Boosting 算法详解
-
Boosting算法简介
李泽康 2017.10.21 AI Lab
PAC
- Probably approximately correct(概率近似正确)
- Strongly learnable(强可学习)
- Exist an algorithm that requires error can be driven arbitrarily close to 0.
- Weakly learnable(弱可学习)
- Exist an algorithm that only requires the hypothesis that does better than random guessing.
- 一个概念是强可学习的充分必要条件是这个概念是弱可学习的。
Adaboost
-
Adaboost从训练数据中学习一系列弱分类器,并将这些弱分类器线性组合成一个强分类器。
-
它是一个加法模型:
:分类器的系数, :不同的弱分类器 -
损失函数为指数函数:
其中
-
Adaboost 算法原理(以二分类为例)
输入:
-
初始化训练数据的权值分布:
-
对
-
使用权值分布为
训练得到弱分类器: -
计算误差率:
-
计算分类器系数
: -
更新权值分布:
其中,规范化因子
使 成为一个概率分布 -
-
构建分类器的线性组合:
得到最终分类器
-
-
一些分析
-
Adaboost的正则化(防止过拟合):定义learning_rate
,前面有: 加上正则化项有:
-
随 减小而增大,分类错误率越小的基本分类器在最终分类器中的作用越大 -
adaboost不改变数据,只是改变数据的权值
-
Adaboost的训练误差界:
So, adaboost训练误差以指数速率下降!
-
Adaboost使用比较广泛的弱学习器是决策树和神经网络。
-
优势:分类精度比较高,比较灵活可以使用各种回归、分类模型作为弱学习器,不容易发生过拟合
缺点:对异常数据比较敏感,可能对异常数据赋较大权值。
-
GDBT
-
Gradient Decent Boosting Tree
-
Gradient Boosting 就是在函数空间的梯度下降
-
是一个加法模型:
:输入样本, :分类回归树, :回归树的参数, :每棵树权重 -
GDBT算法原理
输入:
- 初始化
- 对
: - 响应:
- 学习第m棵树:
- line search 寻找步长:
- 令
则
- 响应:
- 初始化
-
一些分析
- GDBT就是使用决策树作为基分类器的boosting方法。与Adaboost不同的是GDBT是一个不断拟合残差并直接叠加到F上的过程,残差不断减小,Loss不断减小。
- 在GDBT里,F是泛函空间,f是函数,组合时直接叠加。而Adaboost中f是有权重的,在GDBT中权重信息被吸收到决策树的叶子节点里了。
- 初始化的时候
- 随机
- 用训练样本的充分统计量初始化
- 用其他模型的预测值初始化,例:GDBT在搜索引擎排序中的应用 它使用了RF的输出作为GDBT的初始化,取得了不错的效果。
- 使用GDBT生成新特征,Practical Lessons from Predicting Clicks on Ads at Facebook, 2014.
XGBoost
-
GDBT是函数空间的梯度下降,XGBoost是函数空间的牛顿法
-
相比于GDBT,XGBoost多了正则化项,目标函数变为:
XGBoost采用的正则化项:
, 其中,T:叶子节点数,w:叶节点分数 -
误差函数的二阶泰勒展开:
-
在第t次迭代后:
-
此时损失函数可以写为:
, 需要学习的只有 -
在
处将损失函数进行二阶泰勒展开: 其中,
-
显然,
为常数,可以消掉,目标函数: -
-
这个式子感觉挺复杂,现在我们要把他们统一起来,
表示回归树对每个样本的预测值, 表示每个叶子节点的分数, 表示将样本分到某个叶子节点上。我们可以设集合 ,此时: -
如何来使损失函数最小化:假定树的结构确定了,那么我们需要调整的只是
,当 对 导数为0时,取到极小,此时可以得到最优预测分数和最小损失: -
So, 怎么去确定树的结构呢?
