机器学习中的梯度消失与梯度爆炸问题详解
-
一、什么是梯度消失与梯度爆炸
- 梯度消失(Vanishing Gradient):深度学习中前面的隐藏层的更新速度要低于后面的隐藏层,该现象称为梯度消失问题。
- 梯度爆炸(Exploding Gradient):深度学习中内层梯度比外层大很多,该现象称为梯度爆炸问题。
二、梯度消失于梯度爆炸的产生原因
1. 反向传播与链式法则
目前,使用深层的神经网络可以解决很多比传统机器学习更复杂的规则,神经网络中的每一层都是一个非线性激活函数,整个神经网络为多层非线性层堆叠而成,是一个复合非线性多元函数:
如何更新每一层的权值呢? —— 反向传播
具体反向传播相关知识可见CS224n笔记-Lecture5-backpropagationLSTM,CNN等等神经网络使用的都是链式法则(chain rule)来更新权值
Loss Function得到的损失反向传播,权值更新公式为:
应用链式规则,得到的一层权重的表达式为:
其中h即为隐藏层的激活函数
链式法则:
每一部分都是一个雅克比行列式(Jacobian):
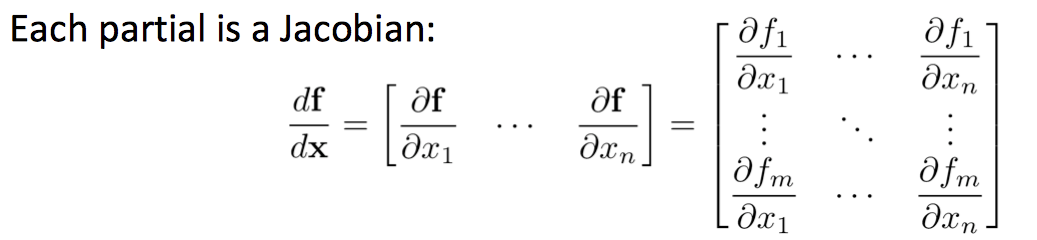
因此有表达式:
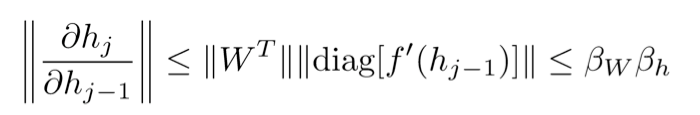
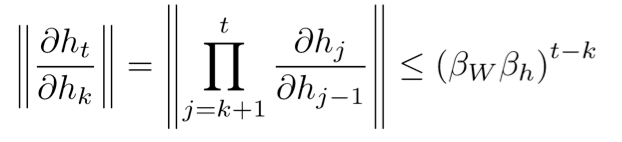
因此,
