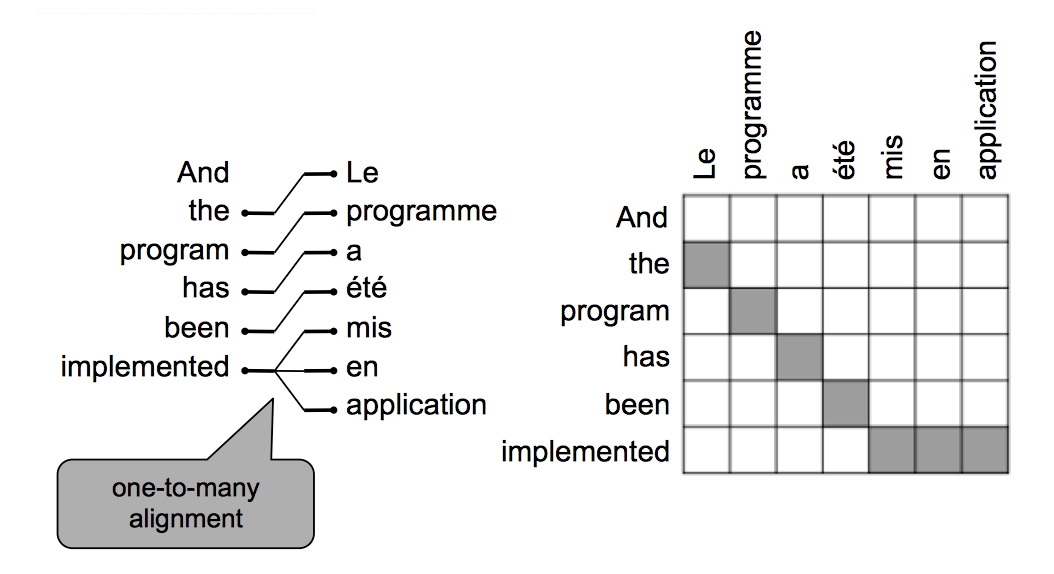
-
也有一些词可以由多个词翻译成
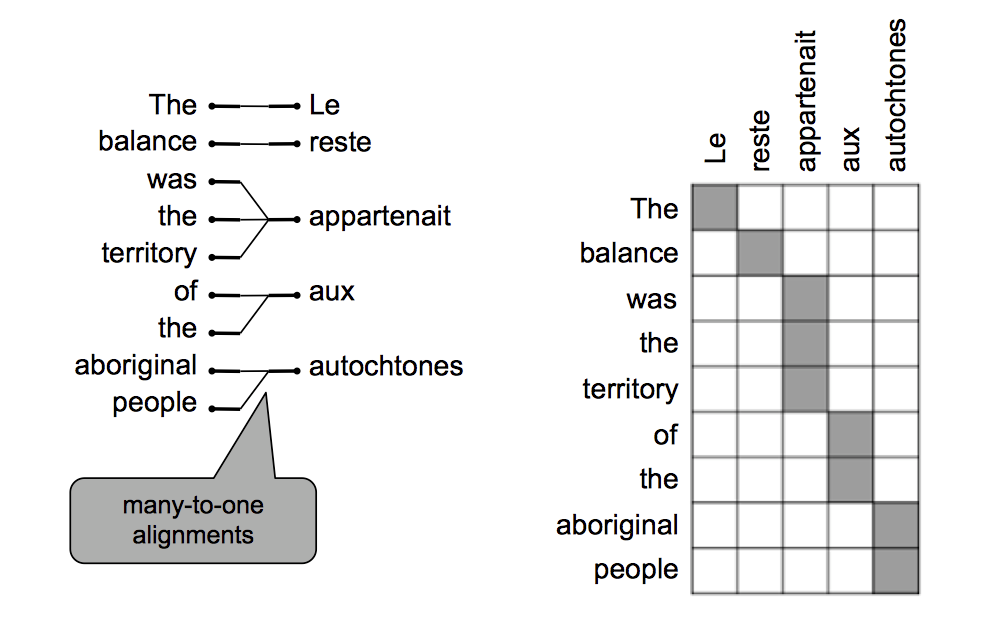
-
甚至有多对多的情况出现
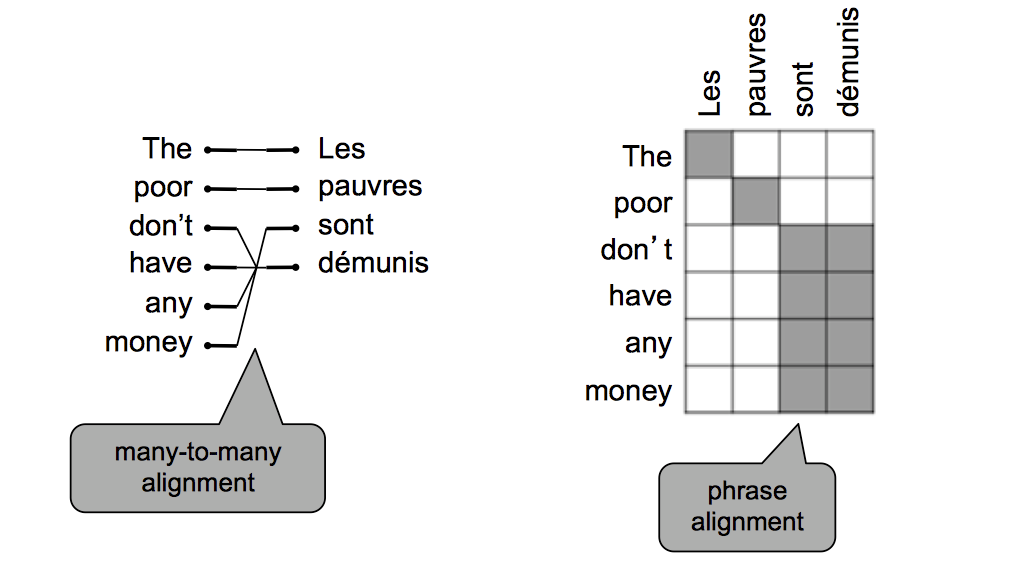
对齐如此复杂,怎么训练一个翻译模型呢?
- 可以举出所有y与x的配对组合然后计算概率吗? -- 当然不行,计算代价太高
我们可以使用一个启发式搜索算法来逐渐构造翻译模型,忽略概率低的假设。
就算这样也会有非常多的组合。
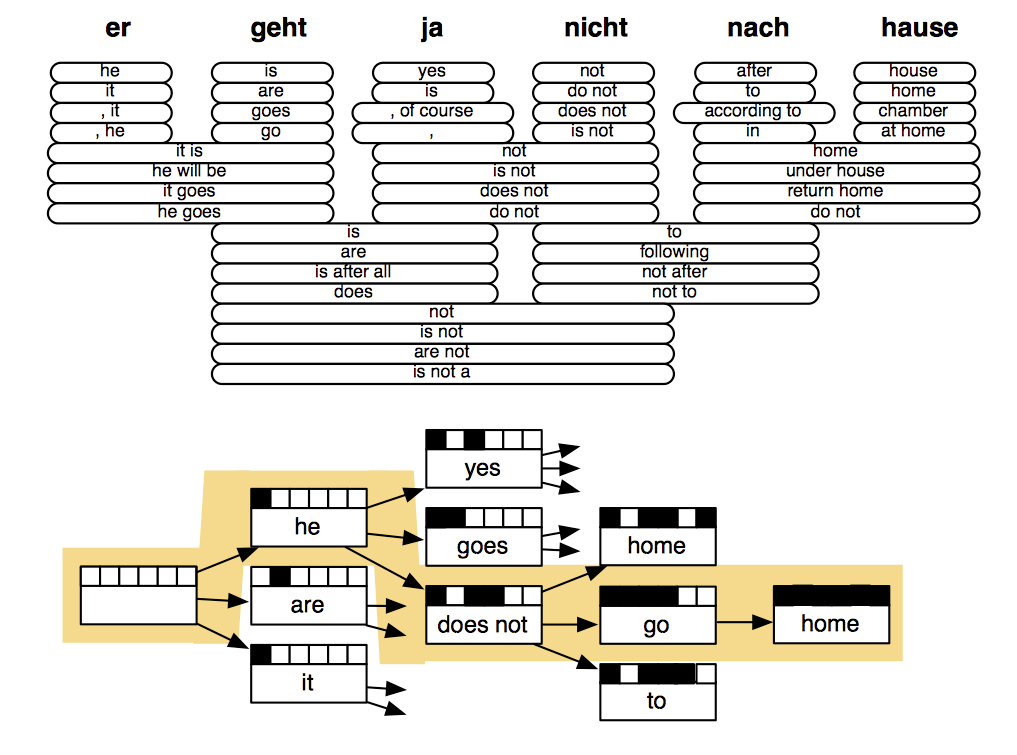
之前的课程中,我们说到用传统机器学习做文本分类很困难,于是出现了深度神经网络。现在在机器翻译中,我们也要喊出同样的一句话:
Oh! Neural Network!

Neural Machine Translation
NMT是一种只使用一个神经网络进行机器翻译的方法。它的神经网络模型叫做sequence-to-sequence(简写为seq2seq),包括两个RNN。
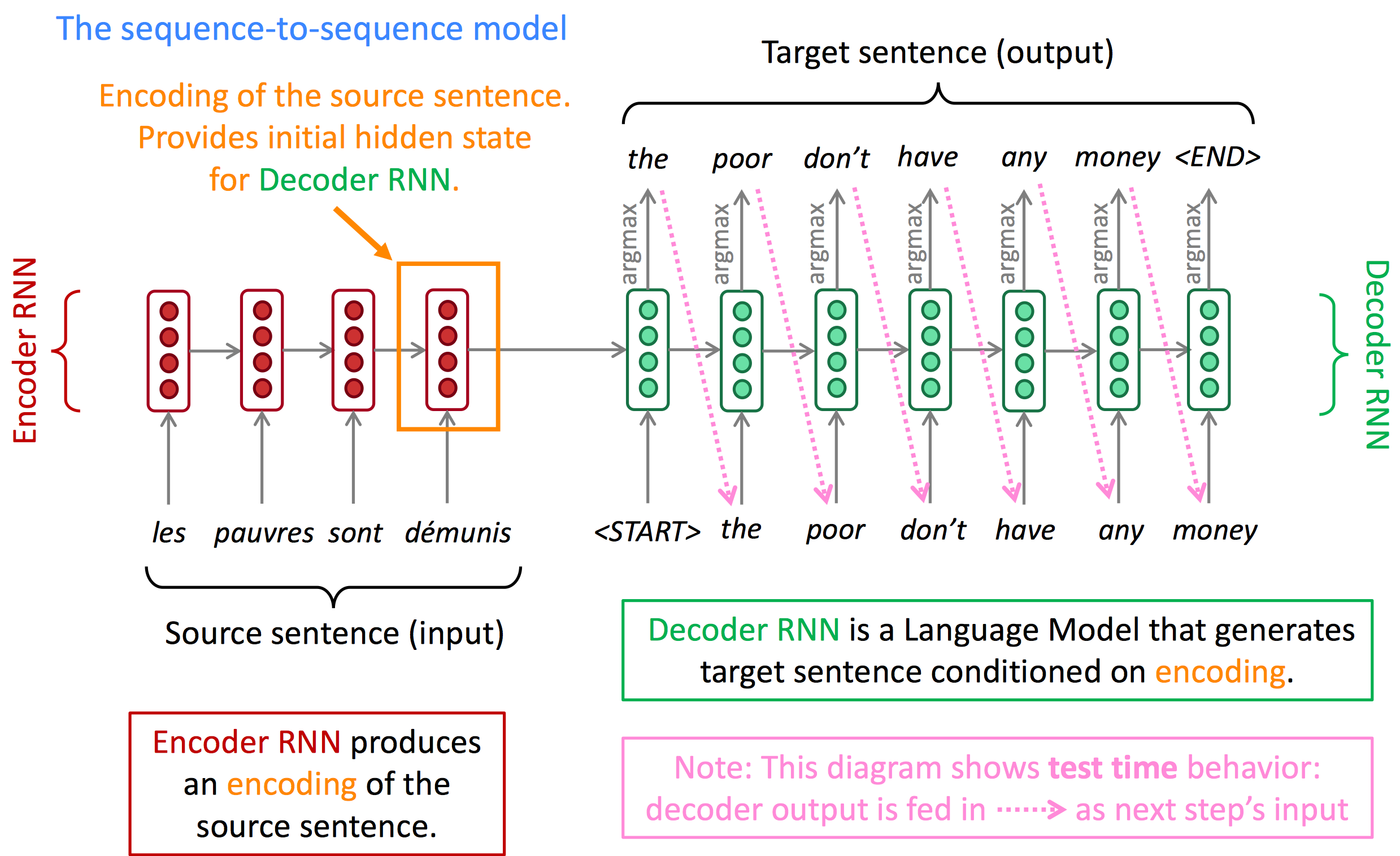
网络由两个RNN组成,
Encoder RNN产生一个对原句子的编码,Decoder RNN通过Encoder RNN的输出编码来产生目标句子。seq2seq是一种条件语言模型(Conditional Language Model):
- decoder用于预测翻译句子的下一个词,因此它属于
Language Model - 由于预测仍然由输入的原句子决定,因此它是有条件的
Conditional

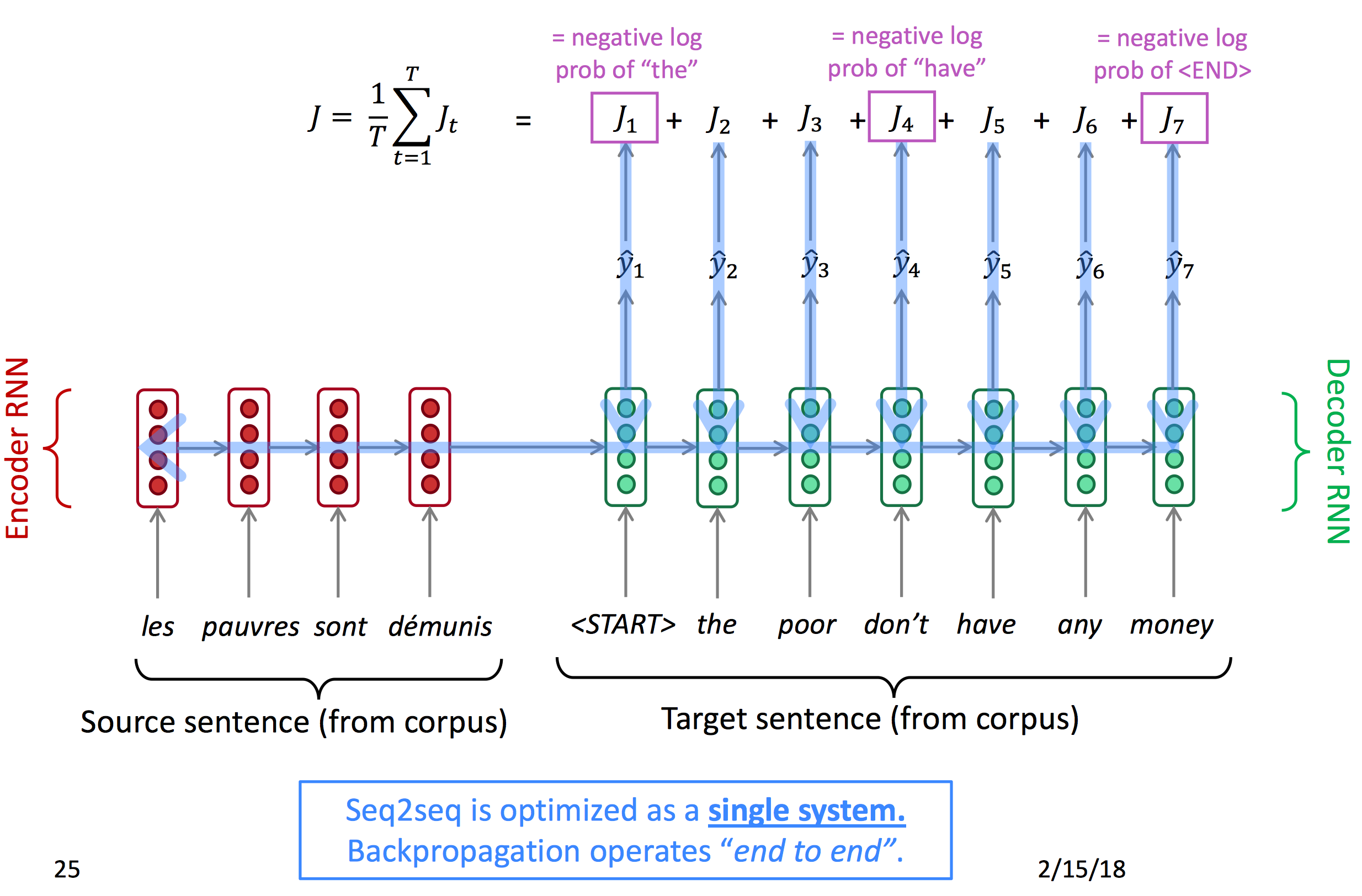
训练一个seq2seq模型
Greedy Decoding
下图所示的就是greedy decoding(将每一部中输出的词都放入翻译结果):
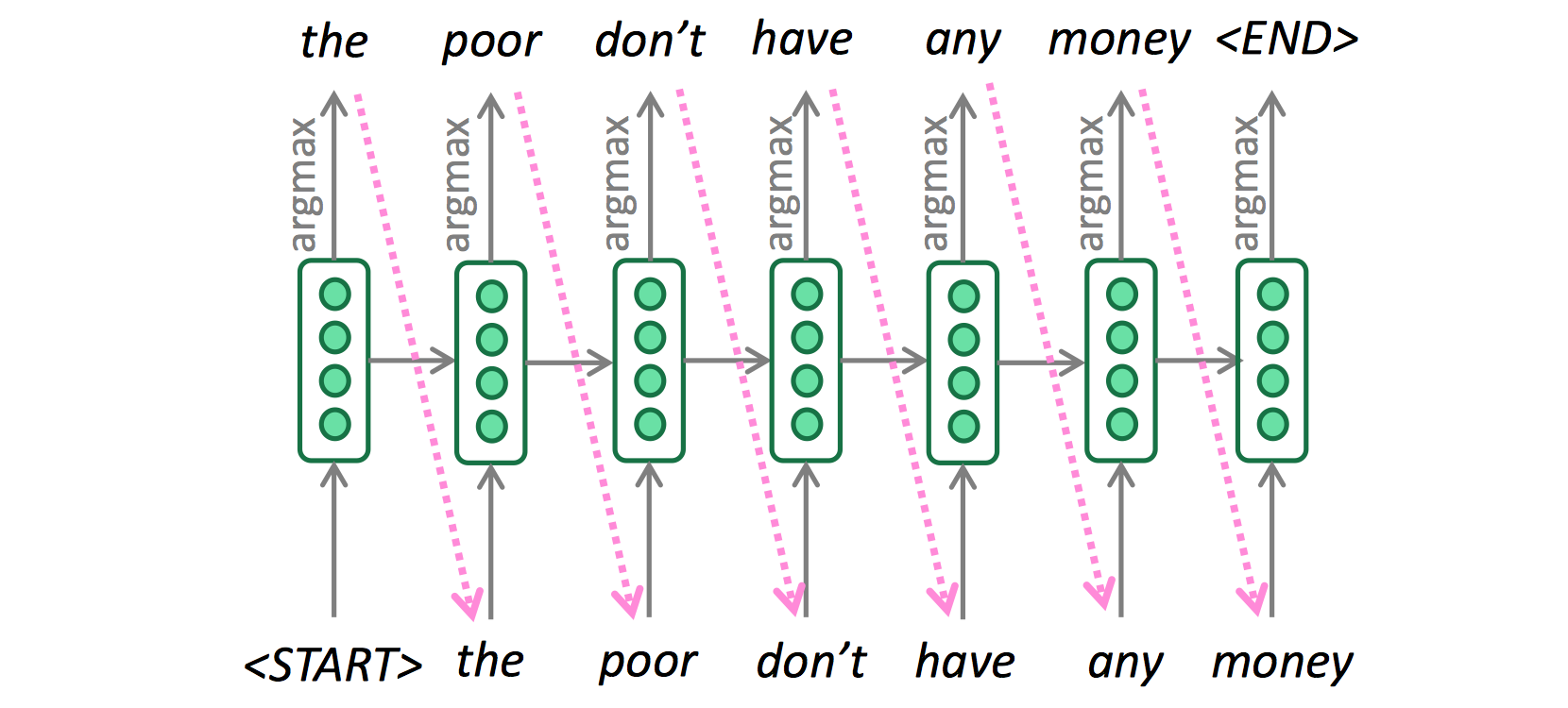
但是这样做是有问题的:
- 不能撤销决定。例如有一句法语
les pauvres sont démunis (the poor don’t have any money),翻译过程如下:- the ___
- the poor___
- the poor
are___
那是否有更好的方式?
