Evaluation metrics for generation based models in NLP
-
Evaluation metrics for generation based models in NLP
BLEU
转自: http://www.cnblogs.com/by-dream/p/7679284.html
n-gram
BLEU 采用一种N-gram的匹配规则,原理比较简单,就是比较译文和参考译文之间n组词的相似的一个占比。
例如:
原文:今天天气不错
机器译文:It is a nice day today
人工译文:Today is a nice day
如果用1-gram匹配的话:

可以看到机器译文一共6个词,有5个词语都命中的了参考译文,那么它1-gram的匹配度为 5/6
我们再以3-gram举例:

可以看到机器译文一共可以分为四个3-gram的词组,其中有两个可以命中参考译文,那么它3-gram的匹配度为 2/4
依次类推,我们可以很容易实现一个程序来遍历计算N-gram的一个匹配度。一般来说1-gram的结果代表了文中有多少个词被单独翻译出来了,因此它反映的是这篇译文的忠实度;而当我们计算2-gram以上时,更多时候结果反映的是译文的流畅度,值越高文章的可读性就越好。
召回率修正
面所说的方法比较好理解,也比较好实现,但是没有考虑到召回率,举一个非常简单的例子说明:
原文:猫站在地上
机器译文:the the the the
人工译文:The cat is standing on the ground
在计算1-gram的时候,the 都出现在译文中,因此匹配度为4/4 ,但是很明显 the 在人工译文中最多出现的次数只有2次,因此BLEU算法修正了这个值的算法,首先会计算该n-gram在译文中可能出现的最大次数:
Count是N-gram在机器翻译译文中的出现次数,
是该N-gram在一个参考译文中最大的出现次数,最终统计结果取两者中的较小值。然后在把这个匹配结果除以机器翻译译文的N-gram个数。因此对于上面的例子来说,修正后的1-gram的统计结果就是2/4。 我们将整个要处理的将机器翻译的句子表示为
,标准答案表示为 (m表示有m个参考答案) n-grams表示n个单词长度的词组集合,令
第k个n-gram 比如这样的一句话,”I come from china”,第1个2-gram为:I come; 第2个2-gram为:come from; 第3个2-gram为:from china;
表示 翻译选译文 中出现的次数 表示 在标准答案 中出现的次数 所以各阶n-gram的精度可以用下面的公式计算:
惩罚因子
上面的算法已经足够可以有效的翻译评估了,然而N-gram的匹配度可能会随着句子长度的变短而变好,因此会存在这样一个问题:一个翻译引擎只翻译出了句子中部分句子且翻译的比较准确,那么它的匹配度依然会很高。为了避免这种评分的偏向性,BLEU在最后的评分结果中引入了长度惩罚因子(Brevity Penalty)。
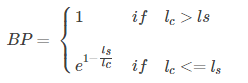
代表表示机器翻译译文的长度, 表示参考答案的有效长度,当存在多个参考译文时,选取和翻译译文最接近的长度。当翻译译文长度大于参考译文的长度时,惩罚系数为1,意味着不惩罚,只有机器翻译译文长度小于参考答案才会计算惩罚因子。 BLEU
由于各N-gram统计量的精度随着阶数的升高而呈指数形式递减,所以为了平衡各阶统计量的作用,对其采用几何平均形式求平均值然后加权,再乘以长度惩罚因子,得到最后的评价公式:
其中,
,N的取值最大为4。 ROUGE
Rouge(Recall-Oriented Understudy for Gisting Evaluation) 一种基于召回率的相似性度量方法。
ROUGE-N
n代表n元组,
是待评测句子中出现的最大匹配的n-grams的个数,从分子中可以看出ROUGE-N是一个基于召回率的指标 ROUGE-L
L即是LCS(longest common subsequence,最长公共子序列)的首字母,因为Rouge-L使用了最长公共子序列。
其中
是X和Y的最长公共子序列的长度,m,n分别表示参考摘要和自动摘要的长度 和 分别表示召回率和率, $精确F_{cls}$就是我们的ROUGE-L ROUGE-N 基于n-gram共现性统计 ROUGE-L 基于最长共有子序列共现性精确度和召回率Fmeasure统计 ROUGE-W 带权重的最长共有子序列共现性精确度和召回率Fmeasure统计 ROUGE-S 不连续二元组共现性精确度和召回率Fmeasure统计