Attention Mechanism系列2 - Self-Attention & Transformer
-
References
[1] Attention Is All You Need , 12 Jun 2017
[2] CS224n笔记 - lecture12 - All Attention & TextCNN
[3] Attention机制详解(二)——Self-Attention与Transformer
Attention Mechanism的本质
Attention最初是在计算机视觉中提出,后被应用到NLP中。
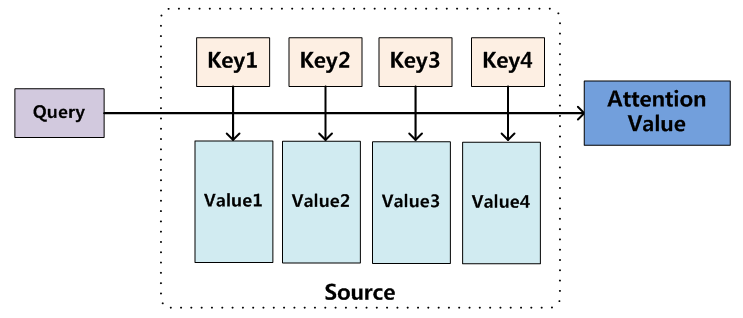
Attention mechanism本质上可以看作是一个query到一系列key-value的映射,计算attention主要分为三个步骤。第一步为计算query与key的相似度,常见的计算相似度的方法有点乘、拼接、感知机等;第二步为使用softmax将query与各key的相似度归一化得到权重;第三步将权重与value进行加权求和得到最后的值。
在通常的NLP任务中,key和value都是一个值,即 key = value 。
Self Attention
Self attention由google在[1]中提出,其使用了query本身的变换作为key与value计算attention,实际上就是一种新的序列特征变换方式,可以将边长的序列变换为另一个边长序列。其可以替换掉原来的RNN、CNN方式对序列特征进行编码(如将词向量组成的句子编码为单个向量)。在介绍self-attention之前,我们先了解构成self-attention的基本框架 ——