=> 使用beam search来寻找几个可能的假设并选出最合适的一个。
Beam search decoding
我们的目的是寻找到可能性最大的y:
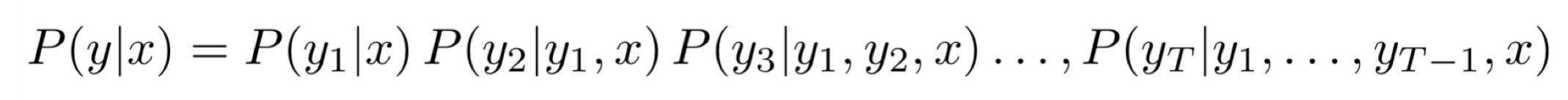
我们可以尝试所有的可能,但是这样开销太大了。
Beam search: 在decoder的每一个时间节点,保持跟踪前k个最可能的翻译部分
k叫做beam size(通常在5-10)- 不保证能找到最佳结果
- 但是要高效得多
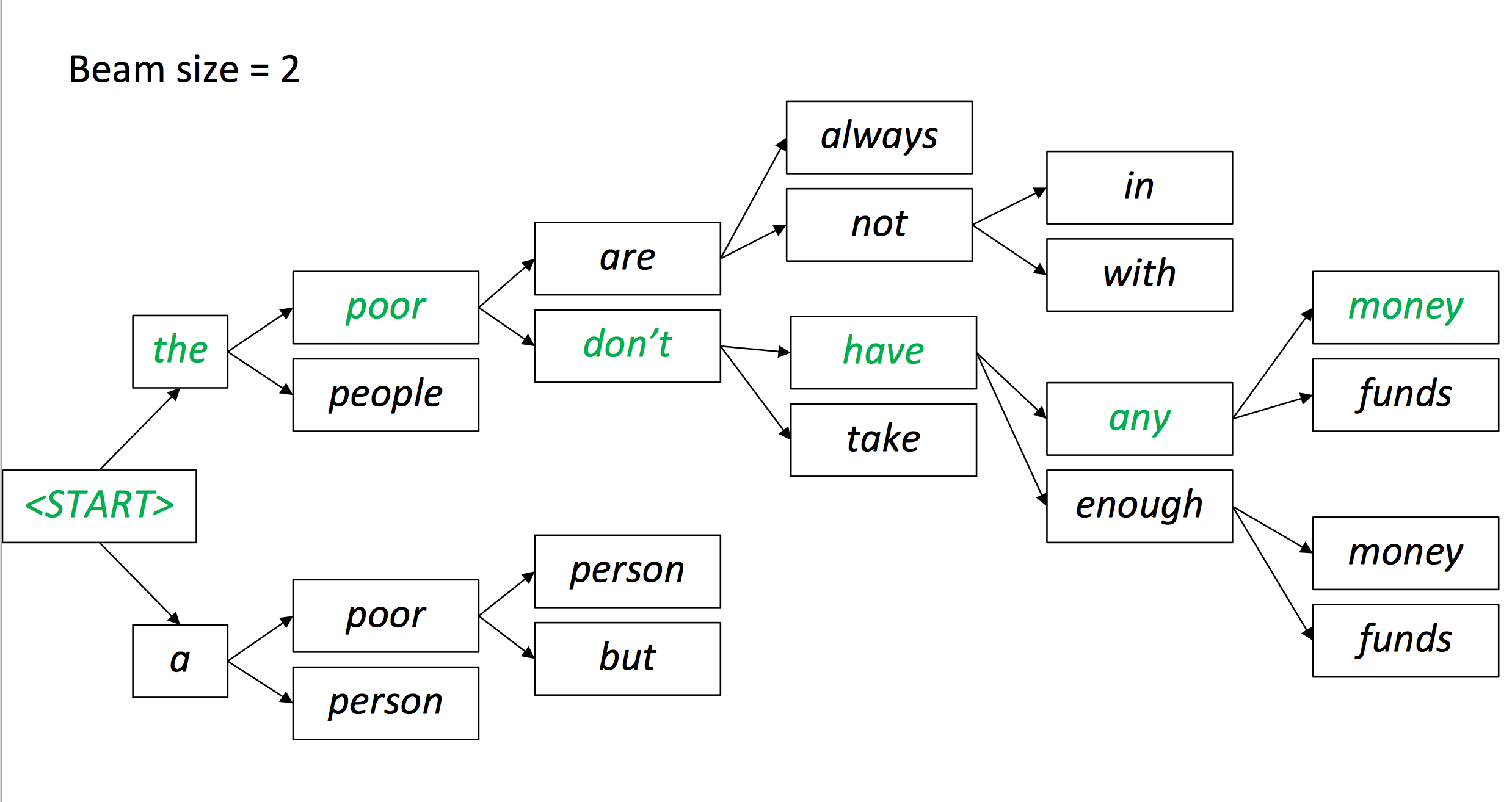
Neural Machine Translation的优点
- 有更好的效果:得到的结果更流畅,对上下文的理解更好,对近义短语的理解更好。
- 只需要一个单一神经网络就可以完成端到端翻译。
- 需要更少的人类工程:不需要特征工程,对所有语言翻译可以使用同样的方法。
NMT的缺点
- 可解释性差:难以debug
- 很难控制NMT的结果:
- 不能轻易地指定翻译规则
- 安全问题
NMT是NLP深度学习中最大的成功
- 2014:第一篇seq2seq论文发表
- 2016:Google翻译从SMT切换到NMT
这样的变化,将每年成百上千工程师构建的SMT切换成了屈指可数的工程师在几个月内即可构建完成的NMT。
那么,机器翻译问题解决了吗?
显然没有!机器翻译仍然有许多问题需要解决:
- 在词典外的词
- 训练和测试数据的领域不同
- 长文本语境的保留
- 数据量少的翻译语料

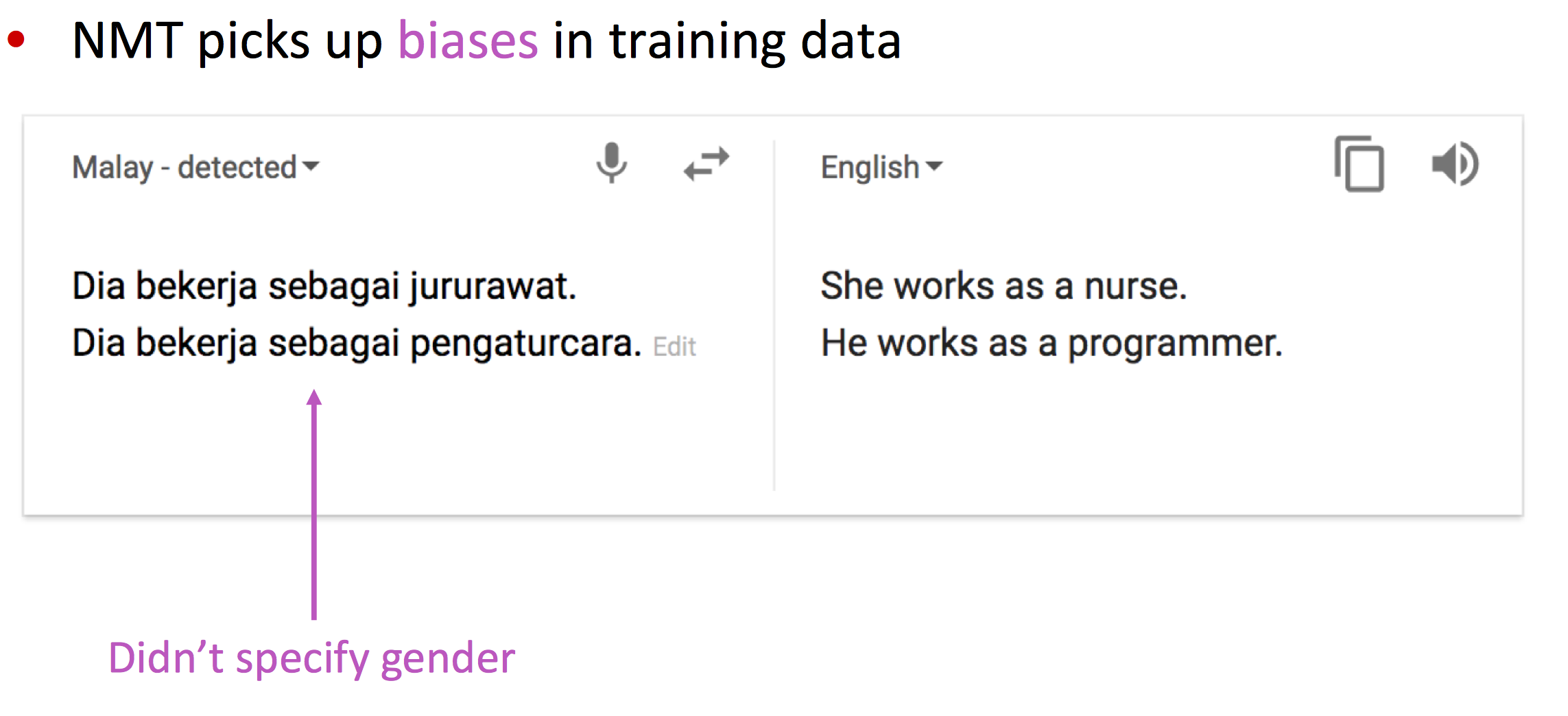
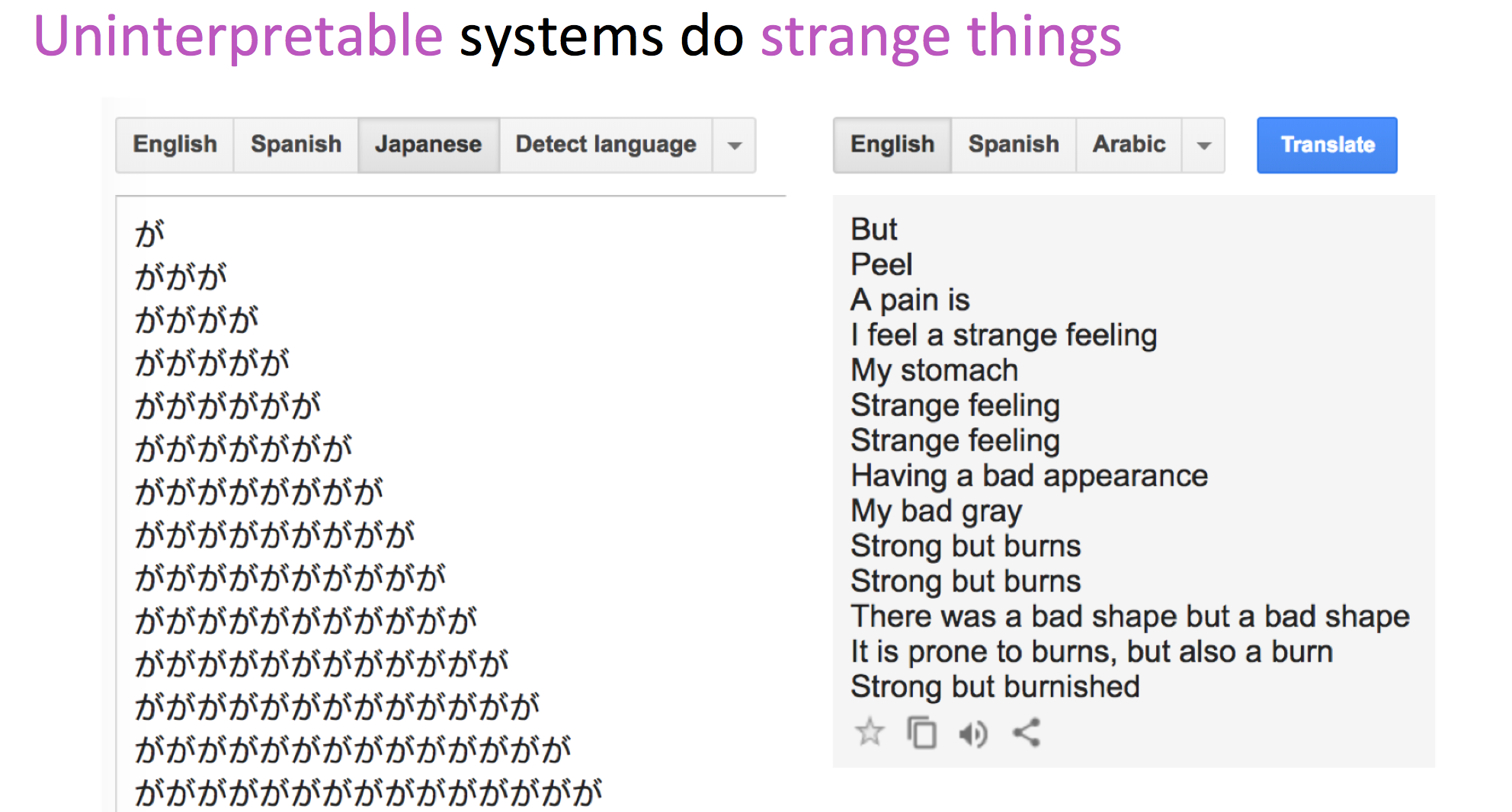
2017年,在机器翻译领域有一篇重磅论文,Attention Is All You Need
下面介绍机器翻译邻域新的改进方法:注意力机制ATTENTION
seq2seq的瓶颈
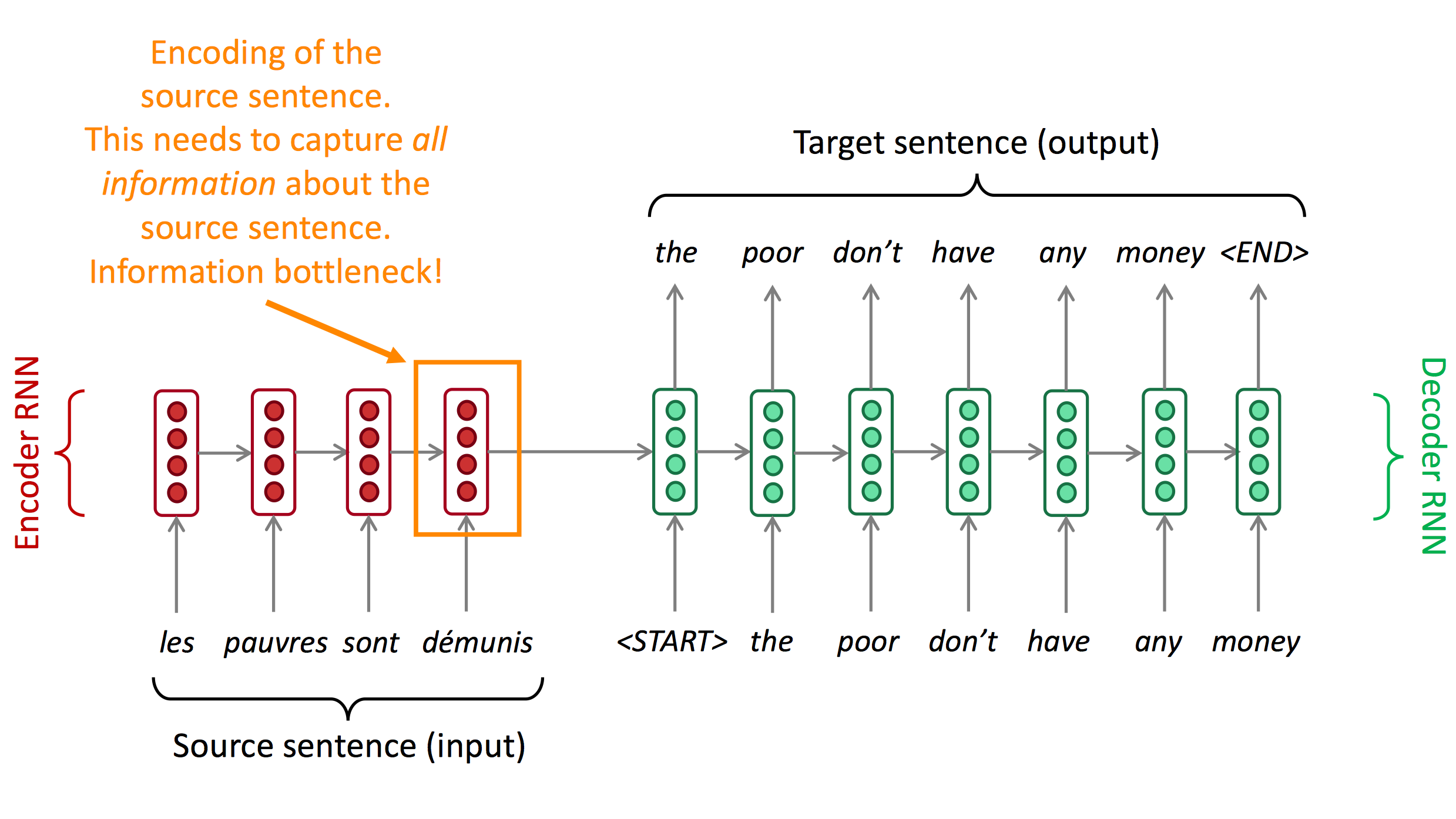
Encoder需要捕捉原句子中的所有信息 - 信息瓶颈。
Attention
注意力机制提供了对于信息瓶颈的解决方案。它的核心思想是:在decoder的每一个时间节点,只专注于原序列的一个特定部分。
我们先使用图表的形式了解attention:
Attention首先对encoder输出的每一个节点计算一个attention score,再使用softmax得到每个点的概率(Attention distribution),由概率得到注意力输出,与decoder的hidden state结合得到当前输出。以下为decoder每一时间节点的状态图。
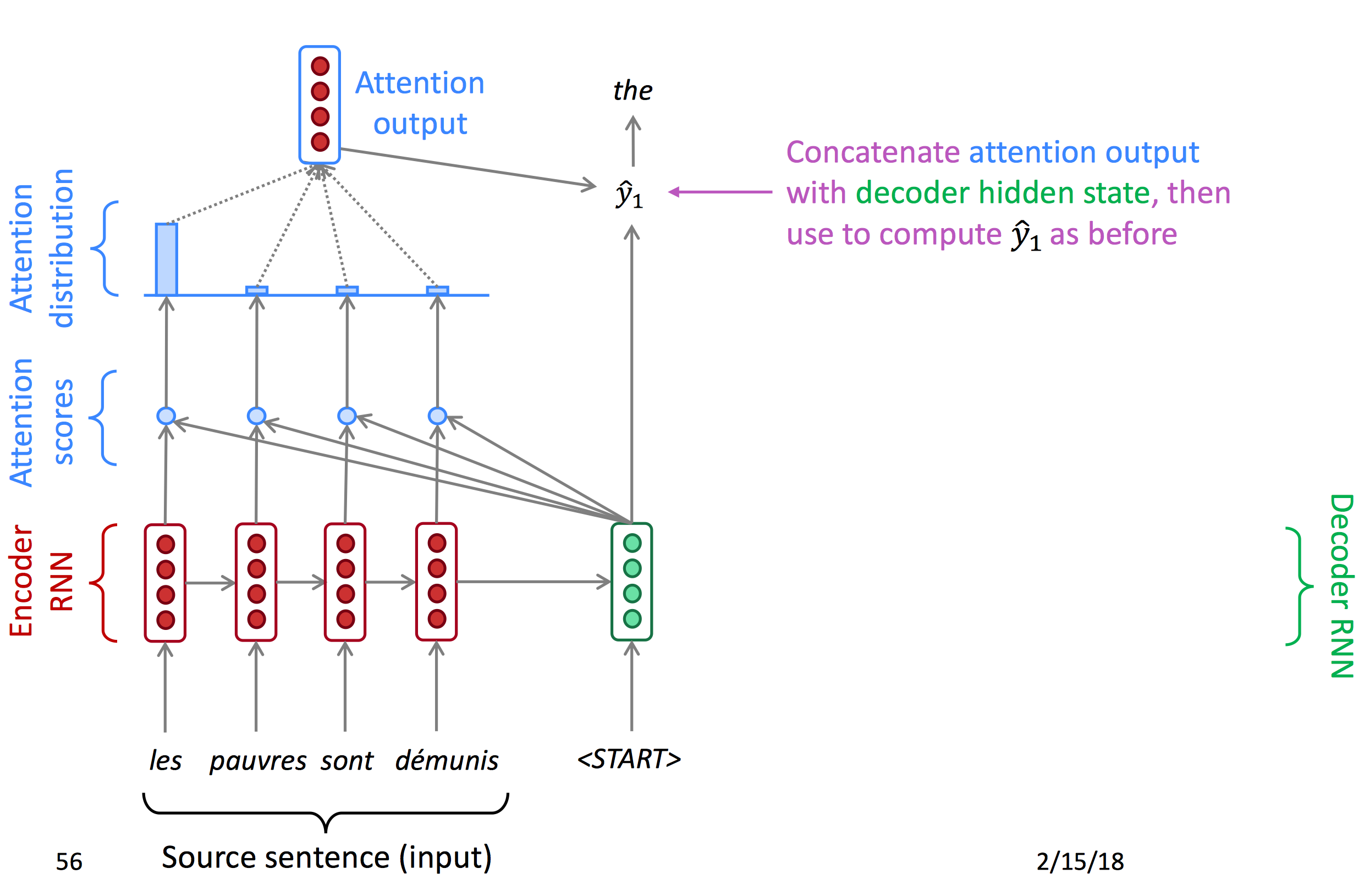
