@zyh GAN生成数据用来数据扩充挺有意思的,你有什么具体的idea吗?
hunto 发布的帖子
-
CVPR 2020 | GreedyNAS: Towards Fast One-Shot NAS with Greedy Supernet发布在 AI方向
导读
这是我在商汤实习期间以共同一作身份发表的一篇CVPR 2020 poster论文,本论文提出了基于贪心超网络的One-Shot NAS方法,显著提升了超网络直接在大规模数据集上的搜索训练效率,并在标准ImageNet数据集上取得了300M FLOPs量级的SOTA。GreedyNAS论文通过提出一种贪心的超网络结构采样训练方法,改善了训练得到的超网络对结构的评估能力,进而帮助搜索算法得到精度更高的结构。论⽂地址:
GreedyNAS: Towards Fast One-Shot NAS with Greedy Supernet
https://arxiv.org/abs/2003.11236
动机与背景
在目前的神经结构搜索领域中,One-Shot NAS方法由于其搜索开销小被广泛应用,这些方法使用一个权重共享的超网络(supernet)作为不同网络结构的性能评估器,因此,supernet的训练对搜索结果的好坏至关重要。然而,目前的方法一般采用了一个基本的假设,即supernet中每一个结构是同等重要的,supernet应该对每个结构进行准确评估或相对排序。然而,supernet中所包含的结构量级(搜索空间的size)是非常巨大的(如
),因此准确的评估对于supernet来说是非常困难的,导致supernet中结构的表现与其真实表现相关性很差 [1]。
在本篇论文中,我们提出一种贪心超网络来减轻supernet的评估压力,使得supernet更加贪心地注重于有潜力的好结构,而不是全体。具体而言,在supernet训练过程中,我们提出了一种多路径拒绝式采样方法(multi-path sampling with rejection)来进行路径滤波 (path filtering),使得有潜力的好结构得到训练。通过这种方法,supernet的训练从整个搜索空间贪心地缩小到了有潜力的结构组成的空间中,因此训练的效率得到了提升。同时,为了进一步增大有潜力结构的采样概率与提高训练效率,我们基于exploration and exploitation准则,使用一个经验池存储评估过的“好”结构,用来加强贪心度并为后续的搜索提供好的初始点。本论文搜索出的结构在ImageNet (mobile setting) 下取得了 SOTA(state-of-the-art) 的结果。主要思路