- 暴力解所有树结构(np难啊)
- 贪心,每次分裂一个节点,计算增益:
- exact greedy
- Weighted Quantile Sketch
-
-
并行
-
优势:
- 加入了正则化
- 使用了二阶导信息
- 列抽样来防止过拟合
- Weighted Quantile Sketch
- 样本数据预先排序,存储为block,利于并行
- 可以对缺失值自动处理
-
调参
https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-python/
LightGBM
一个基于决策树算法的分布式梯度提升框架,https://github.com/Microsoft/LightGBM
-
与xgboost的速度比较
Data xgboost xgboost_hist LightGBM Higgs 3794.34 s 551.898 s 238.505513 s Yahoo LTR 674.322 s 265.302 s 150.18644 s MS LTR 1251.27 s 385.201 s 215.320316 s Expo 1607.35 s 588.253 s 138.504179 s Allstate 2867.22 s 1355.71 s 348.084475 s -
内存占用比较:
Data xgboost xgboost_hist LightGBM Higgs 4.853GB 3.784GB 0.868GB Yahoo LTR 1.907GB 1.468GB 0.831GB MS LTR 5.469GB 3.654GB 0.886GB Expo 1.553GB 1.393GB 0.543GB Allstate 6.237GB 4.990GB 1.027GB -
准确率比较:
Data Metric xgboost xgboost_hist LightGBM Higgs AUC 0.839593 0.845605 0.845154 Yahoo LTR NDCG1 0.719748 0.720223 0.732466 MS LTR NDCG1 0.483956 0.488649 0.524255 Expo AUC 0.756713 0.777777 0.777543 -
两者区别:
-
切分算法:
-
xgboost基于预排序(pre-sorted),对所有特征进行预排序,在寻找分割点时代价为O(#data)。很精确,但空间,时间,cache优化不友好。
-
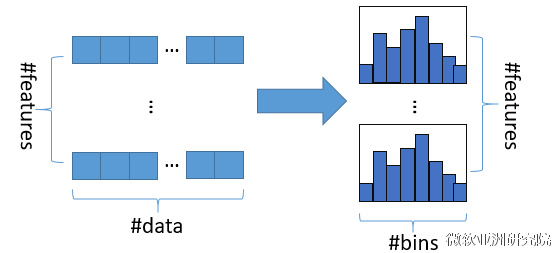
LightGBM使用了Histogram算法,它主要是把连续的浮点值离散化为k个整数,构造一个宽度为#bins(k)的直方图。根据这些离散值寻找最优分割。内存消耗大大降低,这样不需要存储预排序的结果,而且可以只保存特征离散后的值,这个值一般用8位整型存就够了,而在预排序算法中,需要使用32位分别储存index和feature value。内存消耗降低到1/8。时间复杂度从O(#data * #feature)变为O(#bins * #feature)。很好的利用了弱模型集成的思想。
-
-
决策树生长策略:
- xgboost使用level-wise(容易多线程优化,控制模型复杂度,不容易过拟合,但比较低效)
- LightGBM使用带深度限制的leaf-wise
-
LightGBM 的直方图差加速优化,提升一倍速度。
-
高效并行
-
原始
特征并行 的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
-
LightGBM针对这两种并行方法都做了优化
在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;
在数据并行中使用分散规约(Reduce scatter)把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。**基于投票的数据并行(Parallel Voting)**则进一步优化数据并行中的通信代价,使通信代价变成常数级别。
-
-
LightGBM是第一个直接支持类别特征的GBDT工具
-
Reference
- Greedy function approximation a gradient boosting machine. J.H.Friedman(1999)
- XGBoost: A Scalable Tree Boosting System. T. Chen, C. Guestrin (2016)
- CS260 : Lecture 13: Weak vs. Strong Learning and the Adaboost Algorithm
- 《统计学习方法》李航著
- LightGBM(github)
- http://www.msra.cn/zh-cn/news/features/lightgbm-20170105
-
补一篇之前怼 XGBoost 的时候看的,T. Chen 本人写的 Tree Boosting 课件
技术上网 required