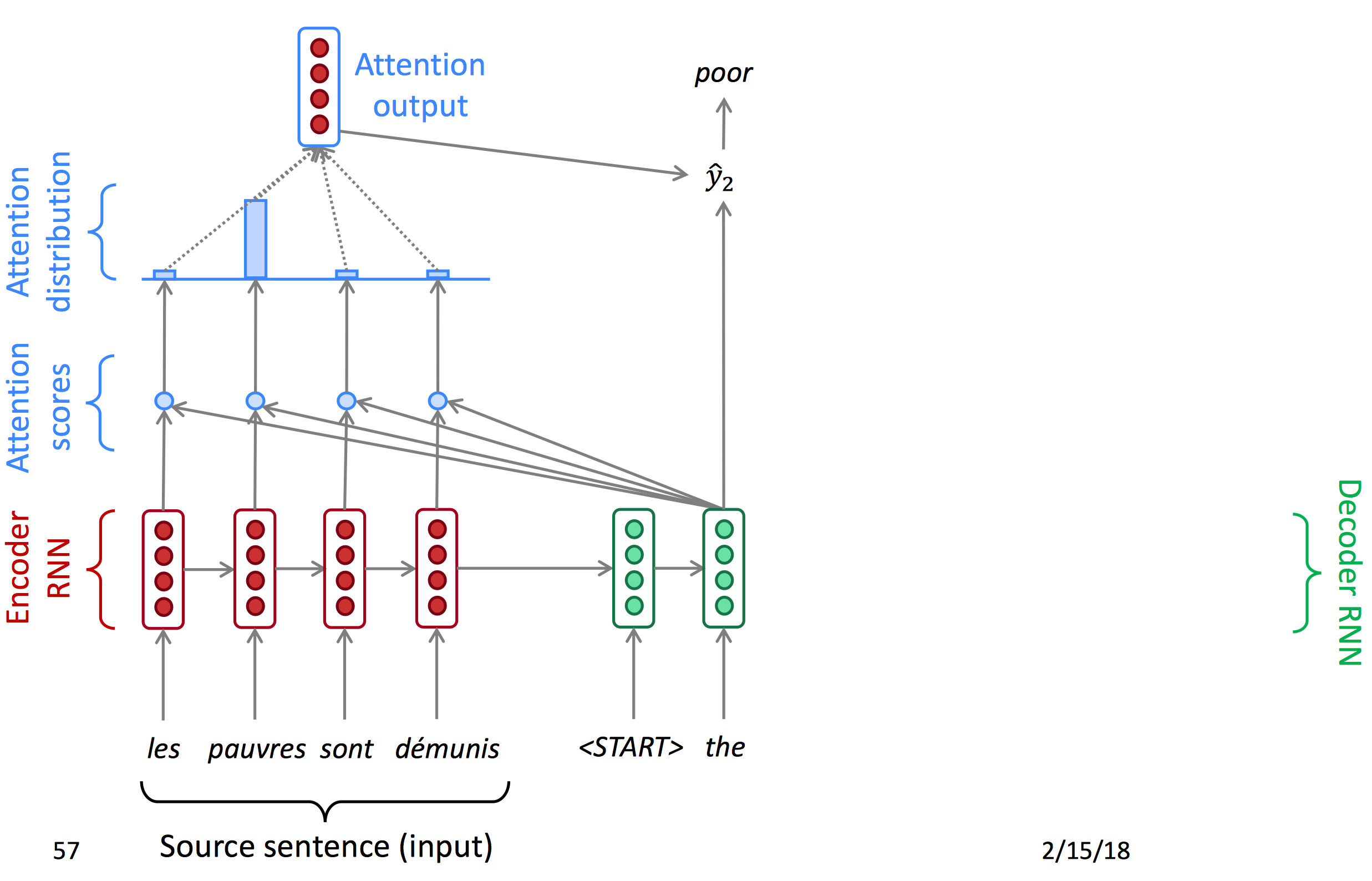
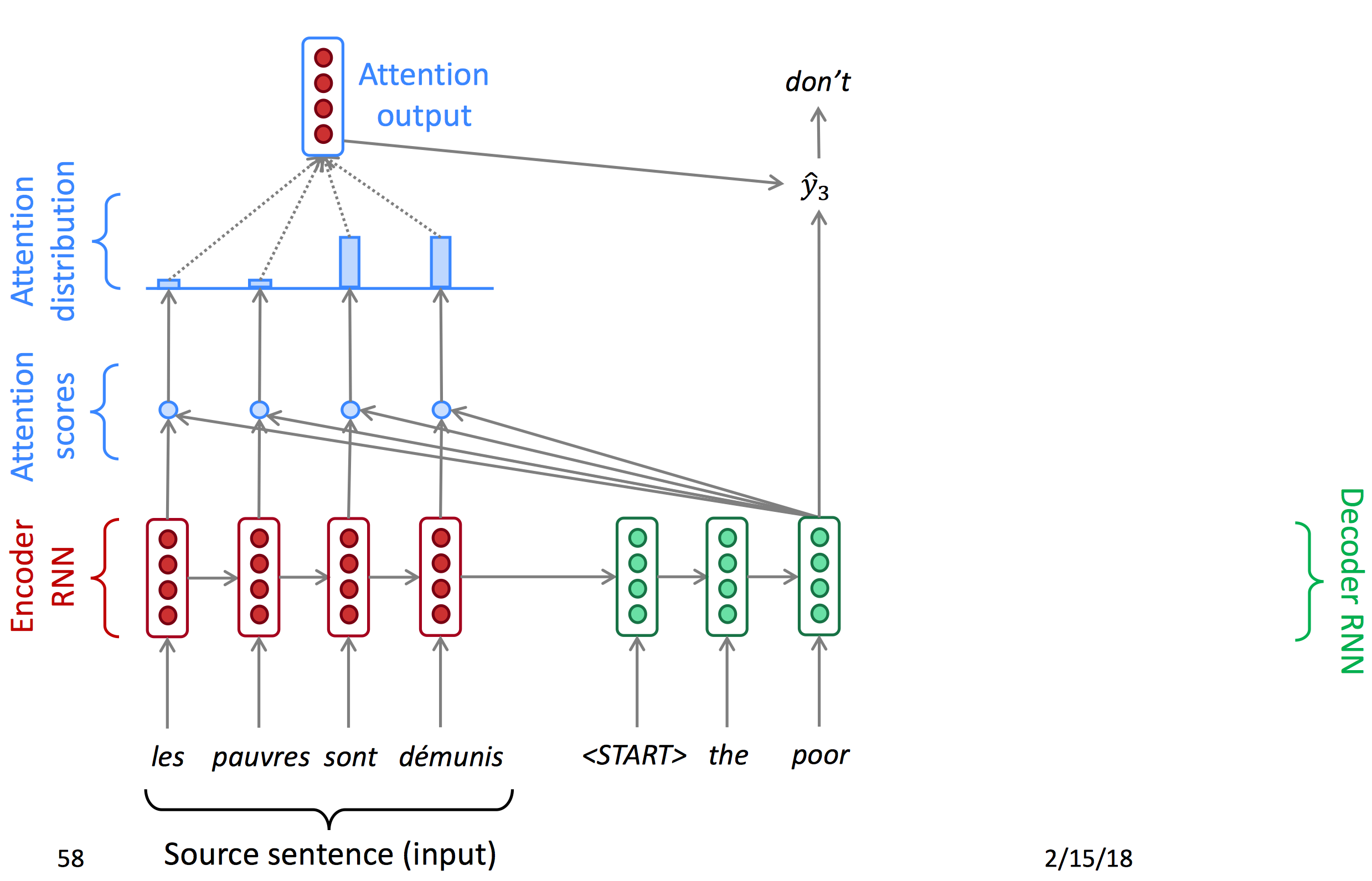
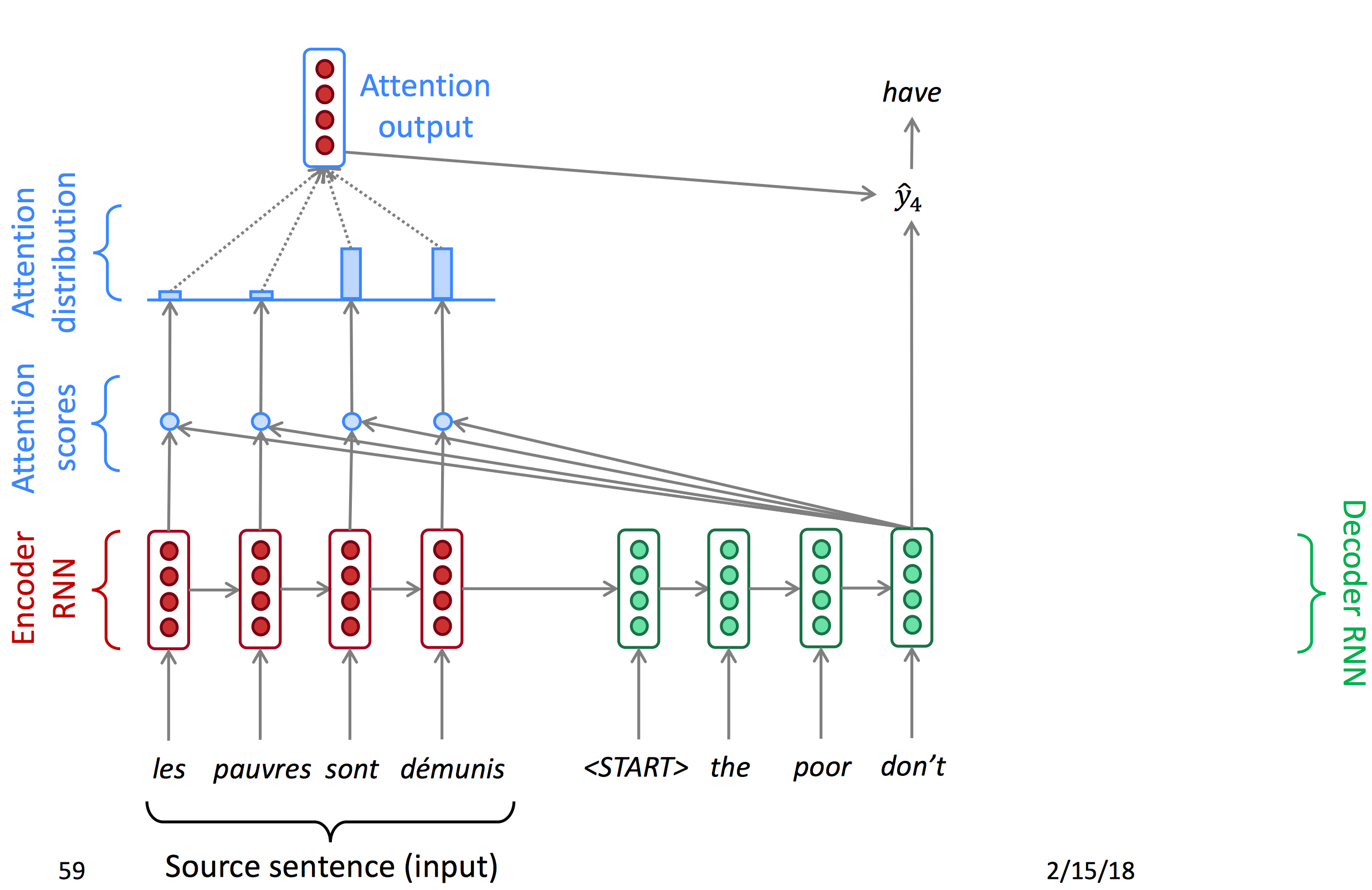
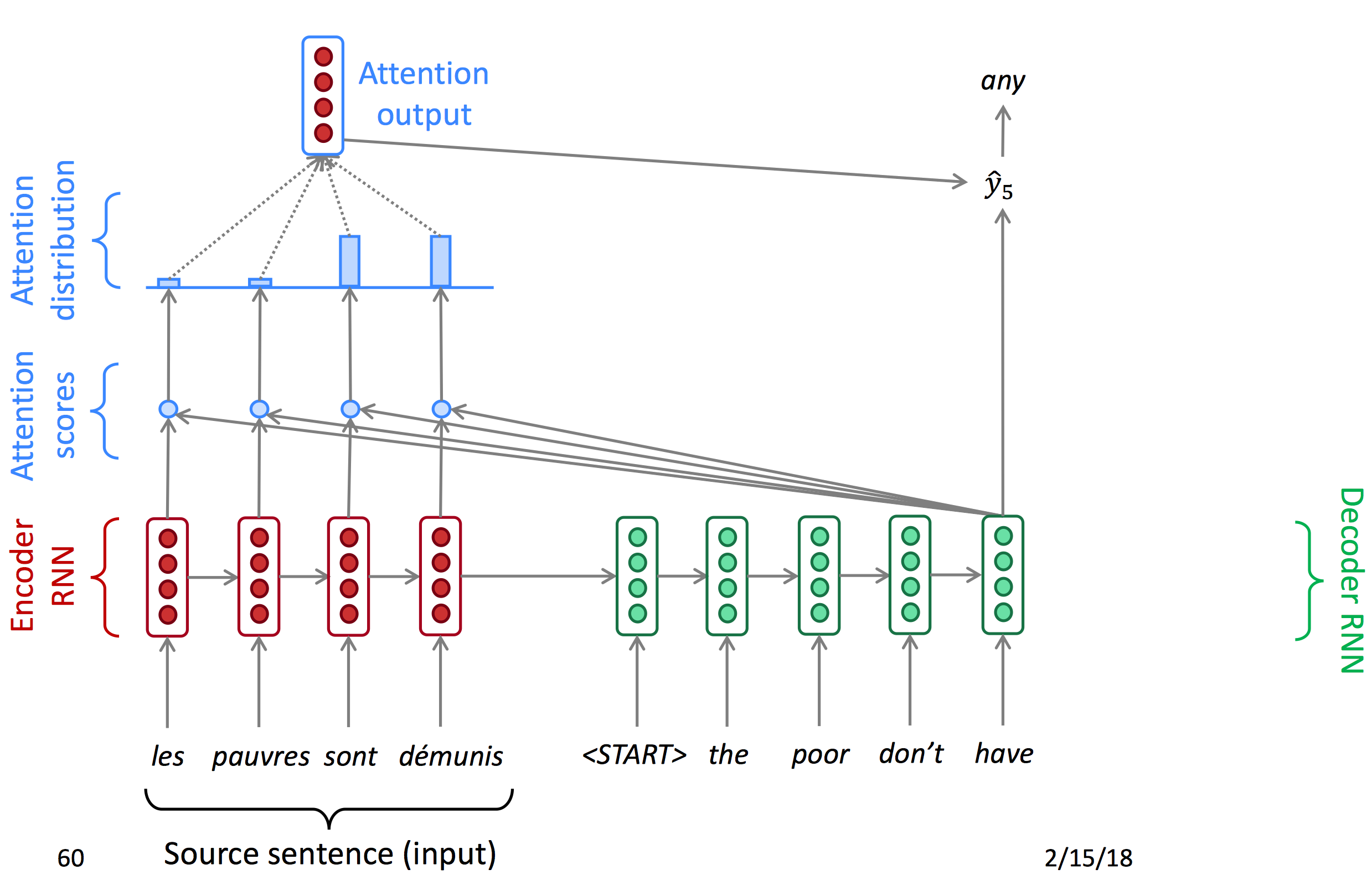
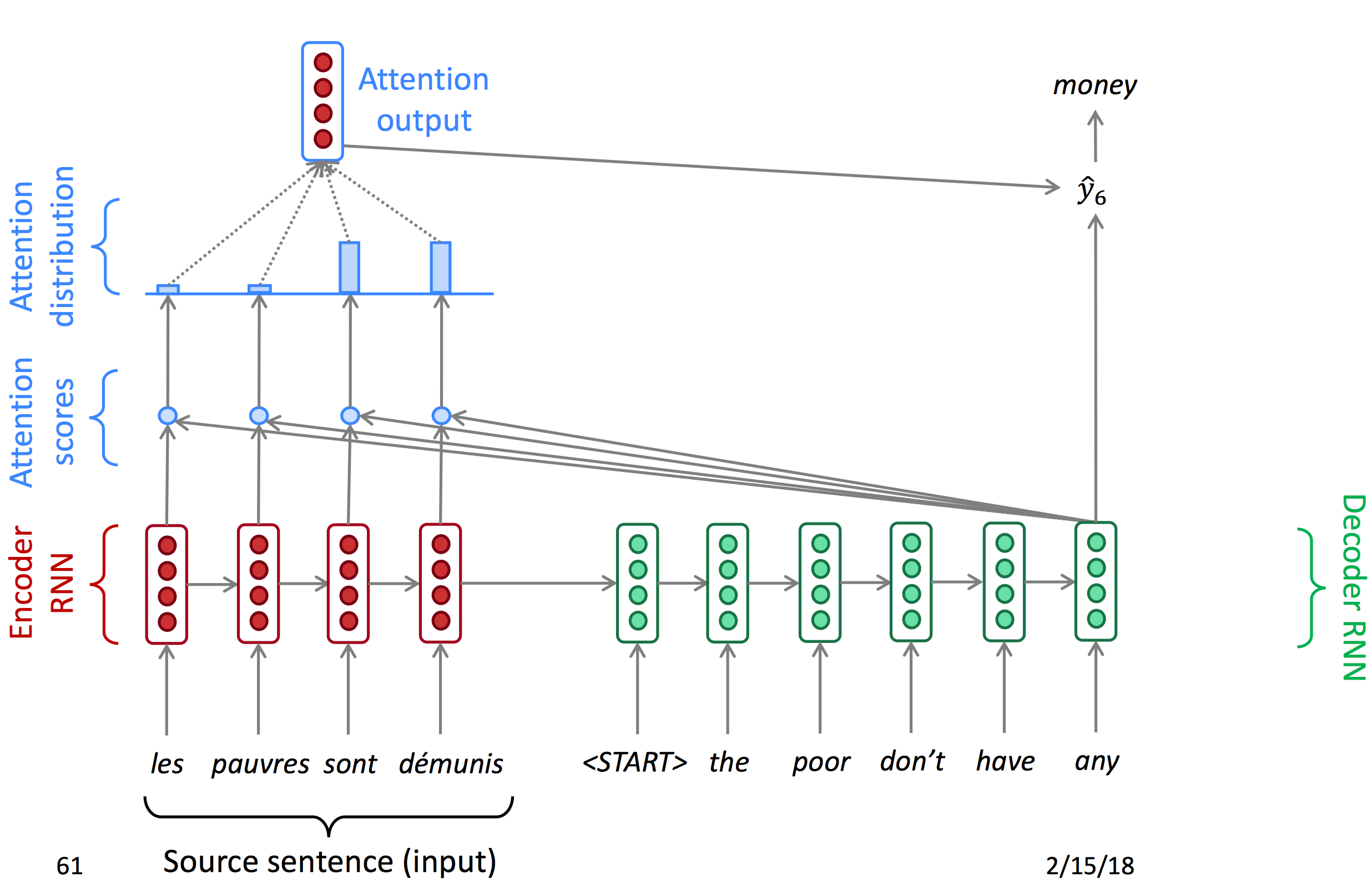
下面为公式:
- 隐藏状态
- 在时间节点t,有decoder隐藏状态
- 在这一节点,有attention scores:
- 给attention score套一层softmax得到attention distribution
- 用
乘以对应的encoder的hidden states来计算输出的a_t
- 最后将a_t与s_t concat到一起
Attention 的优点
- Attention对NMT的效果有重大提升
允许decoder专注于确定的部分很有用 - Attention解决了NMT的瓶颈
Attention允许decoder直接观察到原句子,解决了瓶颈 - Attention对缓解梯度消失有帮助
提供了到达很远的状态的捷径 - Attention有一定的可解释性
- 我们可以通过attention distribution看到decoder正在关注什么
- 我们通过attention直接得到了对齐信息
- 这一点很酷,因为我们从没有明确地训练一个对齐系统
- 网络自己学到了对齐
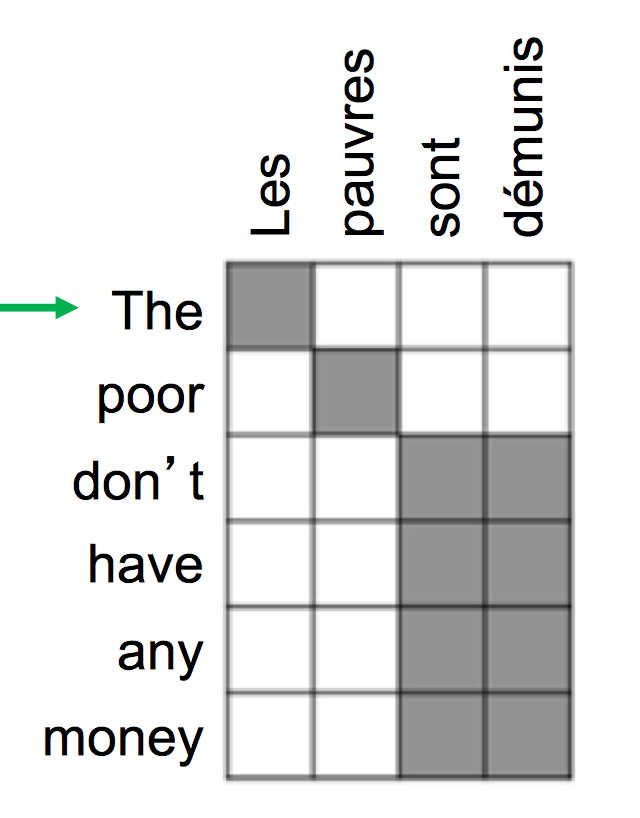
seq2seq用途广泛
seq2seq不只是适用于机器翻译,在很多领域也有很好的效果:
- Summarization (long text -> short text)
- Dialogue (previous utterances -> next utterance)
- Parsing (input text -> output parse as sequence)
- Code generation (natural language -> Python code)
-
-
Lecture11 - Paying attention to attention and Tips and Tricks for large MT
Attention是一项通用的深度学习技术,它不仅应用于seq2seq中,今天我们还将介绍attention的更多应用。
Attention
Attention是一个根据输入向量序列计算元素的权值的技术。
几种Attention的变体
-
上一课中提到的attention,我们有encoder 隐藏状态
有decoder 隐藏状态query
-
