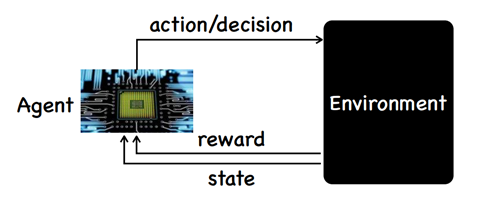
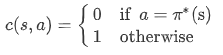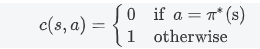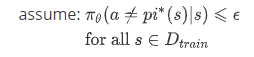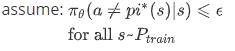Imitation learning: supervised learning for decision making
模仿学习
does direct imitation work
how can we make it work more often
case studies of recent work in (deep) imitation learning
what is missing from imitation learning
课程
###一些定义
因为我们不能一次性观察所有的st,所以使用的是ot进行预测,我们从ot得到ot的分布。
另一个重要的条件(or 假设):st是独立于st−1的,这表明,如果只知道当前的状态而根本不知道过去的状态,如果能精确的知道当前的状态,那么之前的状态并不能帮助model or agent预测之后的状态。所以在状态决策问题中,如果能知道当前的状态的所有信息,则之前的信息对当前的决策不会有任何帮助,当前的知识就是所有需要用来预测动作的所有需要的信息。
deep RL 可以使得RL变得end2end,使得feature 的获得变成一个自动的过程。高质量的feature提升了RL系统的上上限。
examples
机器人系统,使得机器人学会一个功能。
关于价值函数
价值函数是模型优化的目标,为了打成确定的目标,需要根据要求设定与目标相同的价值的函数。
所以无论是什么问题,只要精确的设计了价值函数,总能通过强化学习的方法解决。
rewards
可能是game的score,但是生活中的事情并没有score,没有明确的意义和价值表达,And:
You konw as human agents we are accustomed to operating with rewards thar are so sparse that we only experienced them once or twice in a lifetime if at all.
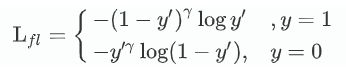
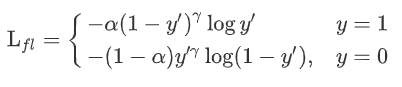
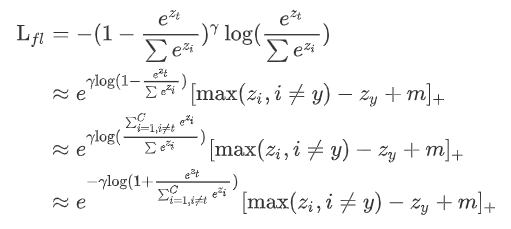
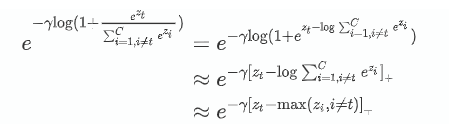
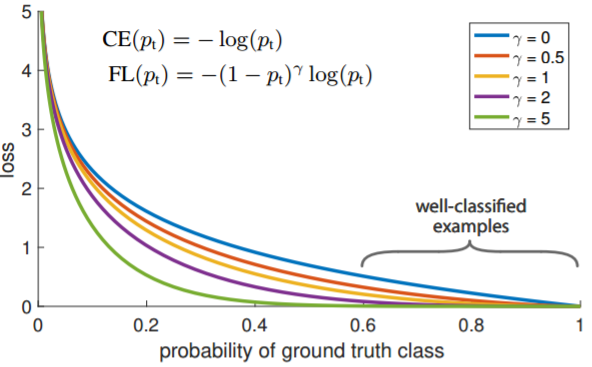
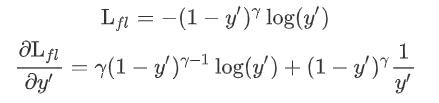

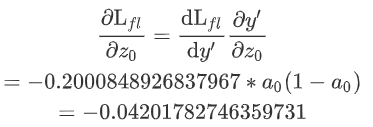
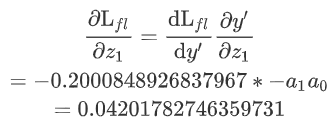
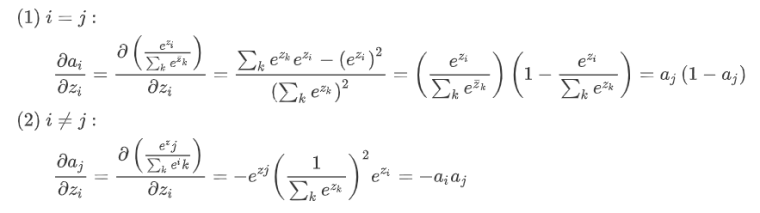

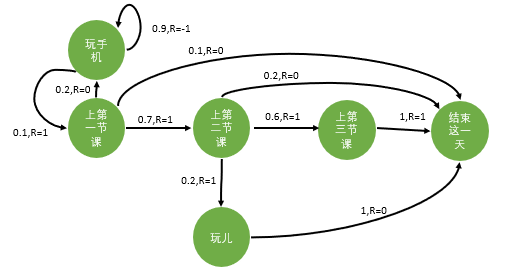
 这种方法并没有使用价值函数
这种方法并没有使用价值函数