CS231n Convolutional Neural Networks for Visual Recognition - 要点记录
-
论坛排版不好看,可见我的博客
CS231n Convolutional Neural Networks for Visual Recognition - 要点记录Lecture2
1. Distance Metric
1.1 L1 (Manhattan) distance
1.2 L2 (Euclidean) distance
Lecture3
1. SVM Hinge loss
2. Regularization
Prevent overfit.
2.1 L1 regularization
2.2 L2 regularization
2.3 Elastic net (L1 + L2)
3. Softmax -- score -> probabilities
4. Softmax cross-entropy loss
5. Gradient descent
-
Lecture4
- Backpropagation
- Chain rule
Lecture5
1. Fully Connected Layer -- change dims & length
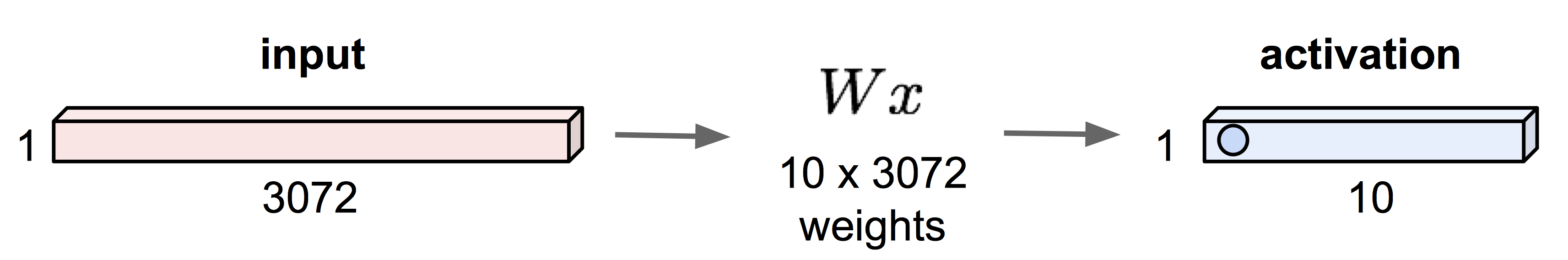
2. Convolution Layer
3. Pooling Layer
- Max pool
- Average pool
Lecture6
1. Mini-batch SGD
Loop:
- Sample a batch of data
- Forward computation & calculate loss
- Backprop to calculate gradients
- Optimizer to update the parameters using gradients
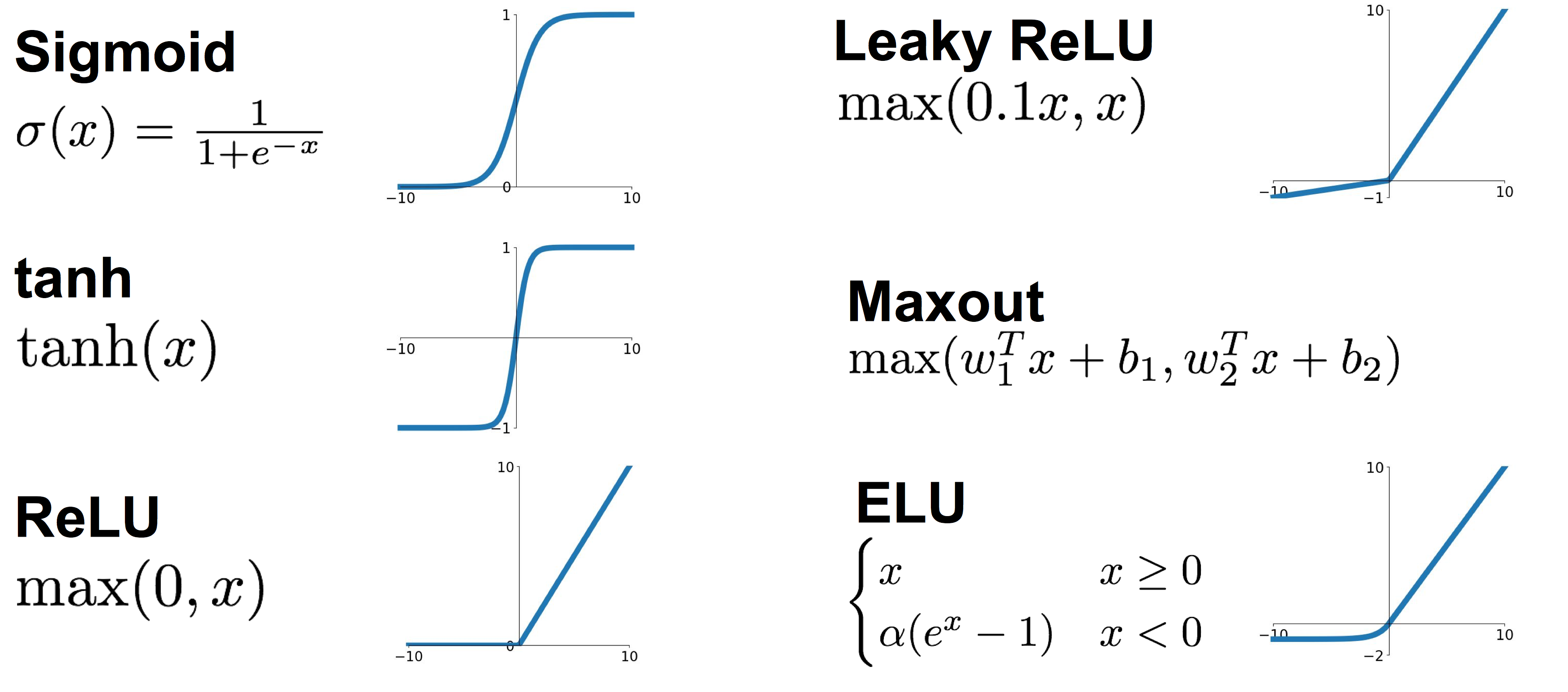
2. Activation Functions
-
Sigmoid
-
tanh
-
ReLU
3. Vanishing Gradients & Exploding Gradients
4. Weight Initialization
- Small randon numbers -- NO!