Attention总是从attention scores(e)中计算得到attention output
a,例如:
- 但其实,我们有很多种方式计算attention scores(e)
计算e的几种方式
通过encoder与encoder的hidden states(
, ),我们有以下几种方式计算attention scores: -
基本的点乘attention(Basic dot-product attention)
- 注意这里e和s的向量大小要是相同的
- 我们上节课说的attention就是这种计算方式
-
中间乘上权值矩阵(Multiplicative attention)
为权重矩阵
-
h和s分别乘不同的矩阵后相加(Addictive attention)
- 其中,
, 为权重矩阵, 为权重向量
- 其中,
更多信息,可以查看Deep Learning for NLP Best Practices
Attention的应用:Pointing to words for language modeling
思路:softmax与pointer混合
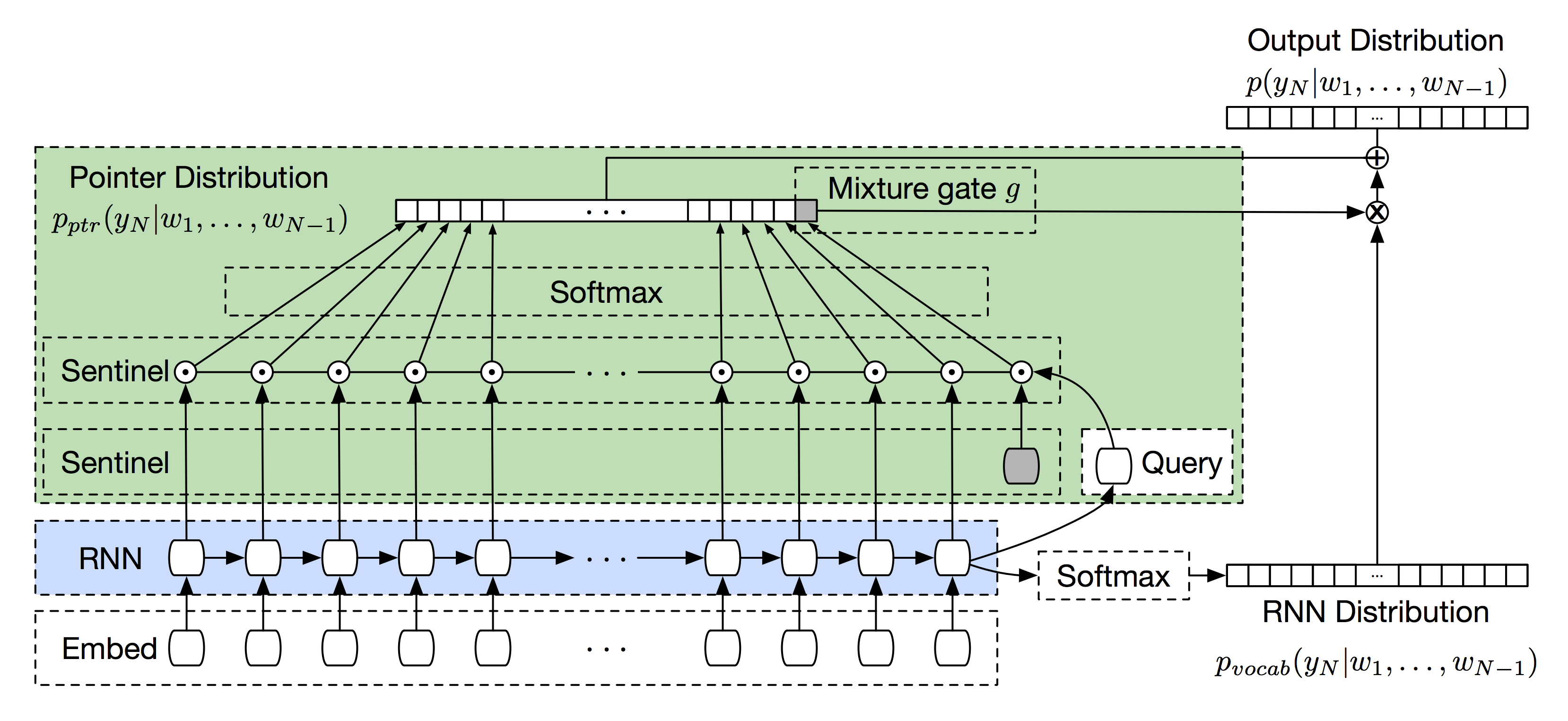
Pointer Sentinel Mixture Models
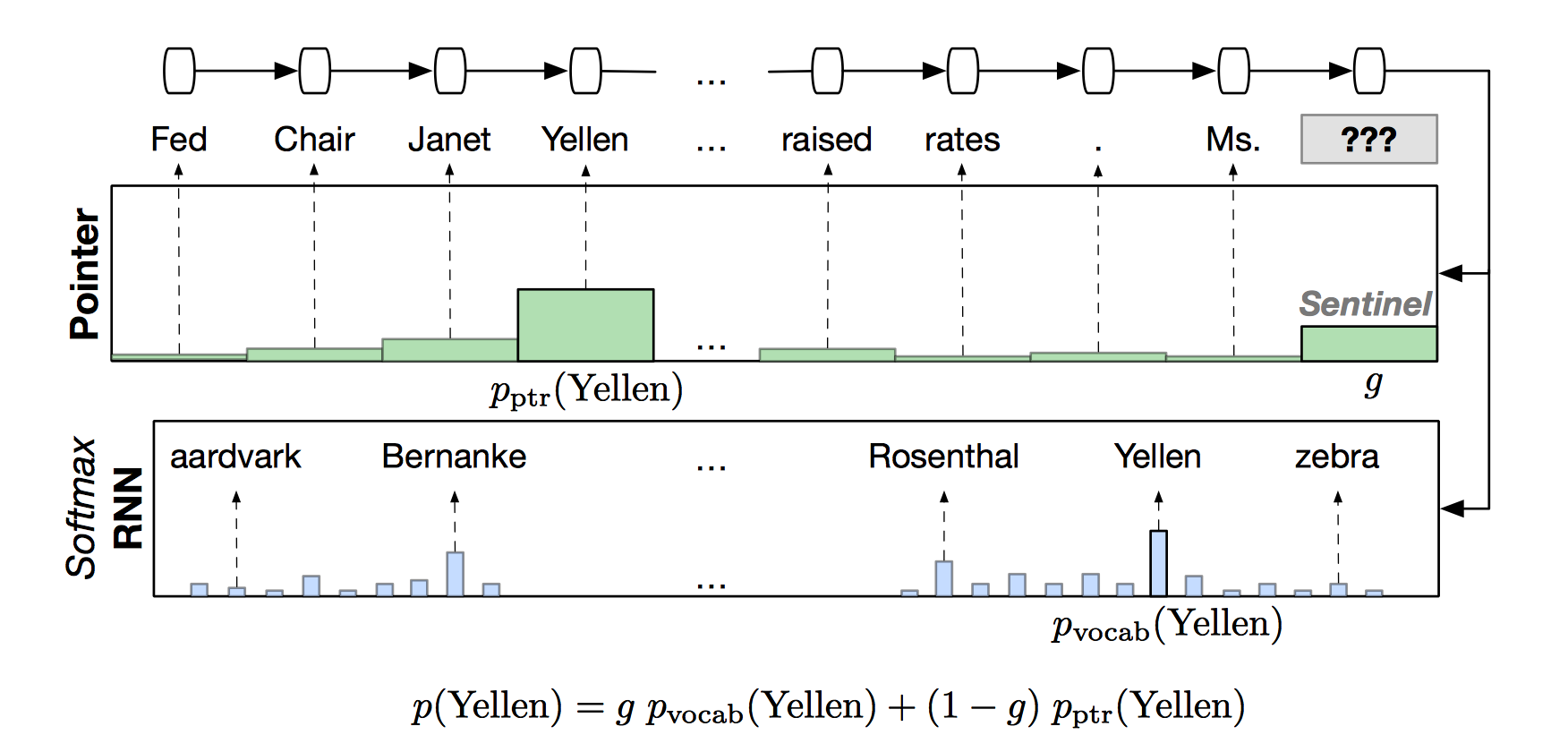
Pointer-Sentinel Model
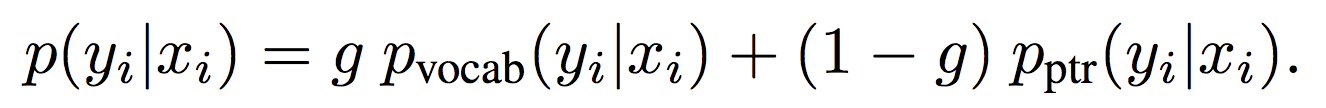
Attention应用:Intra-Decoder attention for Summarization
A Deep Reinforced Model for Abstractive Summarization

Attention应用:Similar Seq2Seq Idea as in Translation
还有很多attention的应用,这里不一一列举了。现在,我们先介绍一些能够提升机器翻译效果的tips & tricks。
将NMT拓展到更多语言
-
光是复制原理还不够
- Transliteration: Christopher ↦ Kryštof
- Multi-word alignment: Solar system ↦ Sonnensystem
-
需要准备一个大词库
- 丰富的语法
nejneobhospodařovávatelnějšímu- Czech = “to the worst farmable one”Donaudampfschiffahrtsgesellschaftskapitän– German = Danube steamship company captain
- 非正式的拼写:
goooooood morning !!!!!