Scaled Dot-Product Attention。Scaled Dot-Product Attention
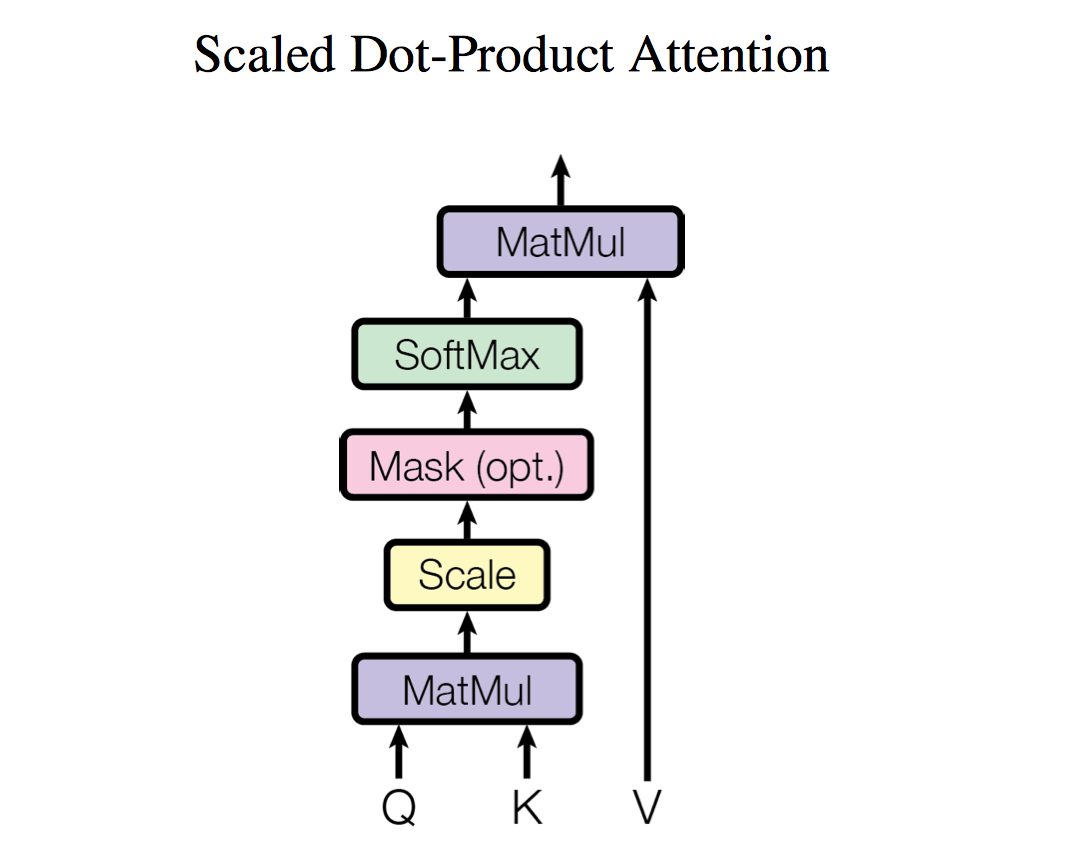
Scaled Dot-Product Attention顾名思义,就是使用点积计算的attention,为了防止其计算的值过大,使用根号下key的维度对其进行了缩放: 我们的self attention就是Q,K,V均为同一值经过线性变换而成的
Scaled Dot-Product Attention:Multi-Head Attention
Multi-Head Attention实际上就是将Q, K, V经过个不同的线性变换后分别作 Scaled Dot-Product Attention,最后concat到一起再过一层线性层得到输出。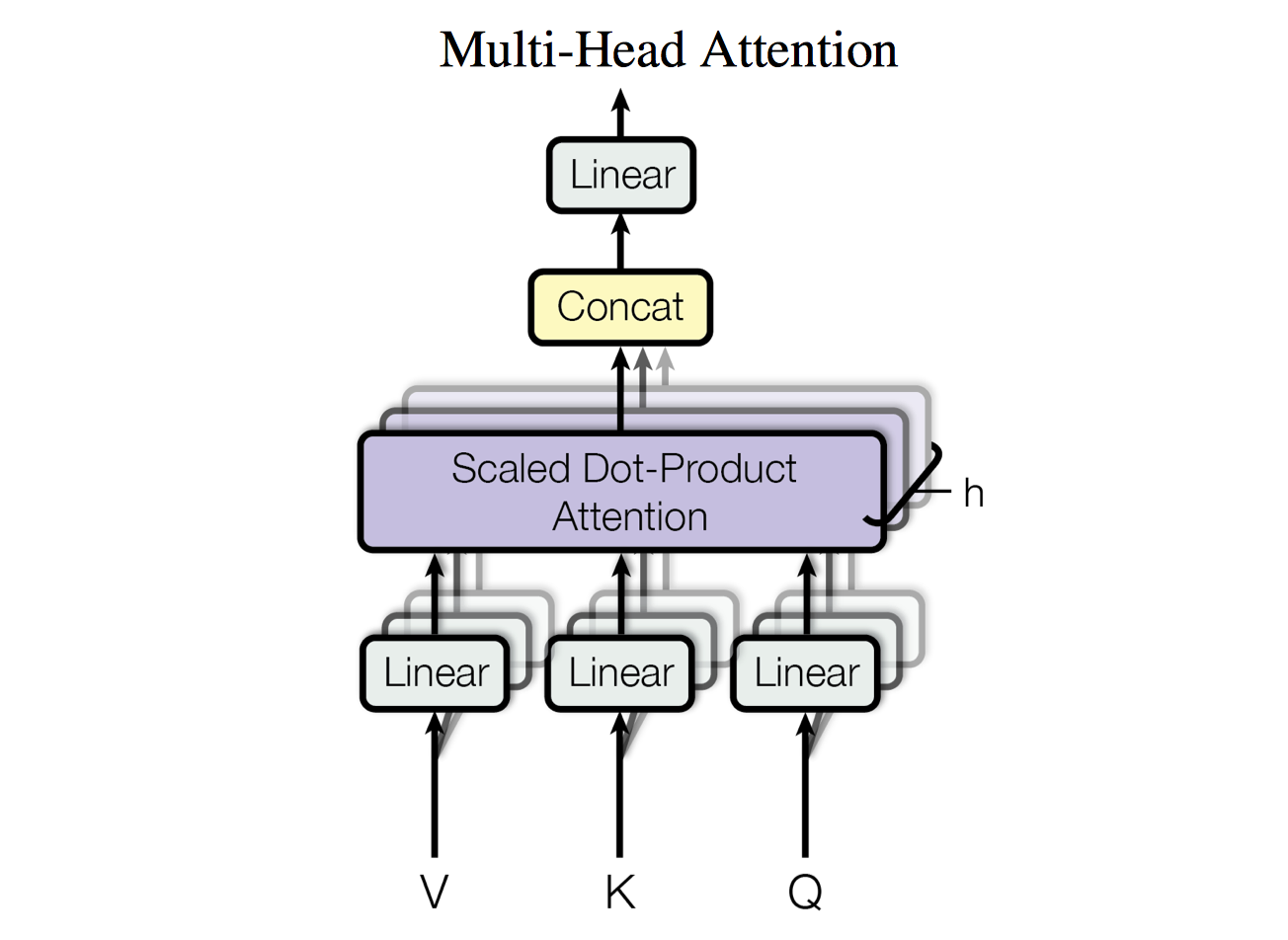
Where
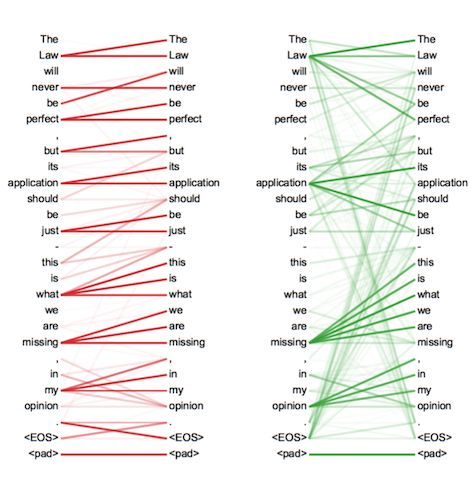
is a matrix, is a matrix, is a matrix, is a matrix. 这样每个head都可以学到不同表示空间中的特征,如下图,两个head学习到的Attention侧重点不同:
Why Self-Attention
在这篇论文中,作者使用self-attention代替了传统的RNN、CNN等sentence embedding方式,在这一小节就介绍了为什么要这样做。
Self-Attention与RNN和CNN的对比如下表:

从这里我们可以看到,要捕捉一个dependence,self-attention需要的最大路径最小,同时支持并行计算。
Transformer
[1]中提出的transformer结构如下图:

其最大的特点是没有使用CNN、RNN,仅使用Attention实现这一模型。与Seq2Seq一样,模型也分为encoder和decoder部分,encoder主要使用了multi-head的self-attention,而decoder则多了一层attention,第一层multi-head self-attention是将之前生成的输出作为输入,再将该层输出作为query输入到下一层attention中,下一层attention的key和value来自于encoder。
总结
总的来说,Attention Is All You Need这篇论文提出的模型具有很大的启发作用,其创新的self-attention也提示我们attention不仅仅是可以作为encoder到decoder的输出,而是可以用于网络中的任意一层对特征进行变换。同时这篇论文为了实现all attention,做了很多的trick,比如捕捉顺序信息的Positional Encoding,缩短网络传播路径的add操作,layer normalization等等,感兴趣的可以看CS224n笔记 - lecture12 - All Attention & TextCNN。