- Xavier initialization
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in) - ...
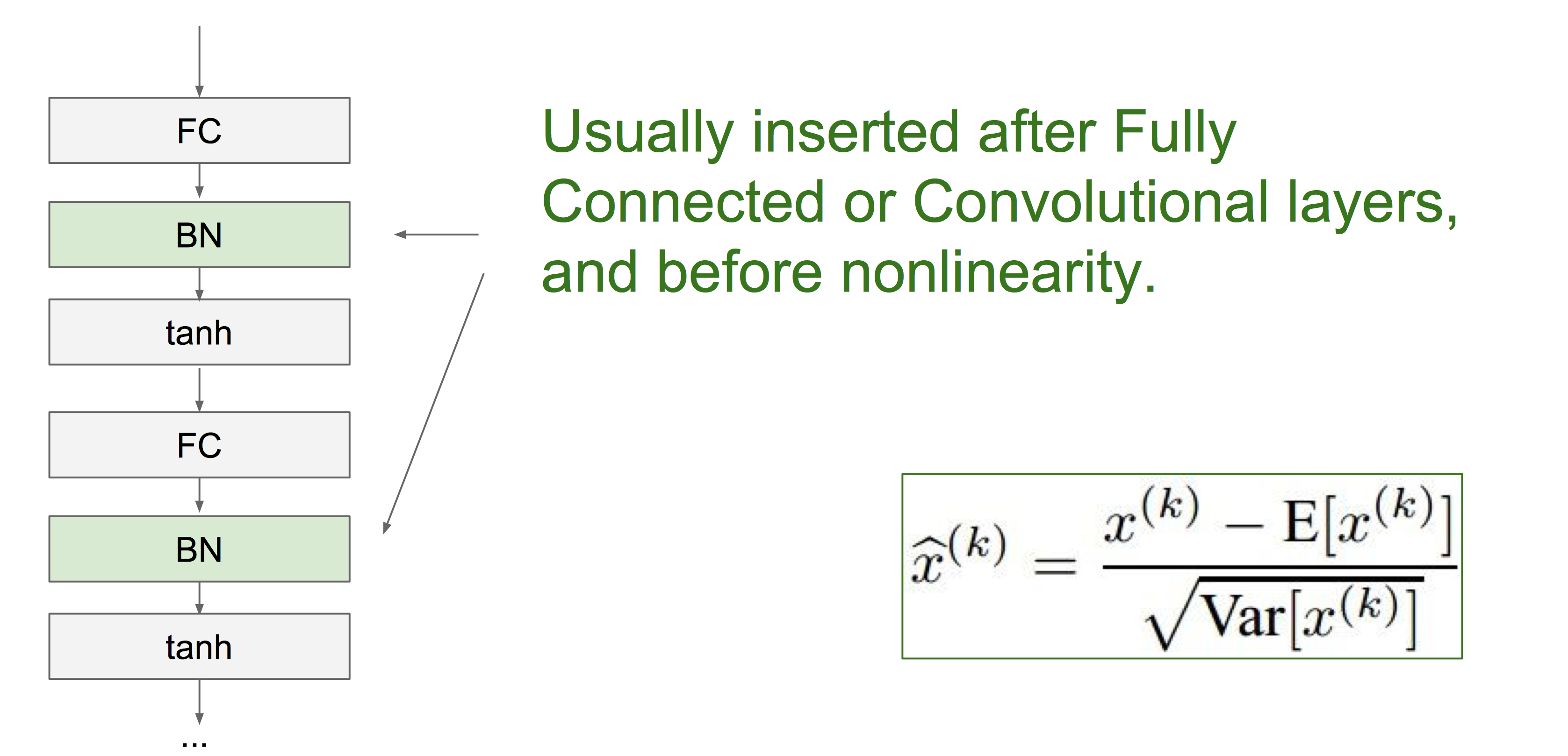
5. Batch Normalization
- Compute the empirical mean and variance independently for each dimension
- Normalize
Usually inserted after Fully Connected or Convolutional layers, and before nonlinearity.
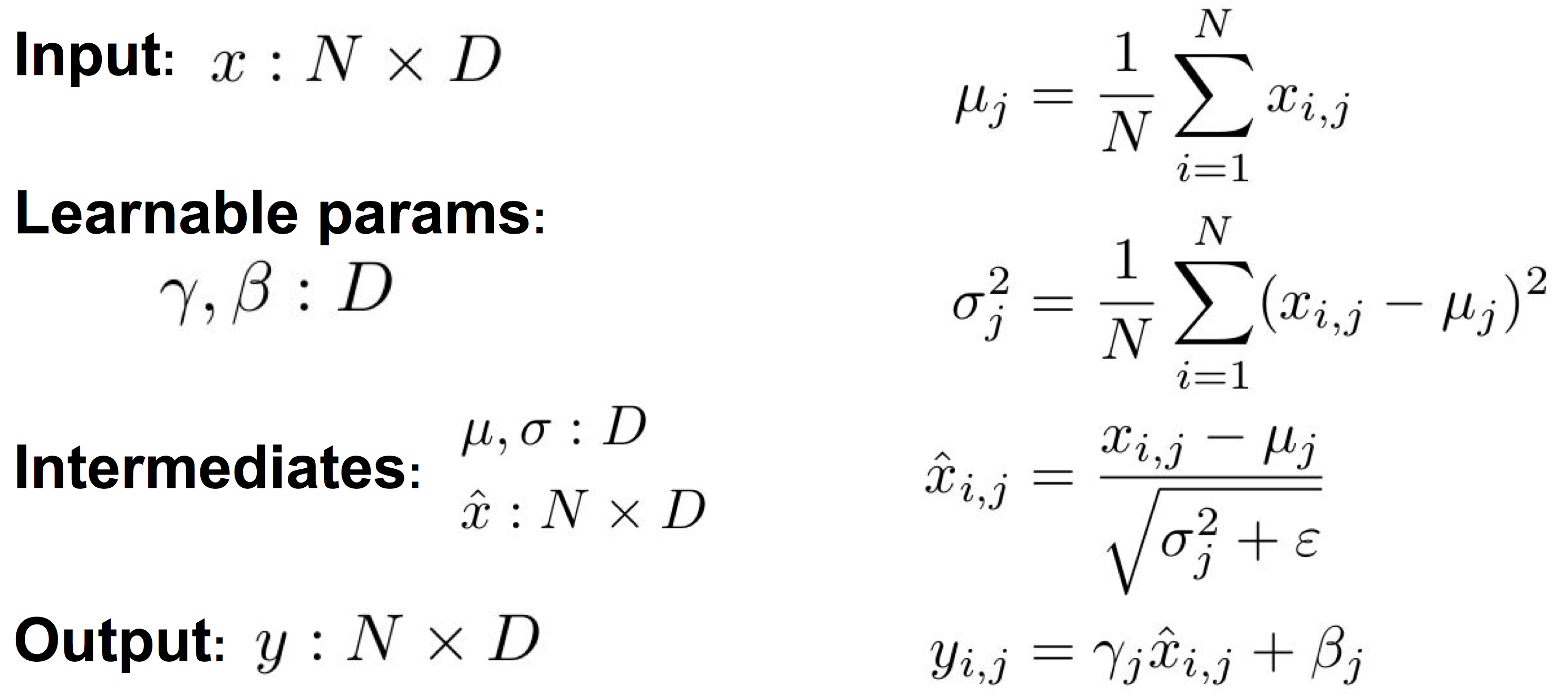
Features
- Improves gradient flow through the network
- Allows higher learning rates
- Reduces the strong dependence on initialization