- 丰富的语法
解决大词表问题
大词表加大了softmax的计算难度
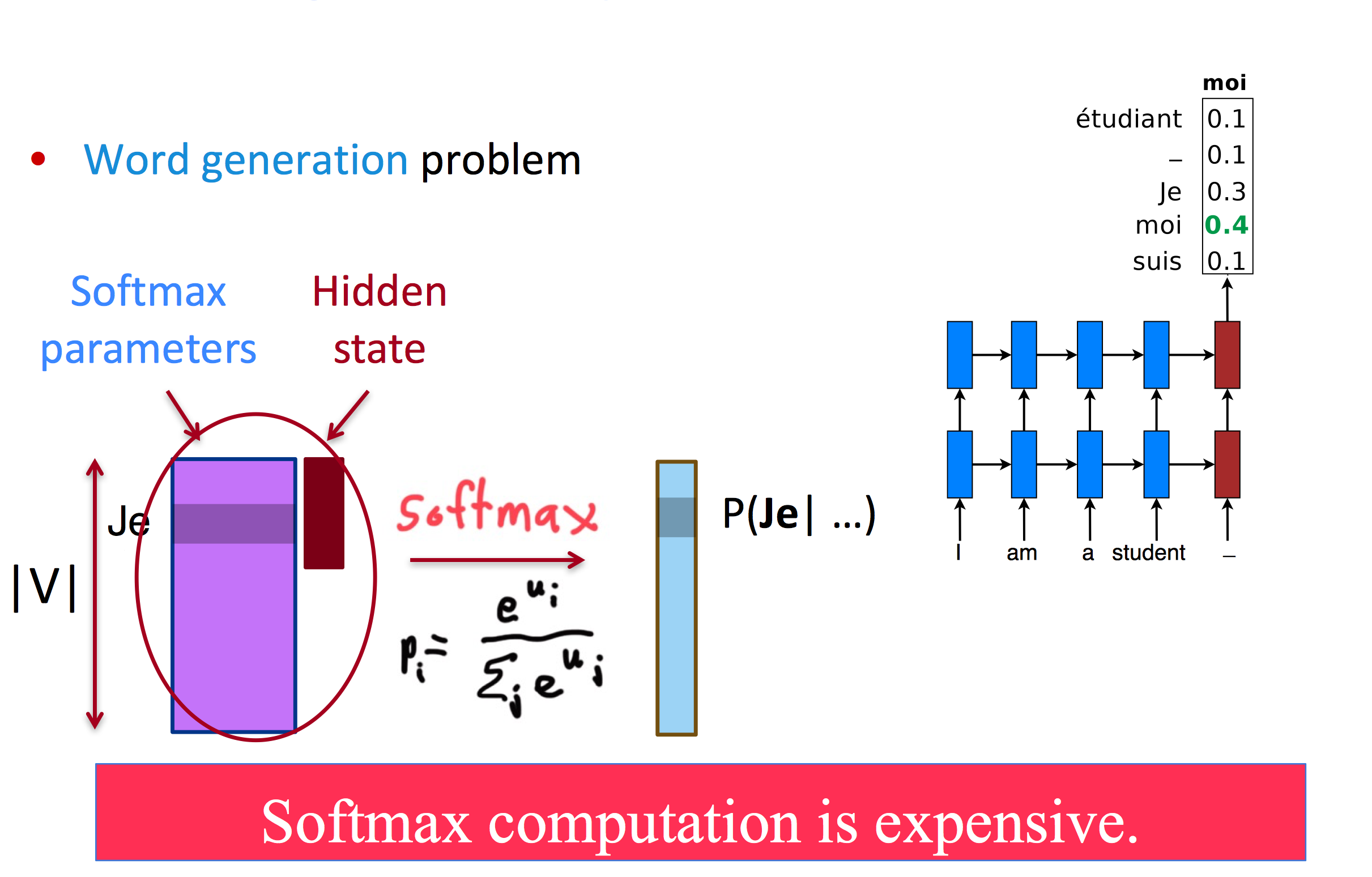
在早期的MT中,会使用较小的词表,但这样并不能说解决了问题:
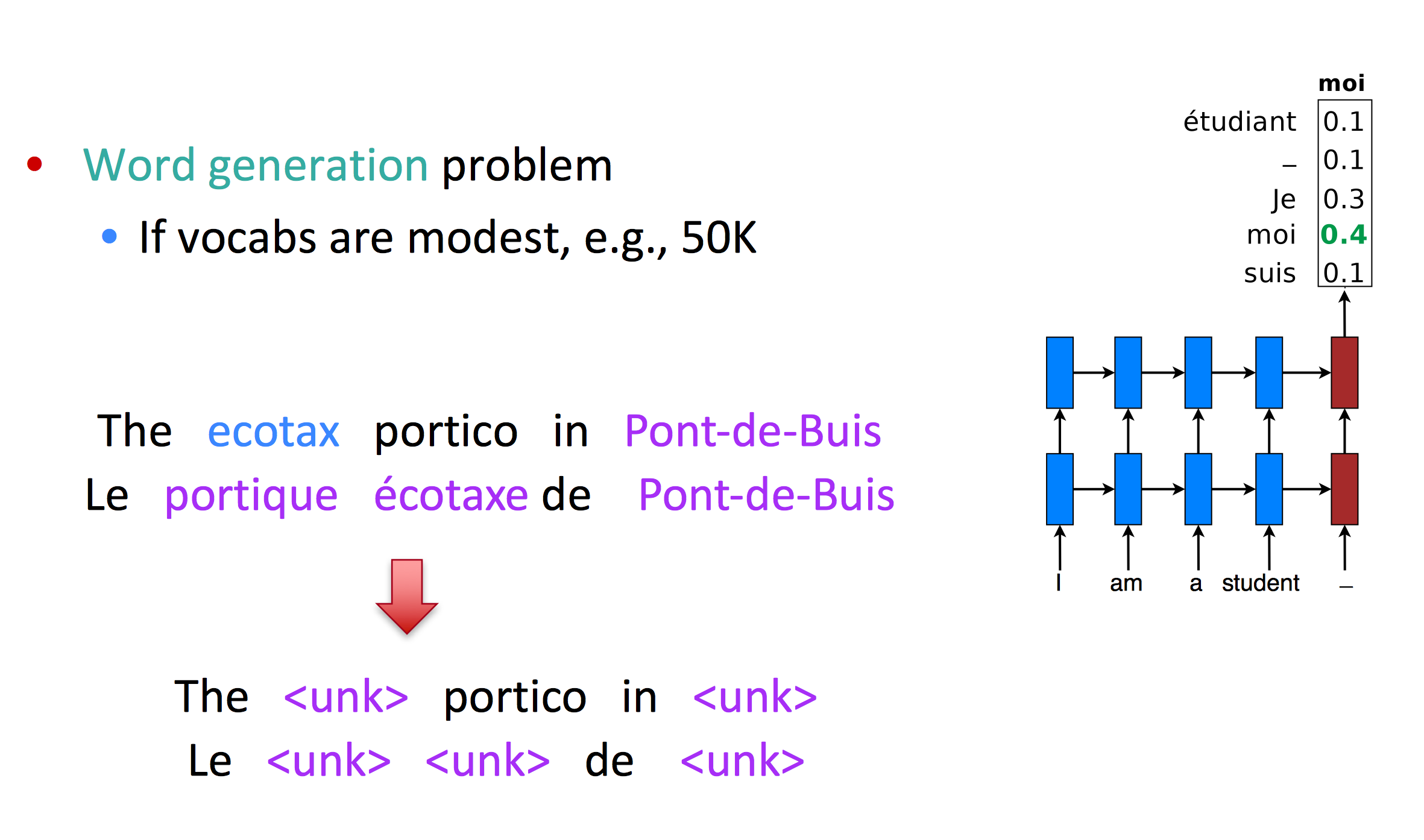
另一种想法是缩小softmax大小,但这样对gpu不友好

Large-vocab NMT
这个方法的思路是,首先在大词表训练集的子集下训练模型,再在测试时添加一些技巧处理那些出现很少的词。
Training
每次都训练一个比原词库小很多的子集,训练多个子集
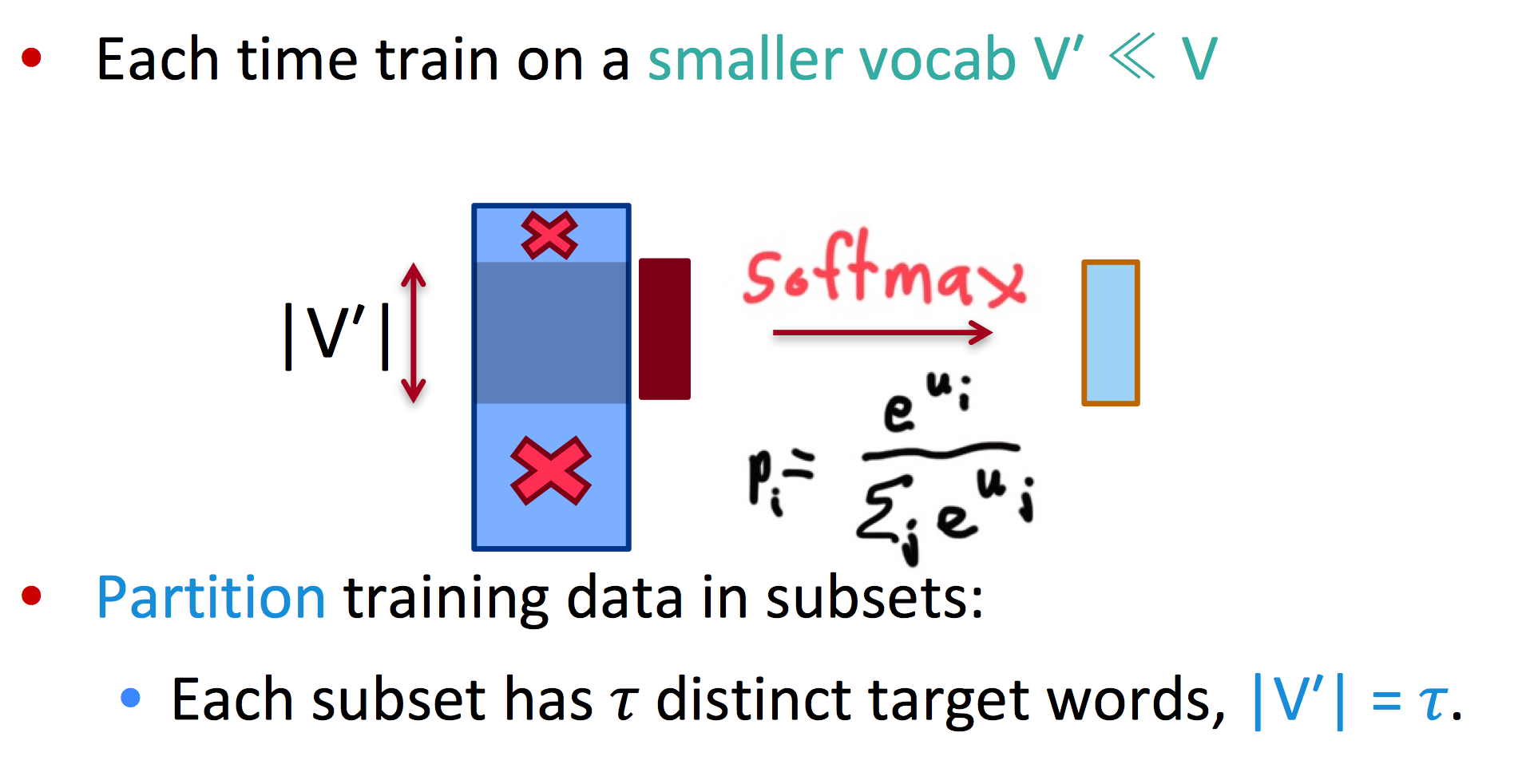
例如,每次选取子集大小为5:


Test
- 取k个出现频率最高的词 - unigram prob
de, , la . et des les … - 每个词取
k'个翻译候选单词

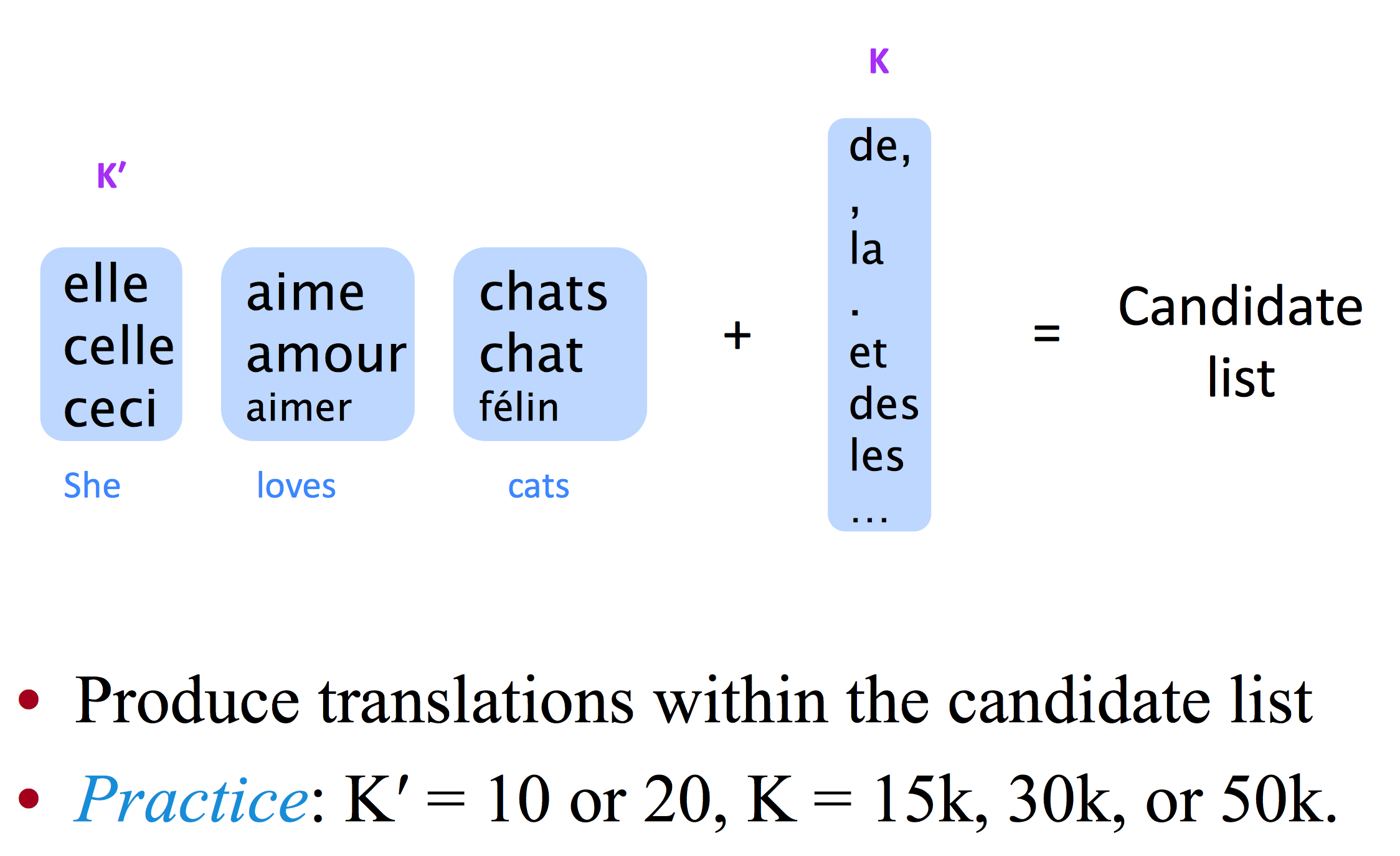
之后还说到了很多解决大词库的思路
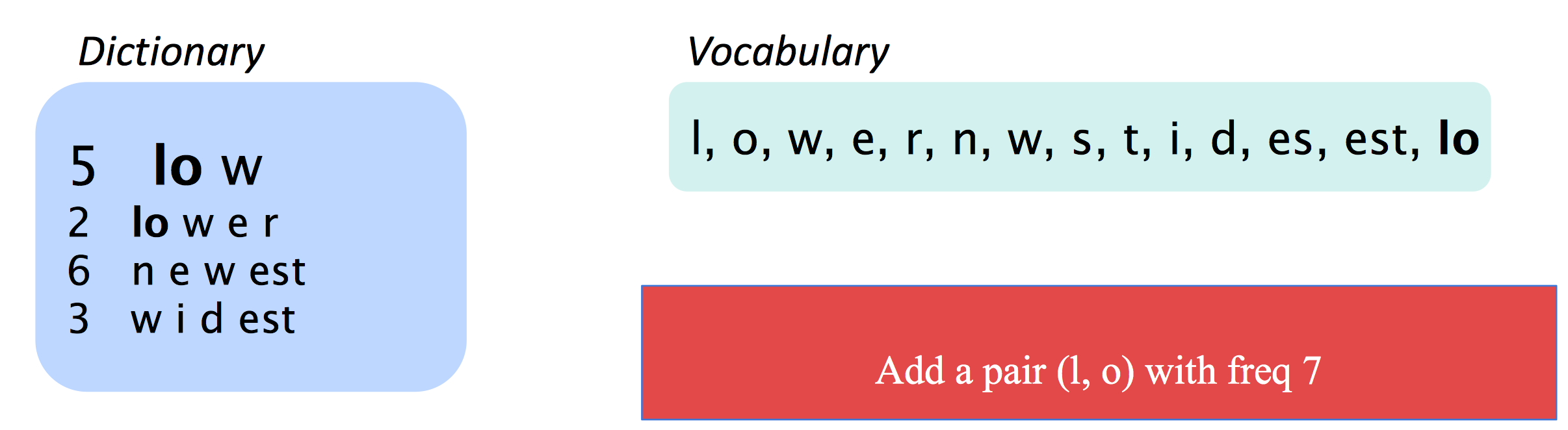
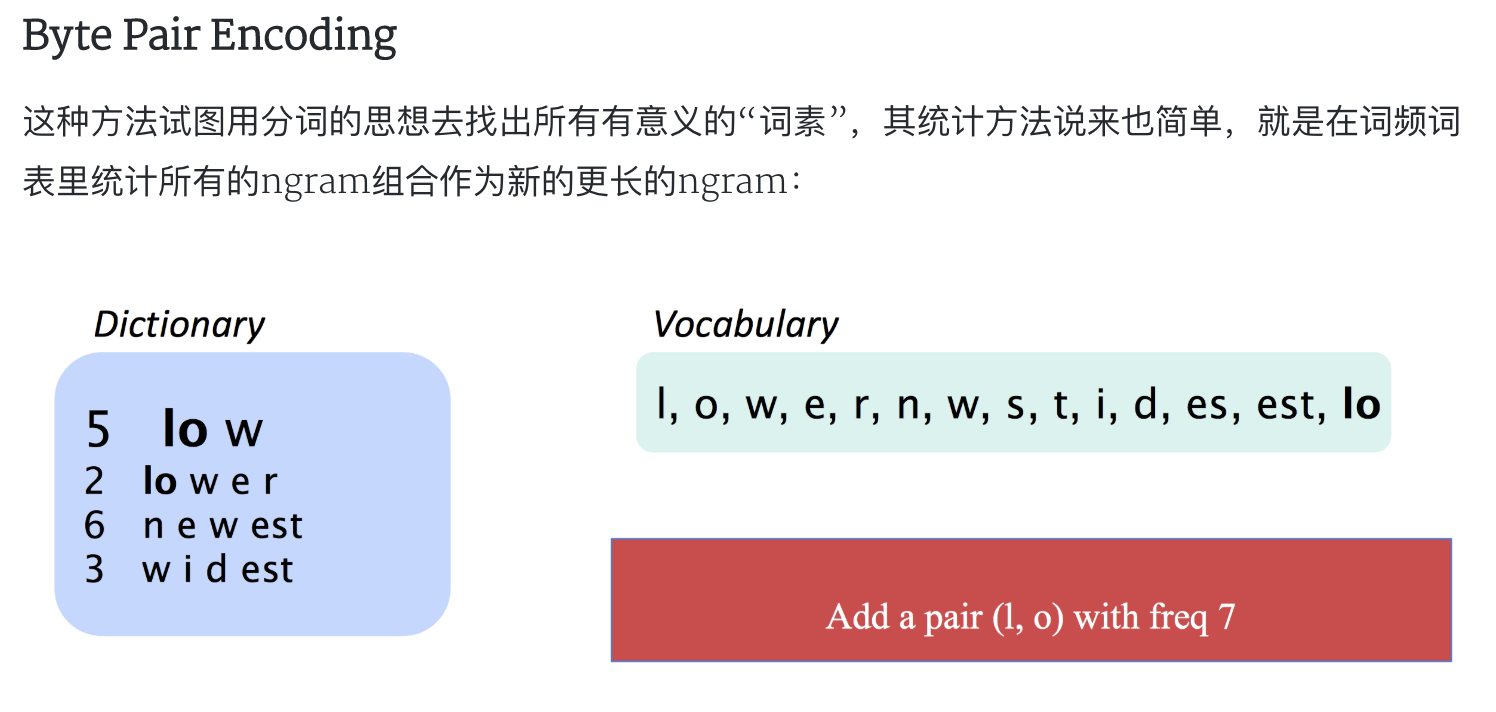
Byte Pair Encoding