巨大的搜索空间带来的评估压力使supernet难以准确地区分结构的好坏,由于所有结构的权重都是在supernet中高度共享的,如果一个差的结构被训练到了,好的结构的权重也会受到干扰。这样的干扰会削弱好网络的最终评估精度,影响网络的搜索结果。同时,对差的结构进行训练相当于对权重进行了没有必要的更新,降低supernet的训练效率。
多路径拒绝式采样
针对上述问题,一个直接的想法就是基于贪心策略,在训练过程中只训练好的结构。但很显然,我们并不知道一个随机初始化的搜索空间中哪些结构是好的。假设对于一个supernet,我们考虑其搜索空间A的一个完备划分,即:
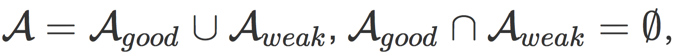
搜索空间可以如上划分为好的空间与差的空间,且好空间中每一个结构的ACC均大于差空间,即
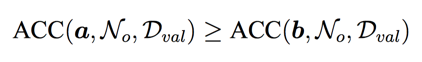
于是,一个理想的采样策略是直接在好空间中进行采样即可。然而根据上面的不等式,确定所有结构中哪些是来自好空间需要遍历整个搜索空间,计算开销是无法接受的。为了解决这个问题,我们首先考虑从全空间中进行的一个均匀采样,那么每个path来自好空间的概率为:
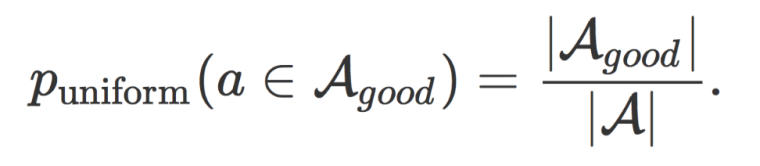
为了得到需要的来自于好空间的结构,我们进一步考虑一个多维的Bernoulli实验,那么有如下的结论:

我们取m = 10和m = 20,对定理1的概率进行绘制,如Figure 2所示,可见这种采样下得到来自好空间中的path的概率是很高的。
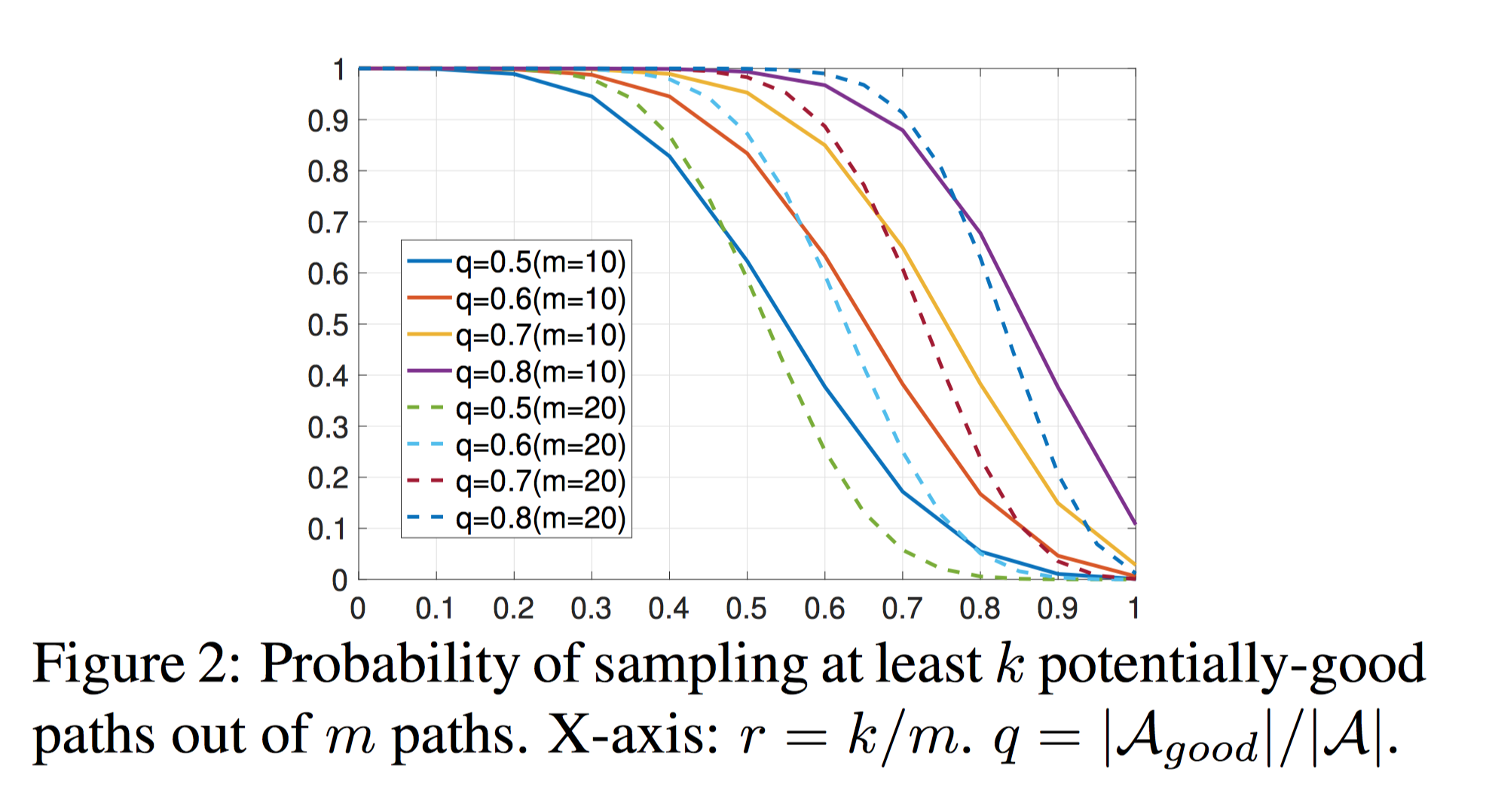
于是,我们可以对采样到的多个结构进行评估筛选的方法提升采样到“好”结构的概率,即每次采样m个结构,从中选取评估指标最高的k个结构进行训练。但是,对结构进行评估需要在验证集上计算其ACC,这样会增加非常多计算量(我们的ImageNet验证集大小为50k)。为了减少评估网络的消耗,我们从验证集中随机选取了一小部分(如1000张图)组成小验证集,并使用在小验证集上的loss作为结构的排序指标。使用小验证集进行评估,在保证评估准确性的前提下,相较uniform sampling方法只增加了很少的计算代价,详见论文实验部分。基于exploration and exploitation策略的路径候选池