- Acts as a form of regularization in a funny way, and slightly reduces the need for dropout, maybe
-
Lecture7
1. Optimizer
- SGD
- SGD + Momentum
- Nesterov Momentum
- AdaGrad
- RMSProp
-
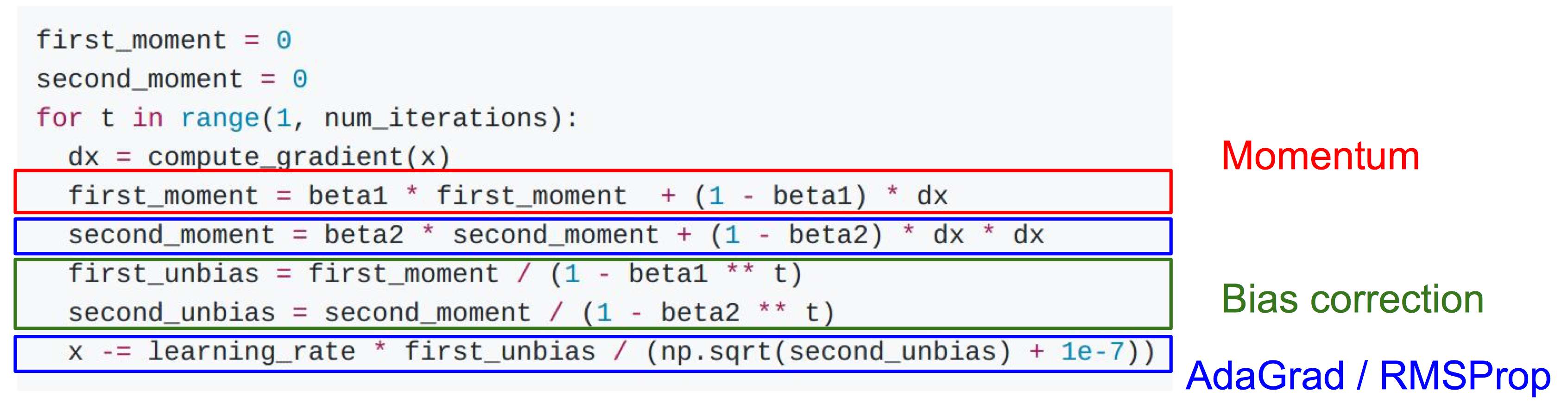
Adam (almost)
first_moment = 0 second_moment = 0 while True: dx = compute_gradient(x) first_moment = beta1 * first_moment + (1 - beta1) * dx second_moment = beta2 * sencond_moment + (1 - beta2) * dx * dx x -= learning_rate * first_moment / (np.sqrt(second_moment) + 1e-7) -
Adam (full form)
2. Dropout