这种方法试图用分词的思想去找出所有有意义的“词素”,其统计方法说来也简单,就是在词频词表里统计所有的ngram组合作为新的更长的ngram:
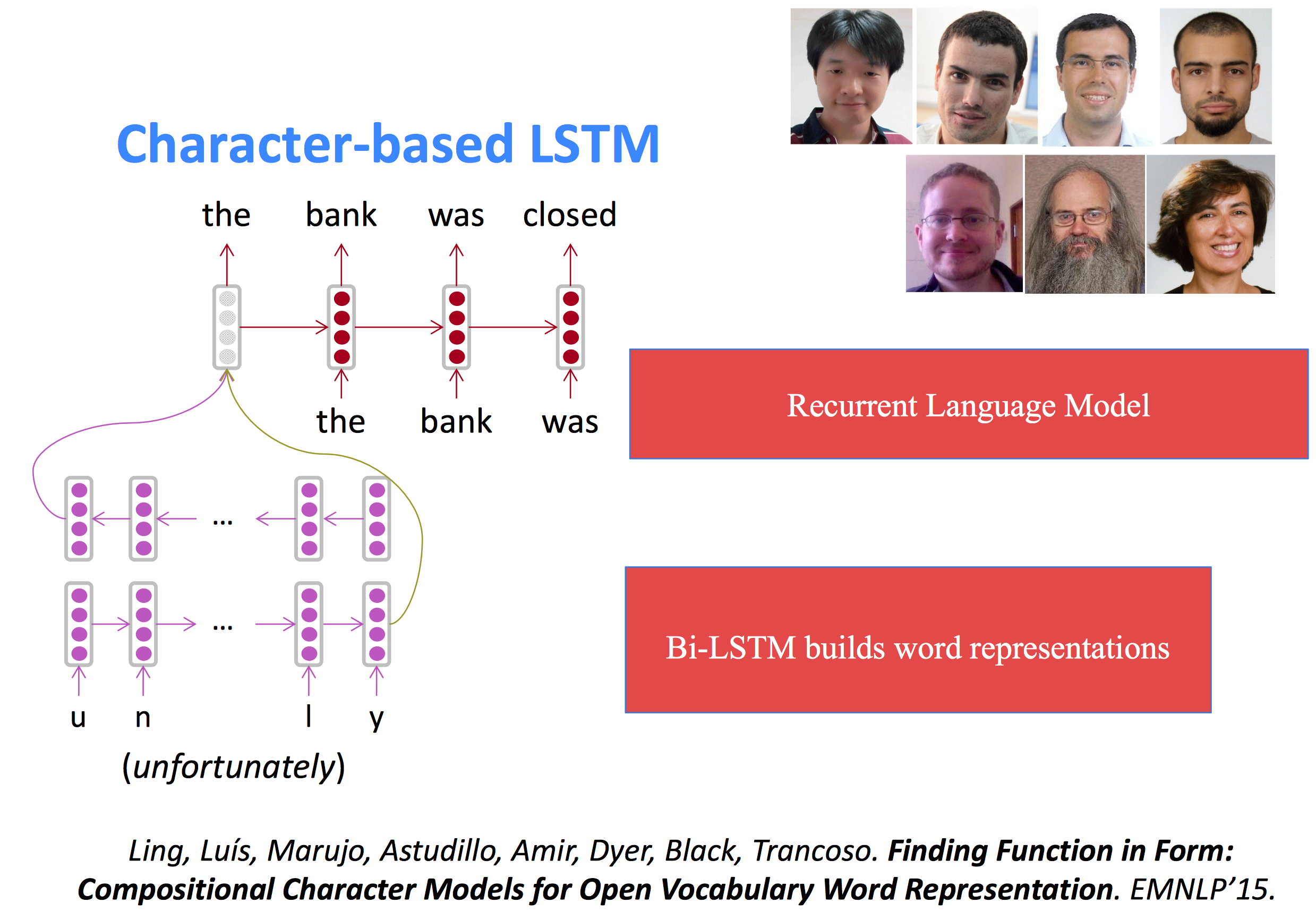
字符级别的LSTM(character-based LSTM)
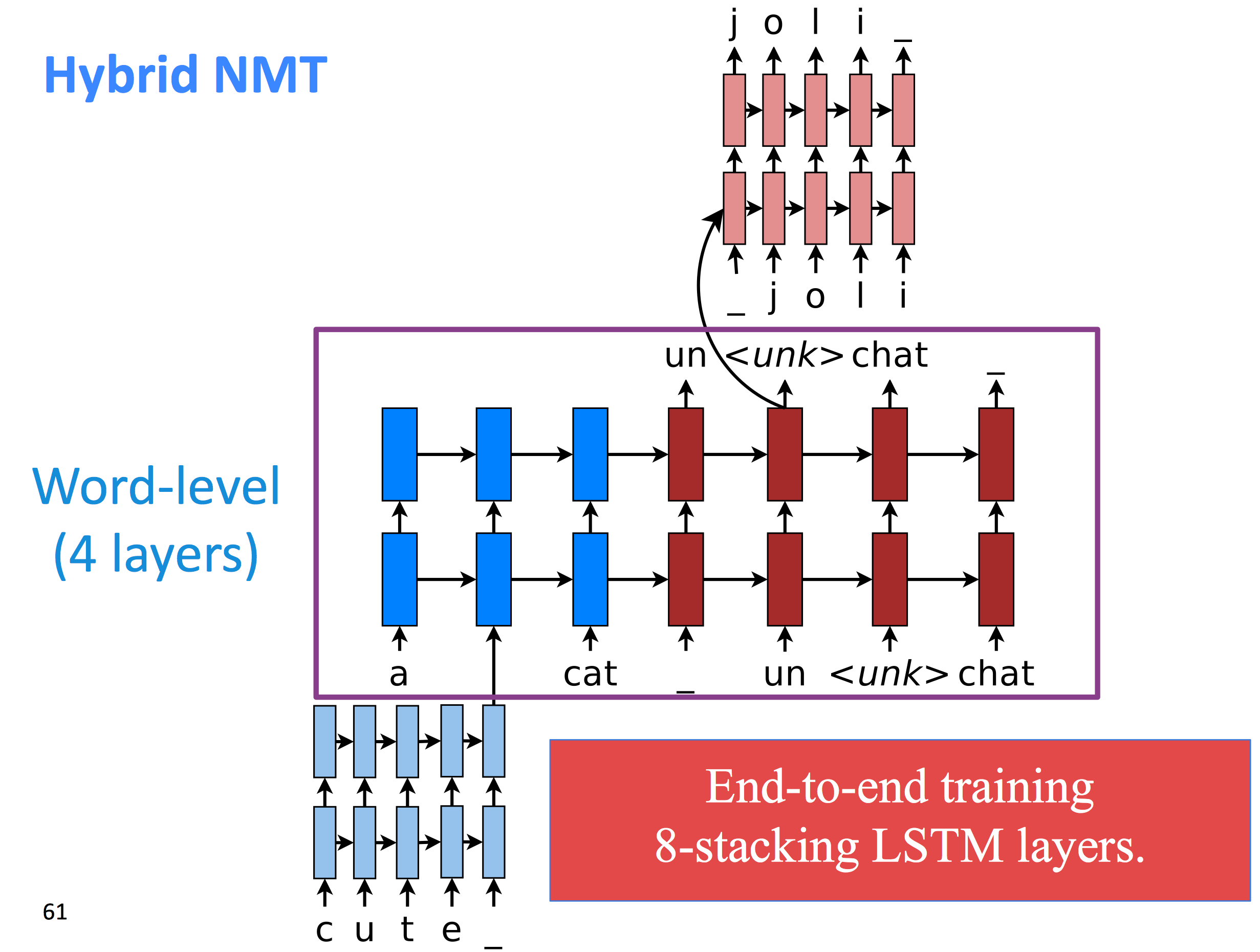
Hybrid NMT
另有一些混合动力的NMT,大部分情况下在词语级别做翻译,只在需要的时候从字符级去翻译。这个系统的主体是词语级别的LSTM,先在词语级别上做常规的柱搜索,当出现unknown词时,切换到char级别做柱搜索:
BLEU得分
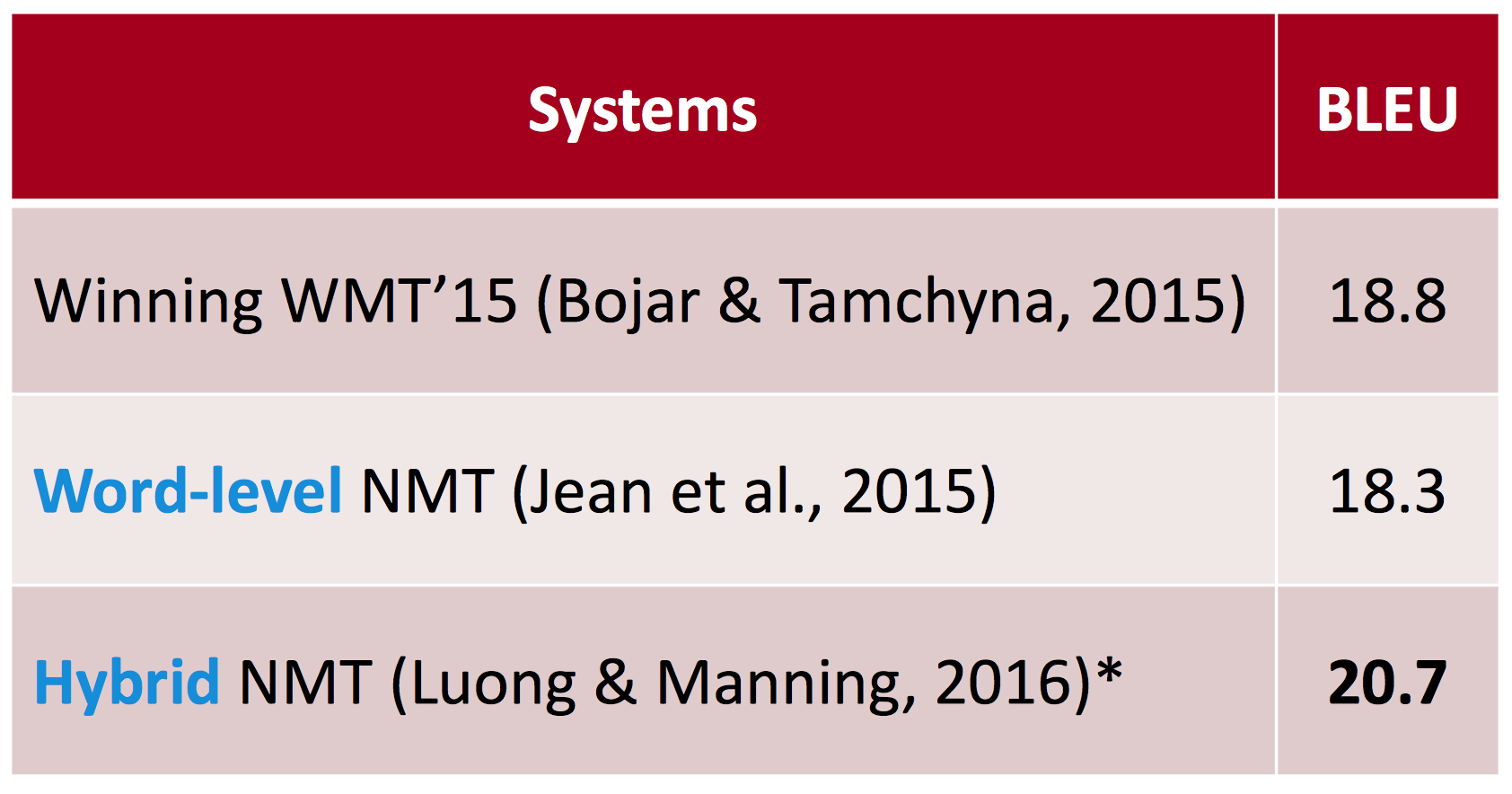
-
-
Lecture12 - Transformer Networks and Convolutional Neural Networks
Problems with RNNs = Motivation for Transformers
- 连续计算阻止了平行化

- 尽管有GRU和LSTM,RNN仍然需要attention机制来处理长距离的关系 - 状态间需要关系计算的长度随序列的增加而增加
- 但,如果attention能使我们得到任意状态,那么其实我们并不需要RNN?