可以很快地变得特别大或特别小。
例如
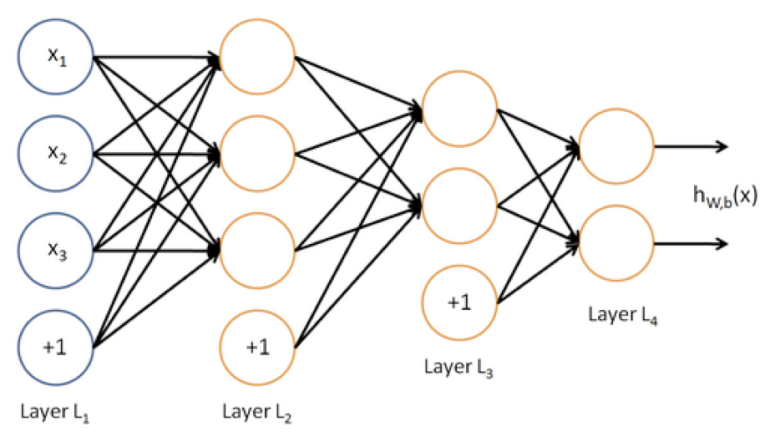
对于上图所示的网络,有其中,
可以很快地变得特别大或特别小。 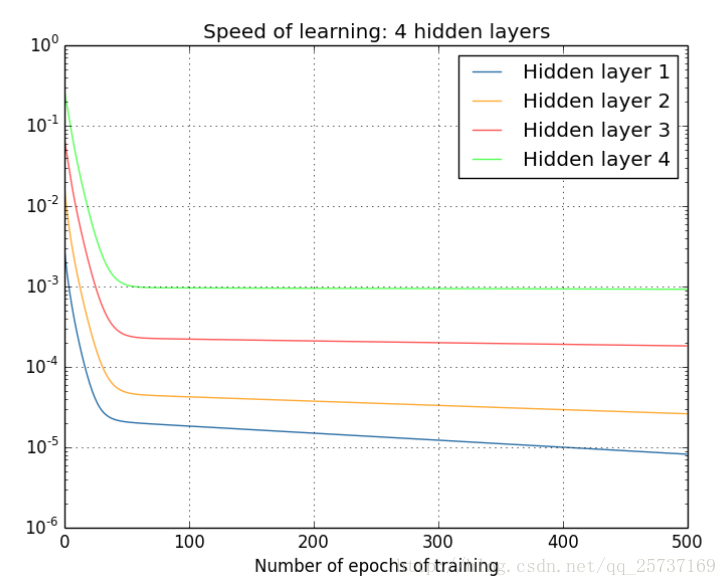
2. 激活函数
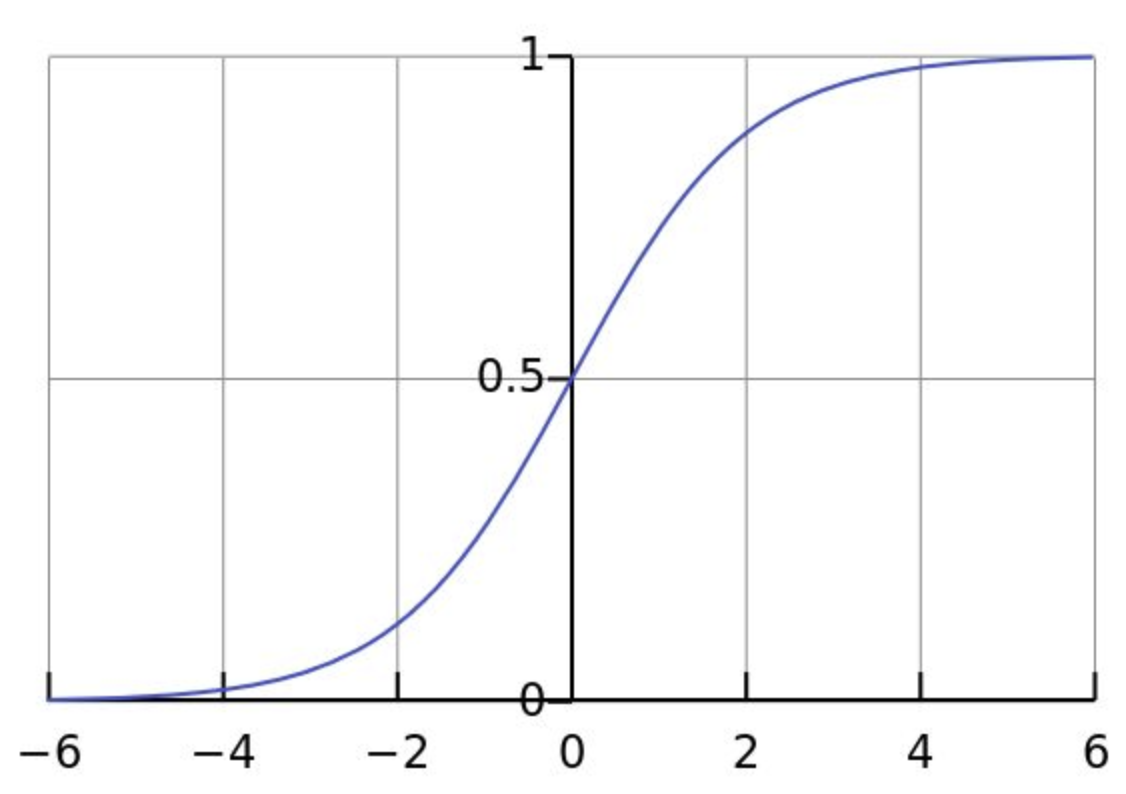
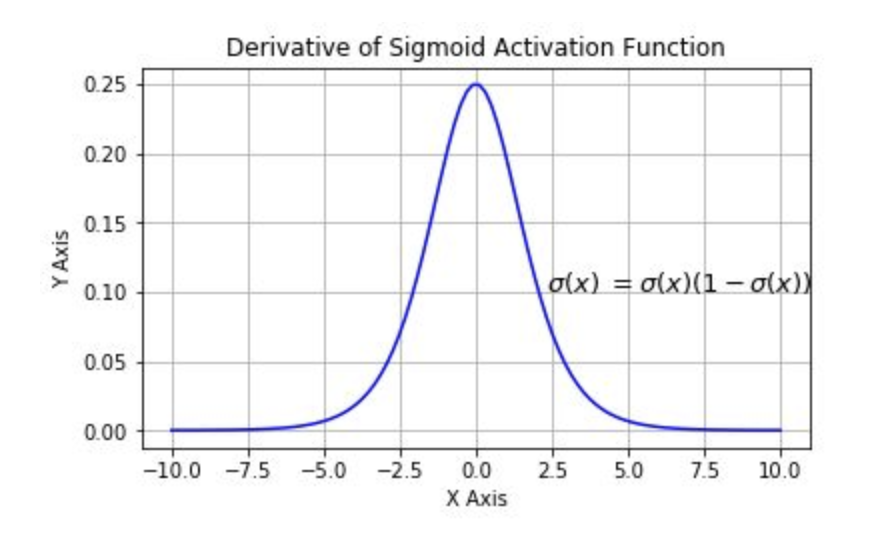
计算权值更新的时候需要计算上一层激活函数的偏导,如果激活函数选择的不好,很容易产生梯度消失与梯度爆炸。例如sigmoid函数,下图为sigmoid函数与其导数图像,可见梯度永远小于0.25。
三、怎么解决梯度消失与梯度爆炸问题
方法1. 逐层训练微调
该方法的思想是对网络的每一个隐藏层进行逐层训练,训练好一层后再以该层输出作为输入训练下一层网络,训练完所有隐藏层后再放到一起训练,使用反向传播进行微调。该方法目前使用较少。
方法2. 梯度剪切、正则
梯度剪切是针对梯度爆炸提出的,思想为设置一个梯度剪切阈值,在更新梯度时,如果梯度超过这个阈值,就令梯度为阈值,防止梯度过大。
权重正则化也可以解决梯度爆炸。其思想为在损失函数后加上一个正则项。比较常见的为l1,l2正则。
方法3. 使用Relu等激活函数
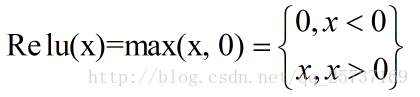
