直播2018之江杯全球人工智能大赛 视频识别&问答
-
比赛链接
20180823:
1.获取video的length(秒),json保存
2.统计question与answer的词频
3.C3D与two-stream论文,获取video_feature
-
哦 . . . .
-
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition笔记
摘要:
发掘了对于视频的动作识别,如何设计高效卷积网络结构。时间段网络结合了稀疏的时间采样政策与视频层监督。可视化并证明了时间段网络的优秀。
简介:
第一段:传统的卷积(端到端)无法很好地处理视频。
第二段:难点1——长期结构模型难以利用。为利用长期结构模型,通常采样预定义采样间隔,但是当应用于长视频序列时,这会导致过度计算上的损失,并带来了丢失视频的重要信息超过最大序列长度的风险。难点2——数据集少。
第三段:该框架采用稀疏采样方案提取长视频序列上的短片段,其中样本沿时间维度均匀分布。
第四段:优化措施有跨模态预训练、正则化、增强数据增强。四种输入方式的实证研究:单个RGB图像、堆叠RGB差分、堆叠光流场和堆叠翘曲光流场。
第五段:在UCF101和HMSB51上表现良好。
相关工作
C3D。我们的方法不同于这些端到端的深度ConvNets,因为它新颖地采用了稀疏时间采样策略,这使得效率更高,学习整个视频而不受序列长度限制。
时间结构建模。Gaidon注释视频的原子动作,提出ASM;Niebles利用潜伏的变异去模拟复杂动作的时间分解,采用潜支持向量机去学习模型参数。W和P将时间上复杂网络的分解拓展到分级模式(各自使用LHM和SGM)。W设计了顺序骨架模型去捕捉动态偏序集之间的关系……F模拟了BOVW表示的时间演化。但这些措施都无法集成模拟时间结构的端到端的学习方案。我们提出的时间段网络是第一个解决这一问题的框架。
时间段网络识别动作
时间段网络通过作用于短片断序列(随机稀疏采样得到),去充分利用视频信息。将Video分割成K个部分
得到时间段网络模型的一个序列片段如下: 不同片段的类分数被分段一致性函数融合以产生分段一致性,这是视频级别的预测。
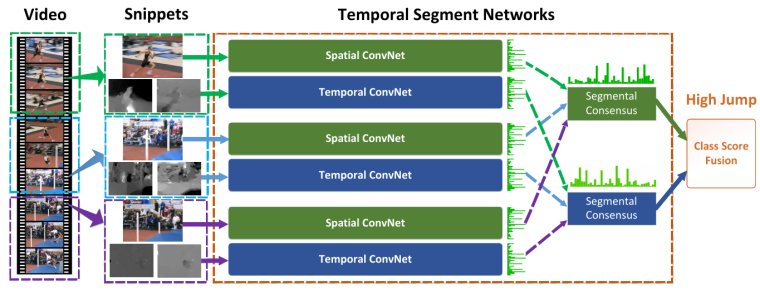
在这里我们选择广泛使用的H.Softmax函数与标准分类交叉熵损失结合,K可取3,函数G取均匀平均效果好。
拆项进行梯度计算:
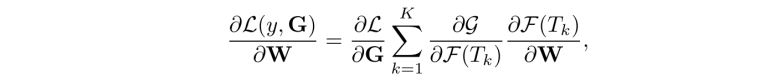
训练
细节:RGB difference;BN-inception;在提取翘曲的光流时,首先估计单应矩阵,然后补偿摄像机运动。 (后文有提到average pooling效果最好)
训练步骤:利用RGB模型来初始化时态网络。首先,我们通过线性变换将光流场离散到0到255之间的间隔,这一步骤使得光流场的范围与RGB图像相同。然后,我们修改了RGB的第一卷积层的权值,处理光流场输入的模型。具体地说,我们对RGB信道上的权重进行平均,并通过时态网络输入的信道数量来复制这个平均值。这种初始化方法对时态网络的工作效果很好,在实验中减少了过拟合的影响。
训练细节:对dropout ratio,spatial取0.8;temporal取0.7。
数据增强:旧采用DOM裁剪和水平翻转,新采用角裁剪和缩放。在角点裁剪技术中,所提取的区域仅从图像的角点或中心选择,以避免隐式地聚焦在图像的中心区域。在多尺度裁剪技术中,我们将用于ImageNet分类的尺度抖动技术[9]应用于动作识别。我们提出了一个有效的实现规模抖动。我们将输入图像或光流场的大小固定为256×340,并且从{256,224,192,168}中随机选择裁剪区域的宽度和高度。最后,这些裁剪区域网络培训将被调整到224×224。事实上,这种实现不仅包含规模抖动,而且牵涉到纵横比抖动。
测试
25 RGB frames;4 corners and 1center;
我们通过将权重设置为1和时间流为1.5来给予空间流更多的学分。当同时使用法向光流场和弯曲光流场时,时间流的权重被分成1用于光流,0.5用于弯曲光流;融合预测在SOFTMax标准化之前的25帧和不同流的分数。
可视化
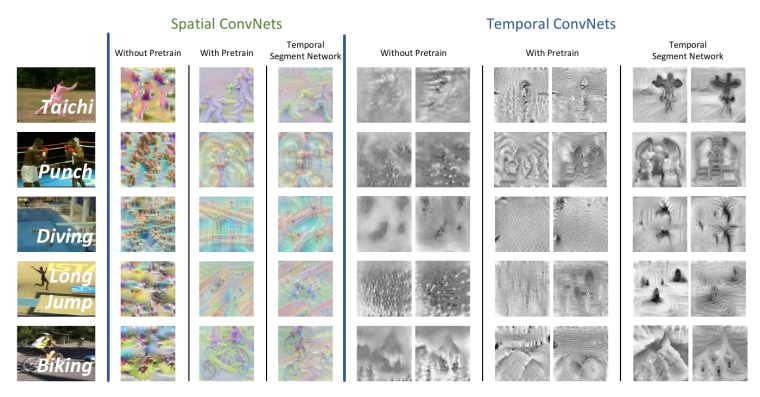
(注重模拟远程结构)
-
@lamb 你这个怎么没有后续了,ljyy