Transformer概述
- Sequence-to-sequence
- Encoder-Decoder
- Task: machine translation with parallel corpus(平行语料)
- Predict each translated word
- Final cost function is standard cross-entropy loss on top of a softmax classifier
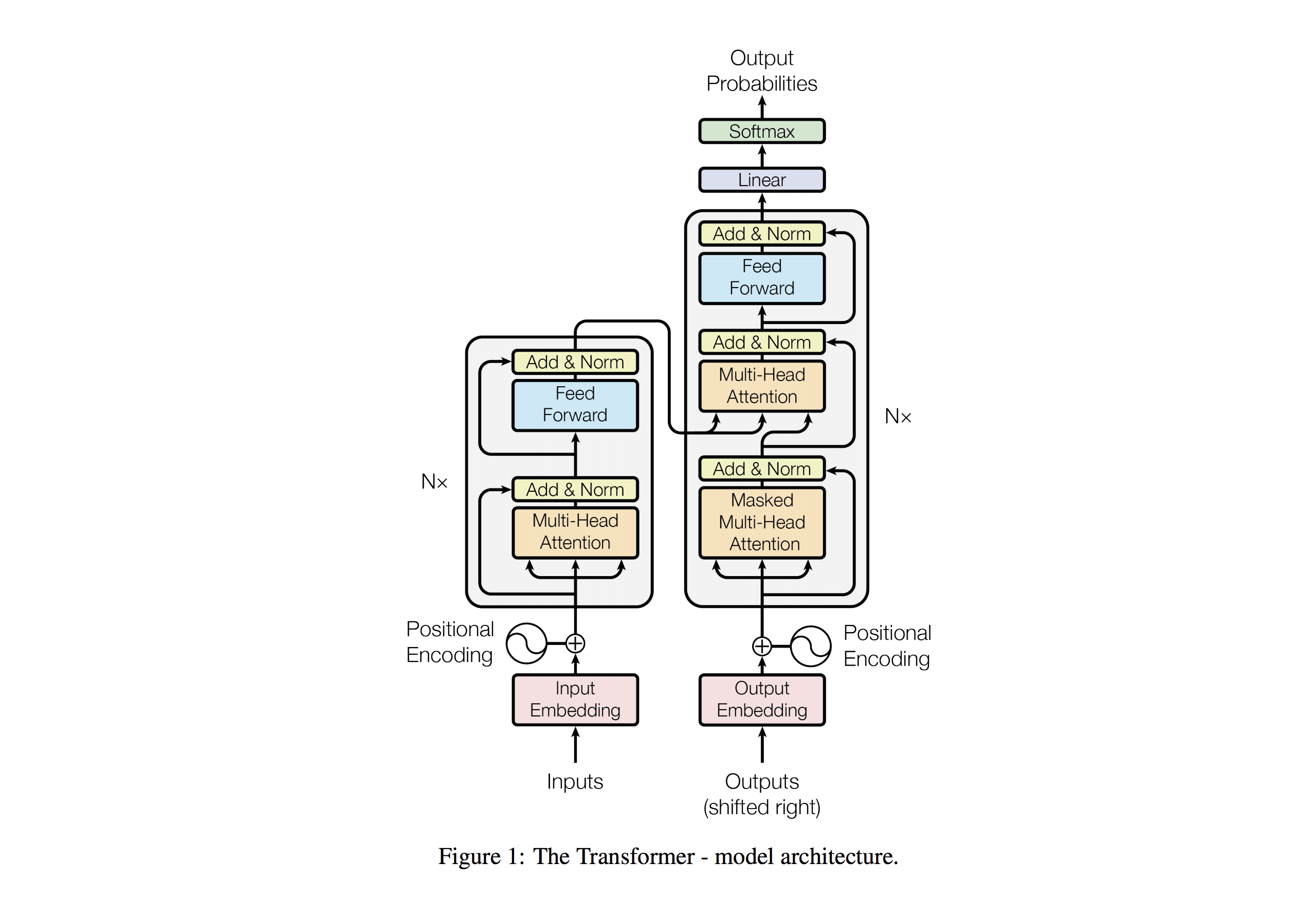
在这里不得不说这篇非常有名的论文,Attention Is All You Need,Transformer也是出自这篇论文。
Transformer Basics
我们首先定义一个transformer的基础部分:attention layers
Dot-Product Attention
这里我们使用的是Dot-Product Attention。
- 输入:query q和指向输出output的key-value对的集合
- query, keys, values, output都是向量
- output是values的权重计算结果,其中
- 每一个value的权重都由一个内部产生的query以及相应的key计算出
- queries和keys都有相同的维度d_k, value的维度为d_v
当我们有query的集合Q,Q就是一个矩阵,上式变成:
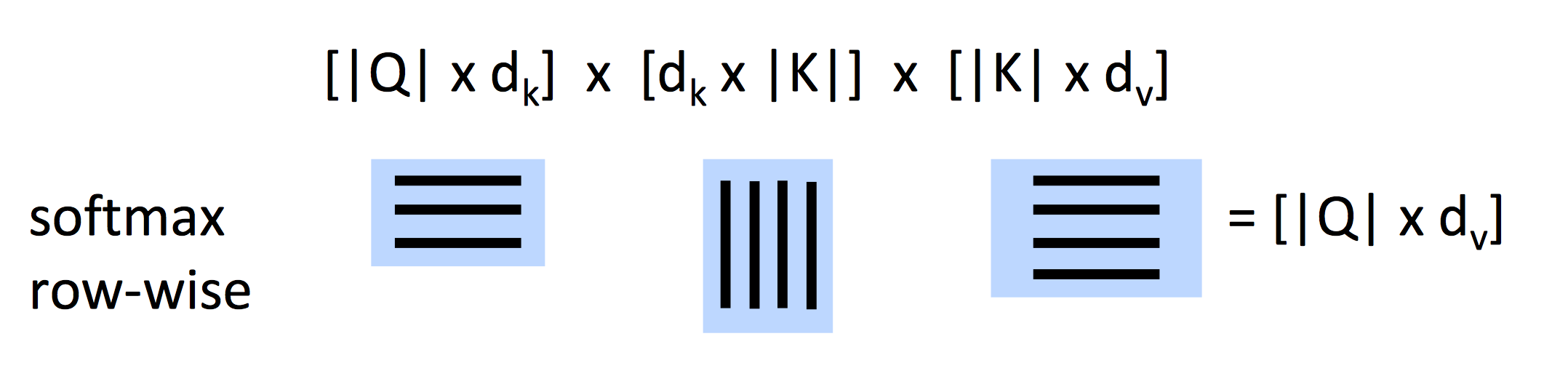
Scaled Dot-Product Attention
这里出现了一个问题,当d_k特别大时,q^Tk的变化就会很大,softmax中的一些值就会变得很大,softmax也就会变得很大,因此它的梯度会变小。
解决方法
里面除以query/key向量的长度的平方根来缩小softmax内值的大小。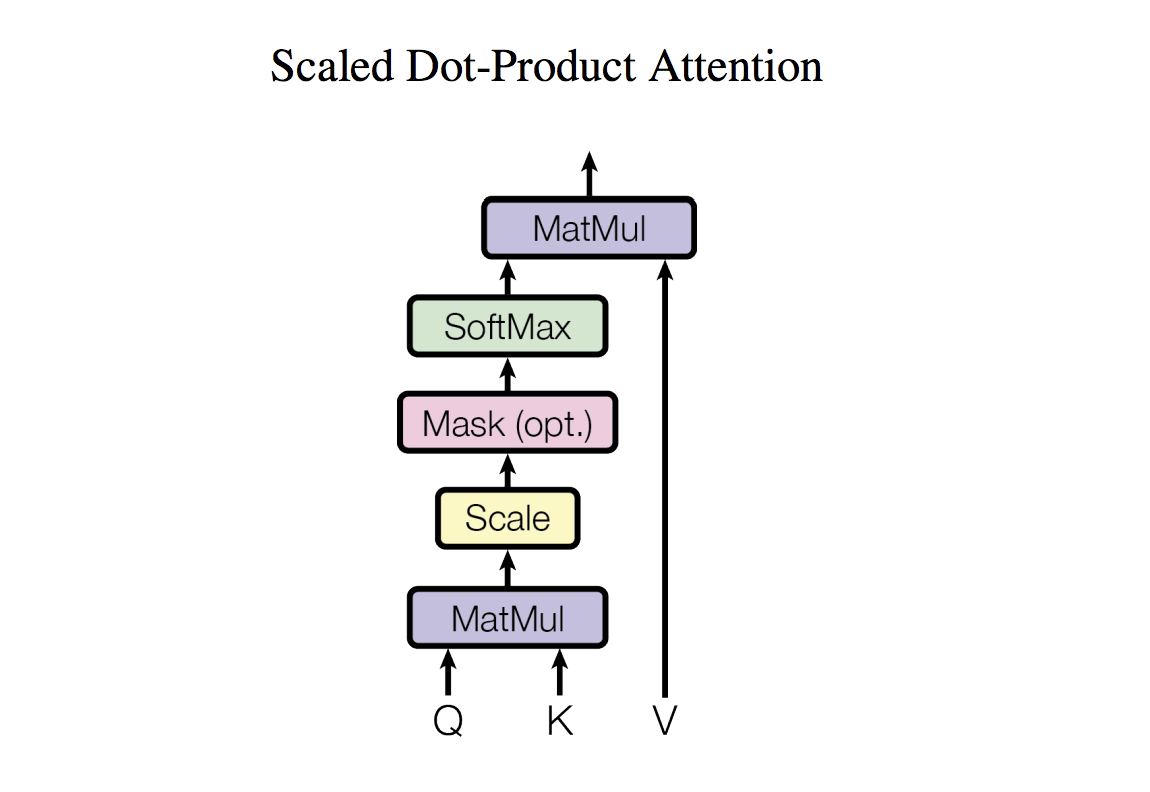
Self-attention and Multi-head attention
- 输入的词向量可以是queries,keys,values
- 换言之,词向量间互相选择
- Word vector stack = Q = K = V
问题:只有一种方式能使词之间互相影响
解决方式:Multi-head attention- 首先将Q, K, V放入h个W矩阵的空间中
- 再应用attention,将attention的输出concat到一起,然后经过一个线性层。
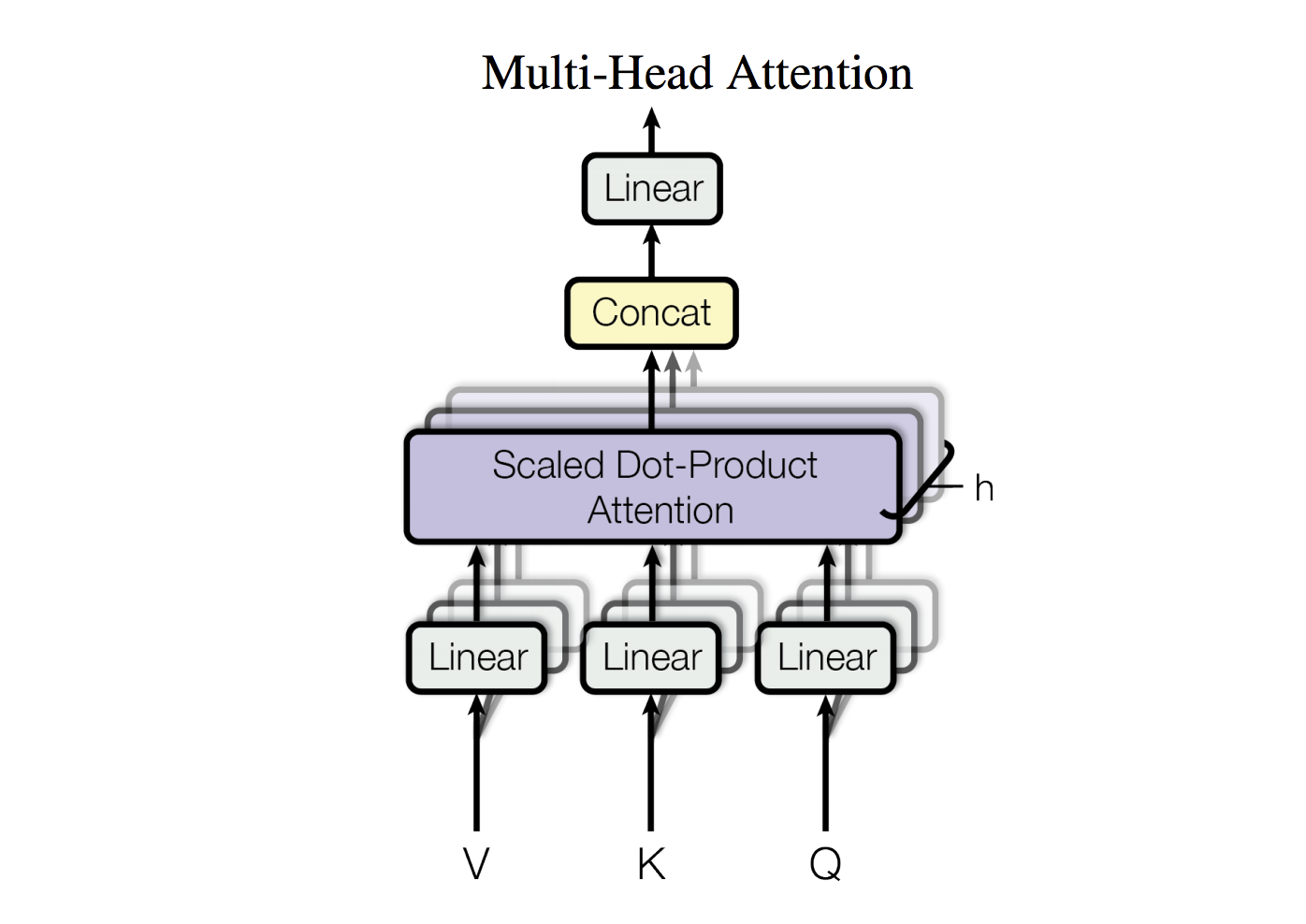

Complete transformer block
- 每一个block有两个"sublayers"
- Multihead attention
- 2 layer feed-forward Nnet (with relu)
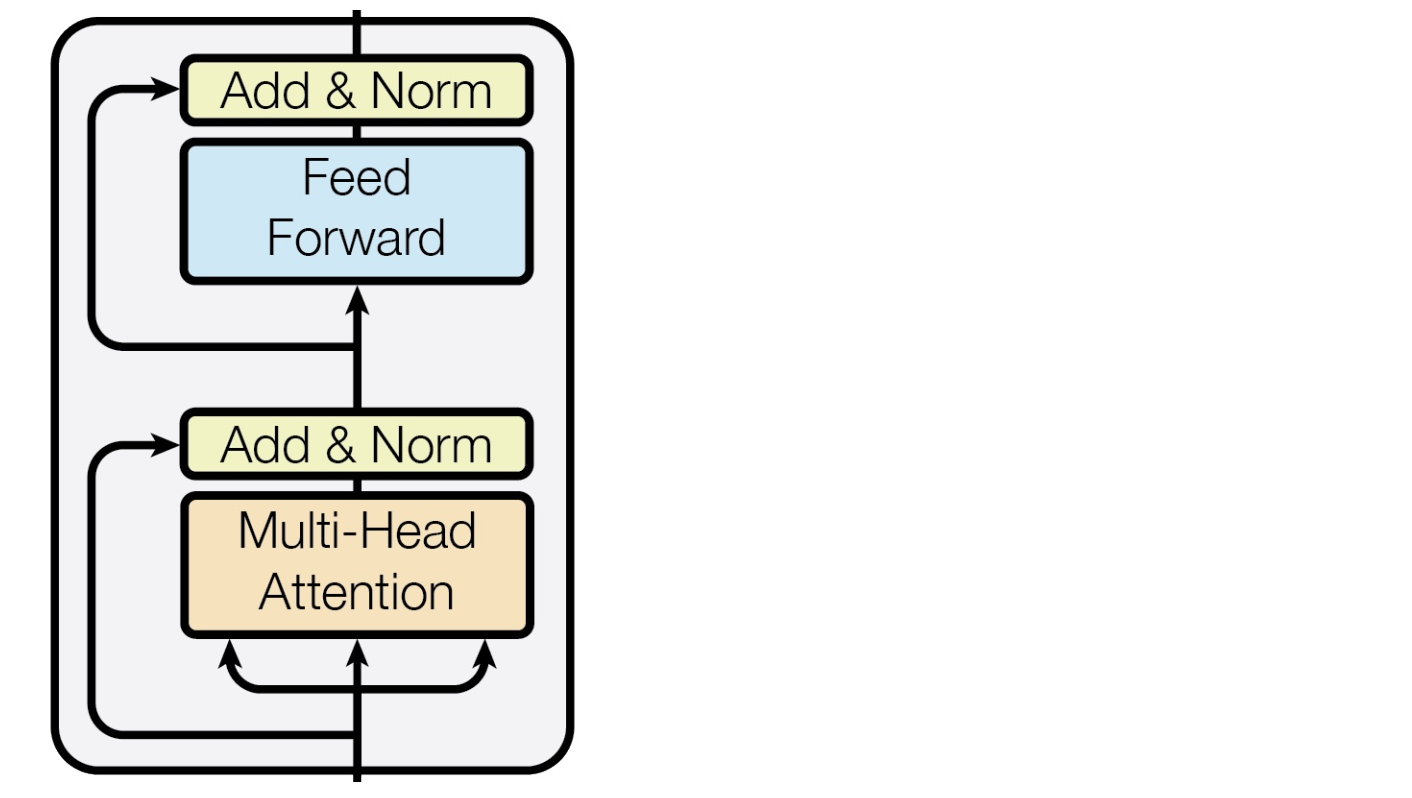
这两层之间还包括:
- Residual(short-circuit) connection and LayerNorm
- LayerNorm(x + Sublayer(x))
- Layernorm改变输入,将输出的方差为1,均值为0

这部分Layer Normalization可见这篇论文:
Layer Normalization by Ba, Kiros and Hinton
Encoder Input
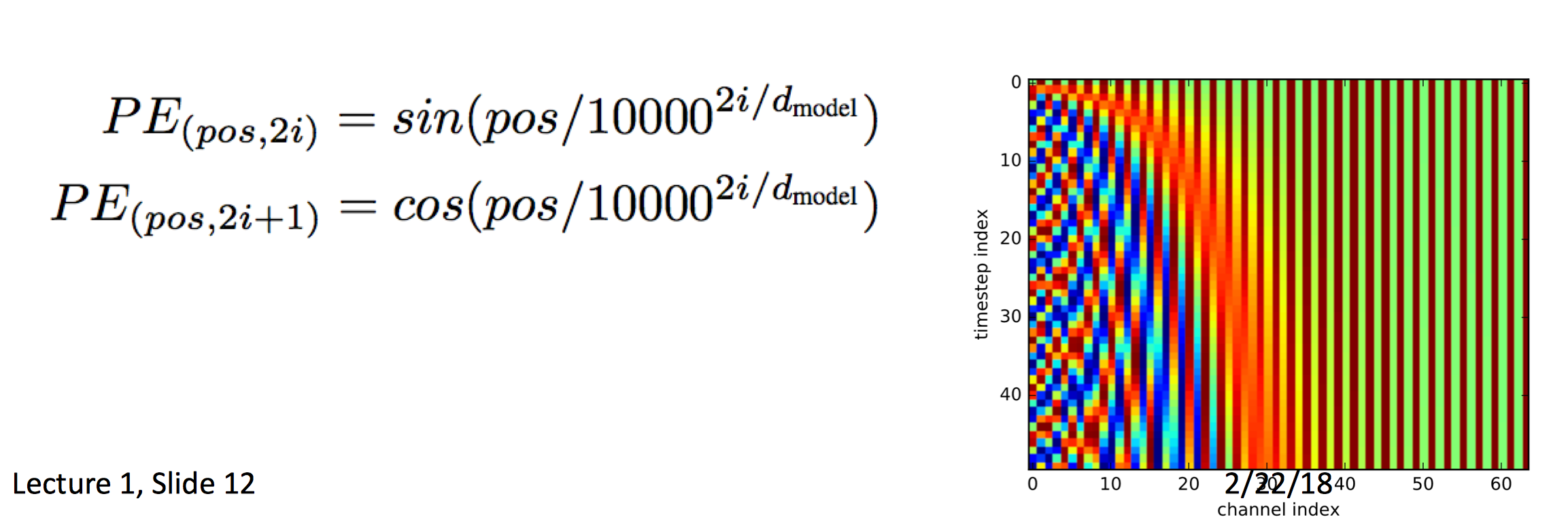
- 词的表示使用的是byte-pair encodings(见上一篇lecture)
- 同时也加入了positional encoding,这样同样的词在不同的位置会有不同的表示。
Complete Encoder
- 在Encoder的每一块中,我们使用了与前一层相同的Q,K,V
- blocks重复6次
layer5的attention可视化
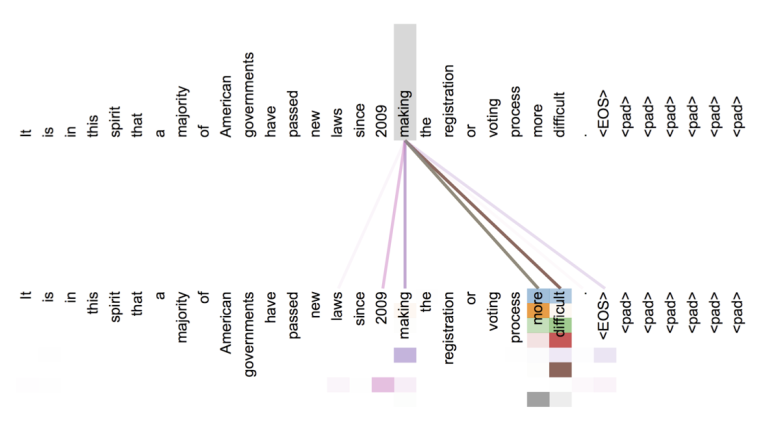
可以看到,词开始注意到了其它词。attention可视化: 隐藏的指代分辨
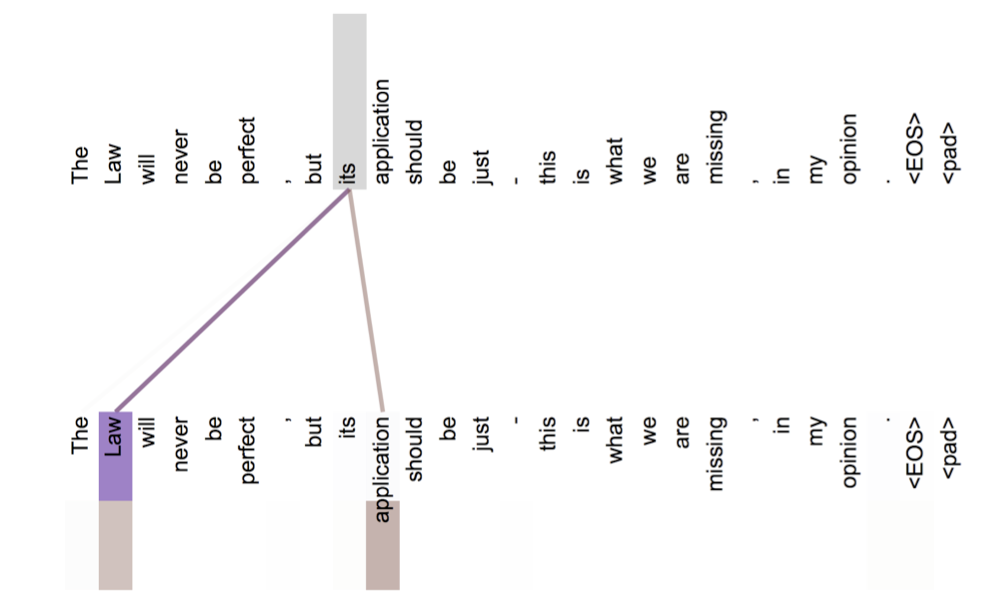
在layer5中,it's对它所指代的词law的attention已经很大了。
Transformer Decoder
- decoder中不再是2个sublayer
- masked decoder self-attention on previously generated outputs:
- Encoder-Decoder的attention,query来自前一层decoder layer,keys和values来自encoder的输出
- blocks也会重复6次
Tips and tricks of the Transformer
在All Attention论文中提到的一些特性:
- Byte-pair encodings
- Checkpoint averaging
- ADAM optimizer with learning rate changes
- Dropout during training at every layer just before adding residual
- Label smoothing
- Auto-regressive decoding with beam search and length penalties
- 总之,模型很难部署,同时不像LSTM一样,all attention很难在其他block结构中表现好
CNN
- CNN的主要思想:如果我们为语料中的每种可能的短语计算多种向量会怎样?
