GBDT的算法原理
-
一、概述
GBDT即Gradient Boosting Decision Tree,梯度提升树。是一种迭代的决策树算法,由多棵回归树组成。二、特点
优点:可以灵活处理各种类型的数据,包括连续值和离散值,与SVM一样,具有较强的泛化能力;适合低维数据;能处理非线性数据;在相对少的调参时间情况下,预测的准备率也可以比较高(相对SVM来说);使用一些健壮的损失函数,对异常值的鲁棒性非常强(比如 Huber损失函数和Quantile损失函数)。 缺点:由于弱学习器之间存在依赖关系,难以并行训练数据,不过可以通过自采样的SGBT来达到部分并行,如果数据维度较高时会加大算法的计算复杂度。三、原理概述

四、理解
1.对单一回归树的理解
一个回归树对应着输入空间(即特征空间)的一个划分以及在划分单元上的输出值。分类树中,我们采用信息论中的方法,通过计算选择最佳划分点。而在回归树中,采用的是启发式的方法。假如我们有n个特征,每个特征有si(i∈(1,n))个取值,那我们遍历所有特征,尝试该特征所有取值,对空间进行划分,直到取到特征j的取值s,使得损失函数最小,这样就得到了一个划分点。2.对多棵回归树、残差梯度的理解
当我们选择平方差损失函数时,函数向量就表示成前一棵回归树在样本空间上的预测值,则对函数向量求梯度就等于目标值减去预测值,即我们所说的残差向量;因此,下一棵回归树就是在拟合这个残差向量(即计算响应)。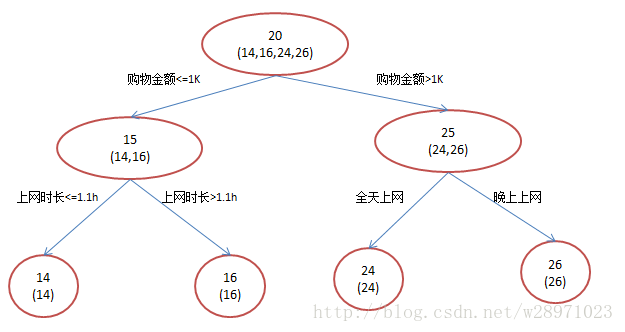
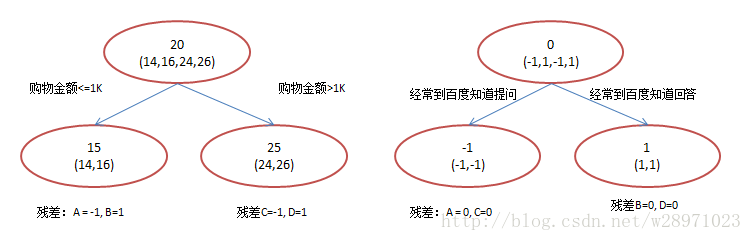
基于此,我们再来理解一下GDBT的第一步操作: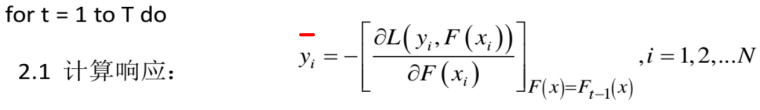
我们将
称为残差,这一部分也就是单一的回归树模型 )未能完全拟合的部分,所以交给GDBT来完成。平方损失函数可以写成: 我们想最小化 损失函数的一阶导正好残差就是负梯度
 。
。