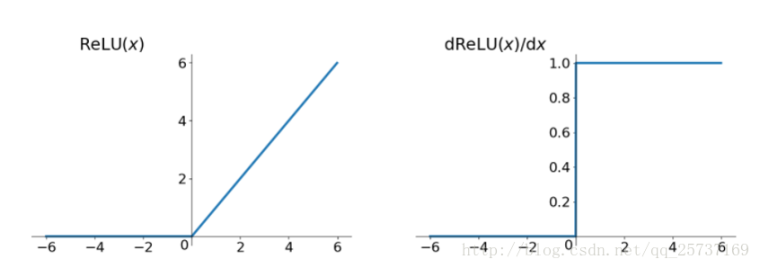
Relu的优点
- 计算速度快
- 解决梯度消失,爆炸问题
Relu的缺点
- 由于负数部分恒为0,会导致一些神经元无法激活(可通过设置小学习率部分解决)
- 输出不是以0为中心的
方法4. Batch Normalization
方法5. 残差结构
方法6. LSTM
参考
- CS224n Lecture9
- 详解机器学习中的梯度消失、爆炸原因及其解决方法
-
怎么定位梯度消失和梯度爆炸的问题呢??
-
这个只能通过训练中的现象判断。梯度消失和梯度爆炸会使模型难以收敛。梯度消失会使浅层的权值基本不变或者变化很慢。其实我觉得梯度消失问题并不是突然出现的bug,是几乎所有反向传播网络都会有的问题,只能削弱梯度消失的影响。
如果是梯度爆炸就很好发现了,梯度爆炸会使浮点数运算产生溢出(NaN)。
-
- 出现梯度消失的时候一般可以观察到网络中除了最后一层权值比较大,前面的权值基本相差不大,梯度下降没有对其体现效果,或者说梯度被样本的随机性 / 网络的深度给抹平了。这时候需要考虑修正模型,使其更适应数据的特性,而不能一味期望一个 NN 拟合所有的特征和问题(如对 grid-pattern data 引入卷积层、对 sequence data 引入自身输入 / 输出等)
- 梯度爆炸就跟 @hunto 说的一样,
NaN,权值直接发散