- 不管怎样,短语是符合语法规则的,CNN得到的短语也是符合的
- 示例:
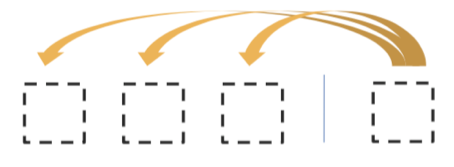
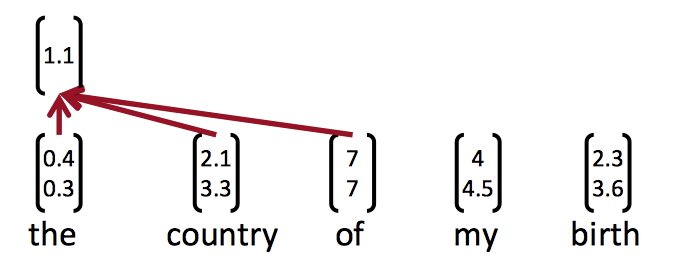
the country of my birth可以计算的向量有:
the country,country of,of my,my birth,the country of,country of my,of my birth,the country of my,country of my birth - 然后把这些向量分组
- 这样做从语言学上来说不是很可信,但是计算非常快
什么是卷积
这里就不做介绍了

单层CNN - 卷积层
-
使用了一层卷积层和池化层的简单结构
-
基于"Convolutional Neural Networks for Sentence Classification" (TextCNN)
-
Word vectors
-
Sentence(就是直接把词向量concat到一起)
-
Concatenation of words in range:
就是把j个词的向量加在一起做卷积
-
Convolutional filter:
这里用一个大小为h的window来扫过句子
-
卷积核可以是2或者更高,比如3:
-
计算得到卷积层的值
-
把多个c放到一个数组中,构成一个feature map
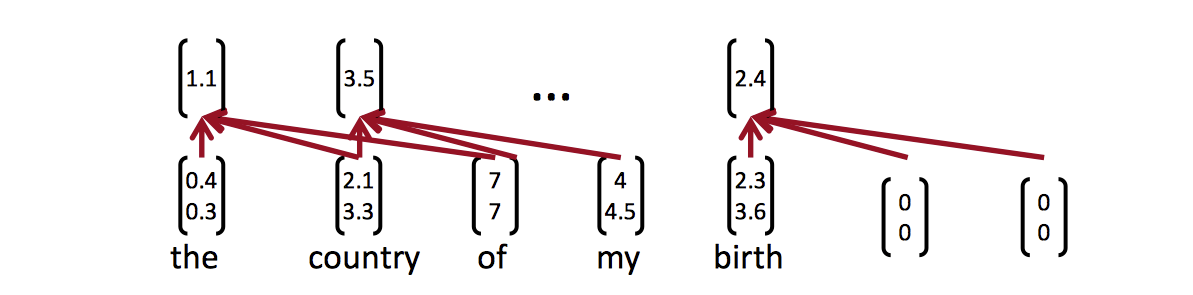
池化层
-
max-over-time pooling layer
-
思想:从feature map
捕捉最重要的特性
-
池化单个数:
这样就可以得到卷积层提取出的特征了,但我们希望得到更多的特征,怎么办?
Multiple filters
- 使用多个filter size来构建多个大小的窗口
- 因为用的是max-pooling,c的长度不受限制,因此我们可以使用多个不同的size,就像n-gram一样。
Multi-channel(多通道) 思想
TextCNN有几种:
- CNN-rand: 句子中的的word vector都是随机初始化的,同时当做CNN训练过程中需要优化的参数;
- CNN-static: 句子中的word vector是使用word2vec预先对语料库进行训练好的词向量表中的词向量。且在CNN训练过程中作为固定的输入,不作为优化的参数;
- CNN-non-static: 句子中的word vector是使用word2vec预先对语料库进行训练好的词向量表中的词向量。在CNN训练过程中作为固定的输入,做为CNN训练过程中需要优化的参数;
这里说的是用word2vec训练的static TextCNN
- 使用预训练的词向量进行初始化(Word2Vec或Glove)
- 使用两个CNN copies
- 只反向传播一个CNN,保持另外一个为'static'
- 两个通道的结果都加到c_i中,再进行max-pooling
CNN层之后进行分类
多个filter得到的max-pooling结果构成一个向量:
最后再加上softmax层得到归一化概率:
TextCNN
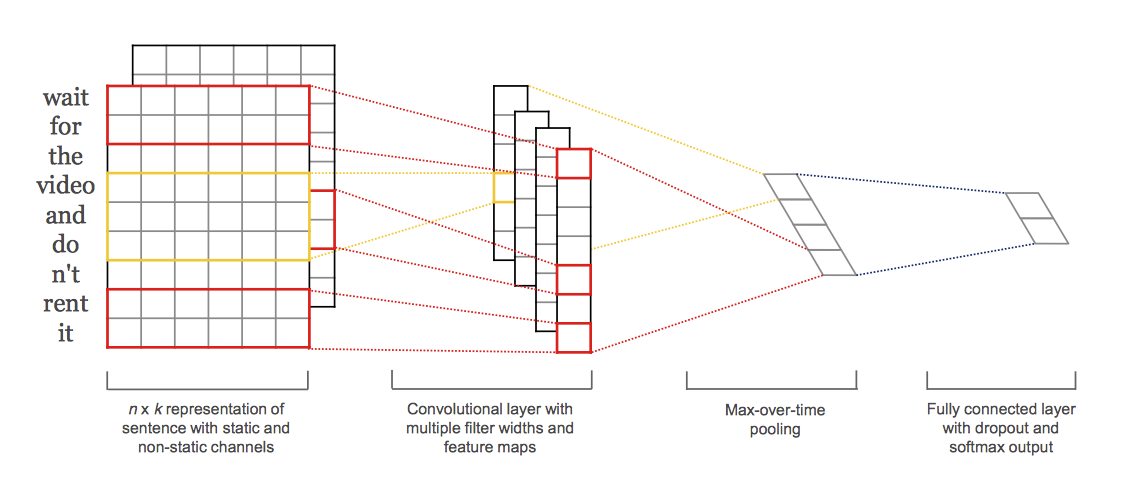
这是Kim在2014年论文中提到的TextCNN结构。
让模型效果更好的tricks - Dropout
-
思想:随机将隐藏层中的部分特征移除
-
随机构建一个伯努利矩阵r。r可以控制哪些特征要被drop
-
在训练的时候删除部分特征
-
因此在训练的时候,只会通过r中等于1的部分影响梯度进行反向传播
- 为什么要Dropout?
可以防止过拟合 - 来源:Paper: Hinton et al. 2012: Improving neural networks by preventing co-adaptation of feature detectors
另一个trick - regularization
- 使用l2正则来正则化每个分类的权重向量,使其适配一个超参数s
- 如果
$$||W_c^{(s)}|| > s$$, 将其缩小至s
- 这种方法不是很常见
kim的TextCNN中的一些超参数
- 非线性激活函数: Relu
- Window Filter sizes h = 3, 4, 5
- 每个filter size有100个feature map
- Dropout p = 0.5
- L2正则的softmax约束超参数s = 3
- SGD training的batch size为50
- 词向量:预训练的word2vec,维度为300
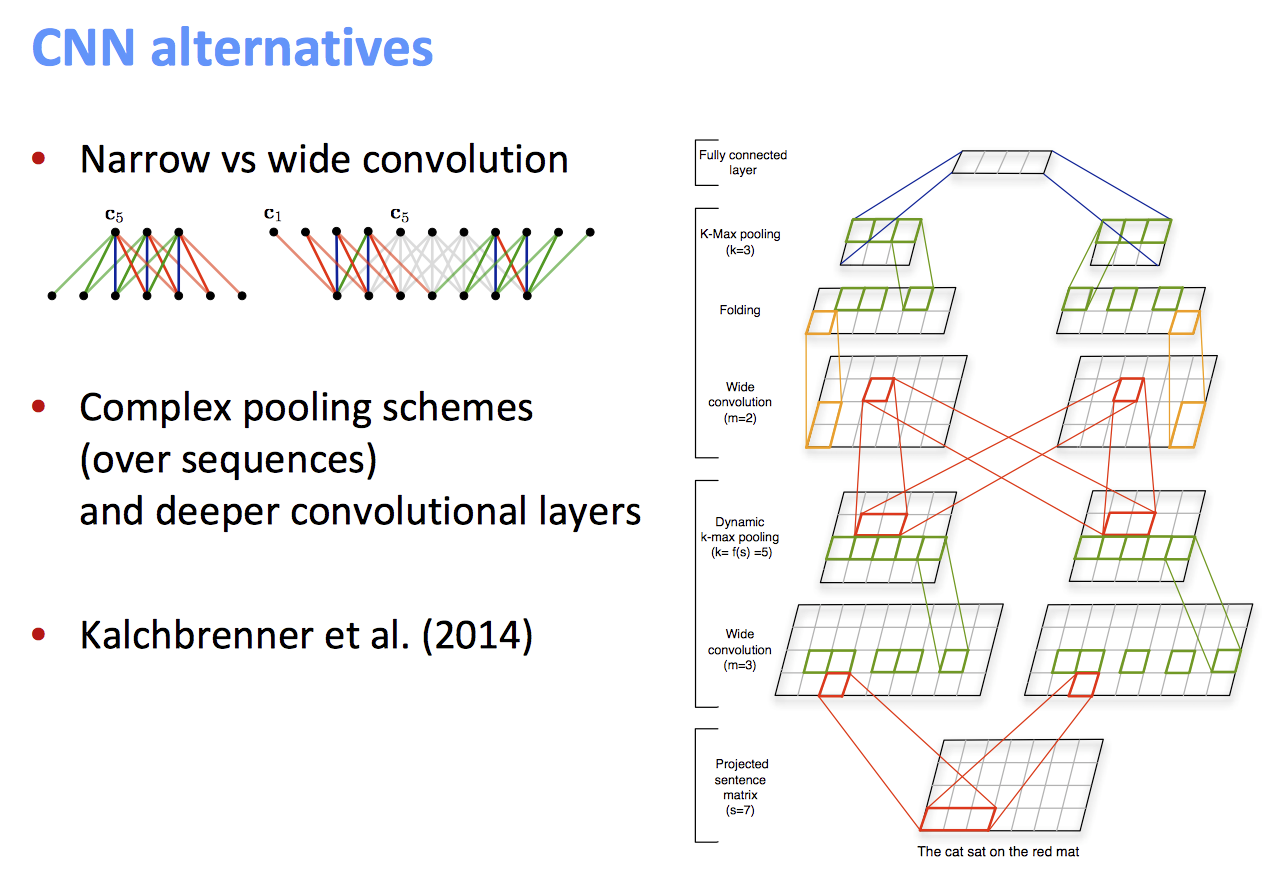
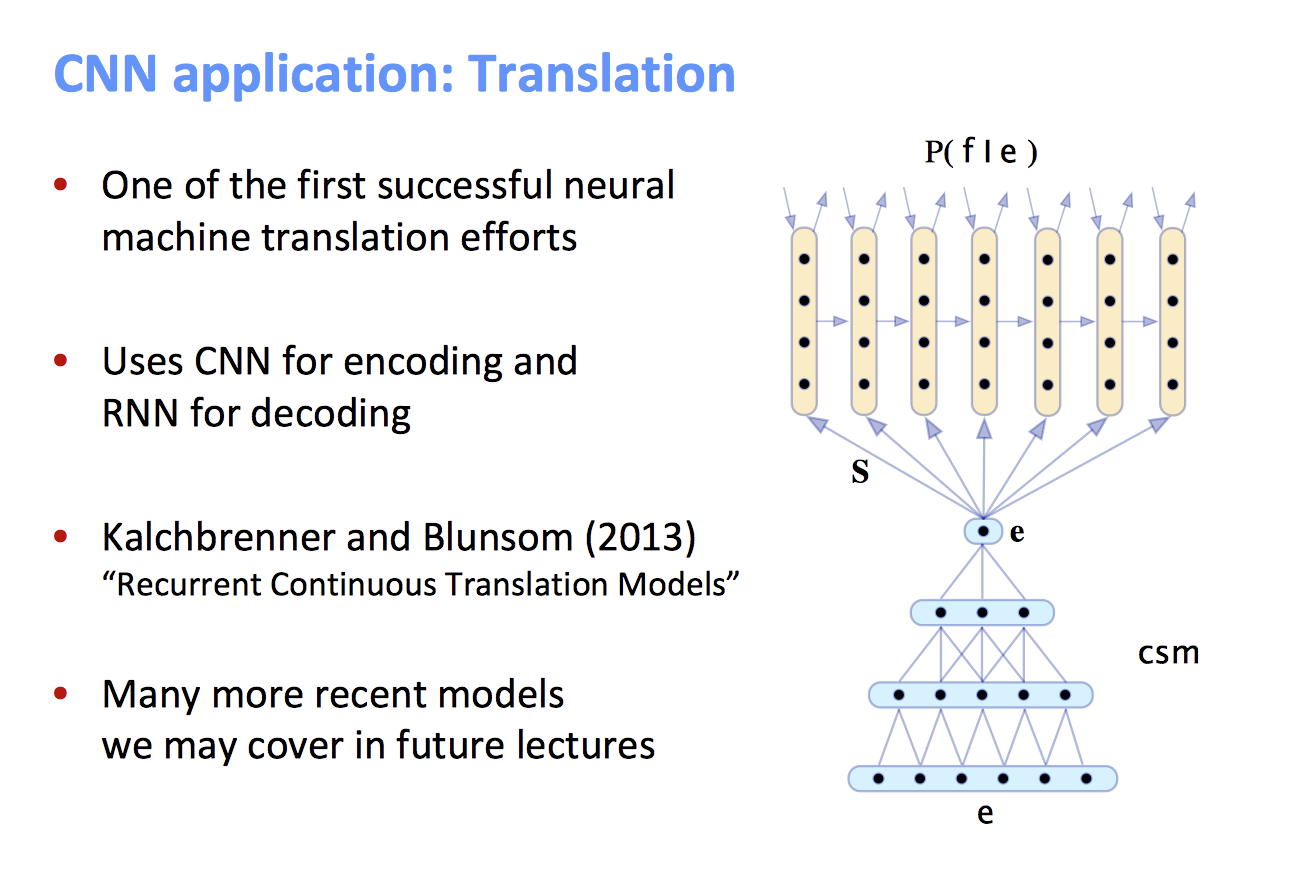
- 连续计算阻止了平行化
-
Lecture13 - Coreference Resolution
What is Coreference Resolution
分辨语言中代词所指的实体。



Applications
- Full text understanding
- information extraction, question answering, summarization, ...
- Machine trainslation
- 语言中有很多隐藏的信息如性别代词数字等
- 语言中有很多隐藏的信息如性别代词数字等
- Dialogue Systems
- "Book tickets yo see James Bond"
- "Two tickets for the showing at three"
Coreference Resolution非常难
- “She poured water from the pitcher into
the cupuntilitwas full” - “She poured water from
the pitcherinto the cup untilitwas empty”
The trophywould not fit in the suitcase becauseitwas too big.- The trophy would not fit in
the suitcasebecauseitwas too small
以上的这些例子叫做 Winograd Schema
- WS最近被提议作为图灵测试中的一项
- Turing test: 人类无法分辨出聊天的人是人类还是机器,则说明我们建立了AI系统
- 如果我们完全解决了coreference问题,可能我们就解决了AI问题
Coreference Resolution的两步
-
检测出代词 (easy)
“[I] voted for [Nader] because [he] was most aligned with [[my] values],” [she] said- 代词是可以嵌套的
-
给代词聚类 (hard)
- I, my, she
- Nader he
- my values
Mention Detection
Three kind of mentions:
- Pronouns
- I, your, it, she, him, etc.
- Named entities
- People, places, etc.
- Noun phrases
- "a dog", "the big fluffy cat stuck in the tree"
Use other NLP systems for detection
- Pronouns
- Use a part-of-speech tagger
- Named entities
- Use a NER system (like hw3)
- Noun phrases
- Use a constituency parser (next lecture)
后面有点无聊,都不写了
- Full text understanding
-
Lecture14