在前面提到的路径滤波中,我们通过评估可以区分出较好的结构,为了进一步提升训练效率,受蒙特卡洛树搜索(Monte Carlo tree search)[4] 和 deep Q-learning[5] 中常用的exploration and exploitation策略启发,我们提出使用一个路径候选池用于存放训练过程中评估过的“好”结构,并进行重复利用。具体而言,候选池可以看作是一个固定大小的有序队列,其只会存储所有评估过结构中得分前n(候选池大小) 的结构。
有了候选池的帮助,我们可以选择从搜索空间中或候选池中采样结构。从候选池中采样的结构是好结构的概率更高,但可能会牺牲结构的多样性。为了平衡exploration与exploitation,我们采用ϵ-采样策略,即以一定的概率从整个搜索空间A或候选池P中采样结构α:
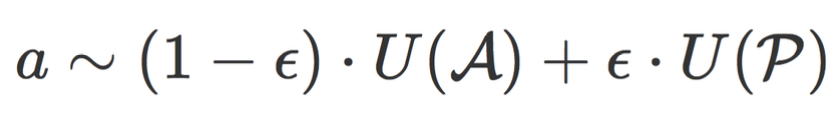
在网络刚开始训练时评估过的结构较少,候选池中存储的结构是好结构的可信度不高,因此从候选池中采样的概率 ϵ 在开始时设为0,并线性增加至一个较高的值(在实验中,我们发现0.8是一个较优的值)。若候选池中的结构都来自好空间,通过使用候选池,定理1中好网络的采样概率q提升为:
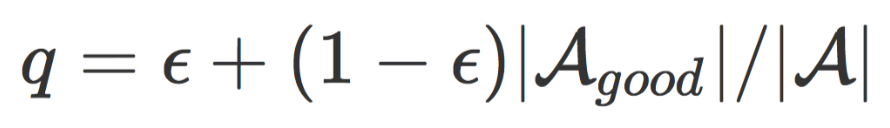
因此,采样10个结构,至少有5个好结构的概率由88.38%提升至99.36% 。

基于候选池的early stopping策略
候选池的更新为supernet的训练情况提供了一个很好的参考。若候选池发生的更新(顺序变换、进出)较少,可以认为超网络中较好的网络维持着一个相对稳定的排序,这也说明此时的supernet已经是一个较好的性能评估器,因此训练进程可以提前结束,而不需要训练至网络完全收敛。
在实际使用中,我们会比较当前候选池P与t轮迭代前的候选池P_t的差异度,若差异度低于某个数值(我们的实验使用0.08),训练停止。差异度的定义如下:
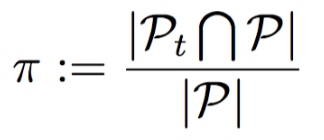

基于候选池的搜索策略
Supernet训练结束后,我们可以使用验证集的ACC评估结构的好坏。本文使用 NSGA-II 进化算法[3] 进行结构搜索。我们在进化算法中使用候选池中的结构进行population的初始化,相较于随机初始化,借助于候选池能够使进化算法有一个更好的初始,提升搜索效率及最终的精度。
如 Figure 3 所示,我们在同一个训练好的supernet上使用了随机初始化与候选池初始化两种方式进行搜索,使用候选池初始化搜索到的结构的准确率平均会比随机初始化要高。
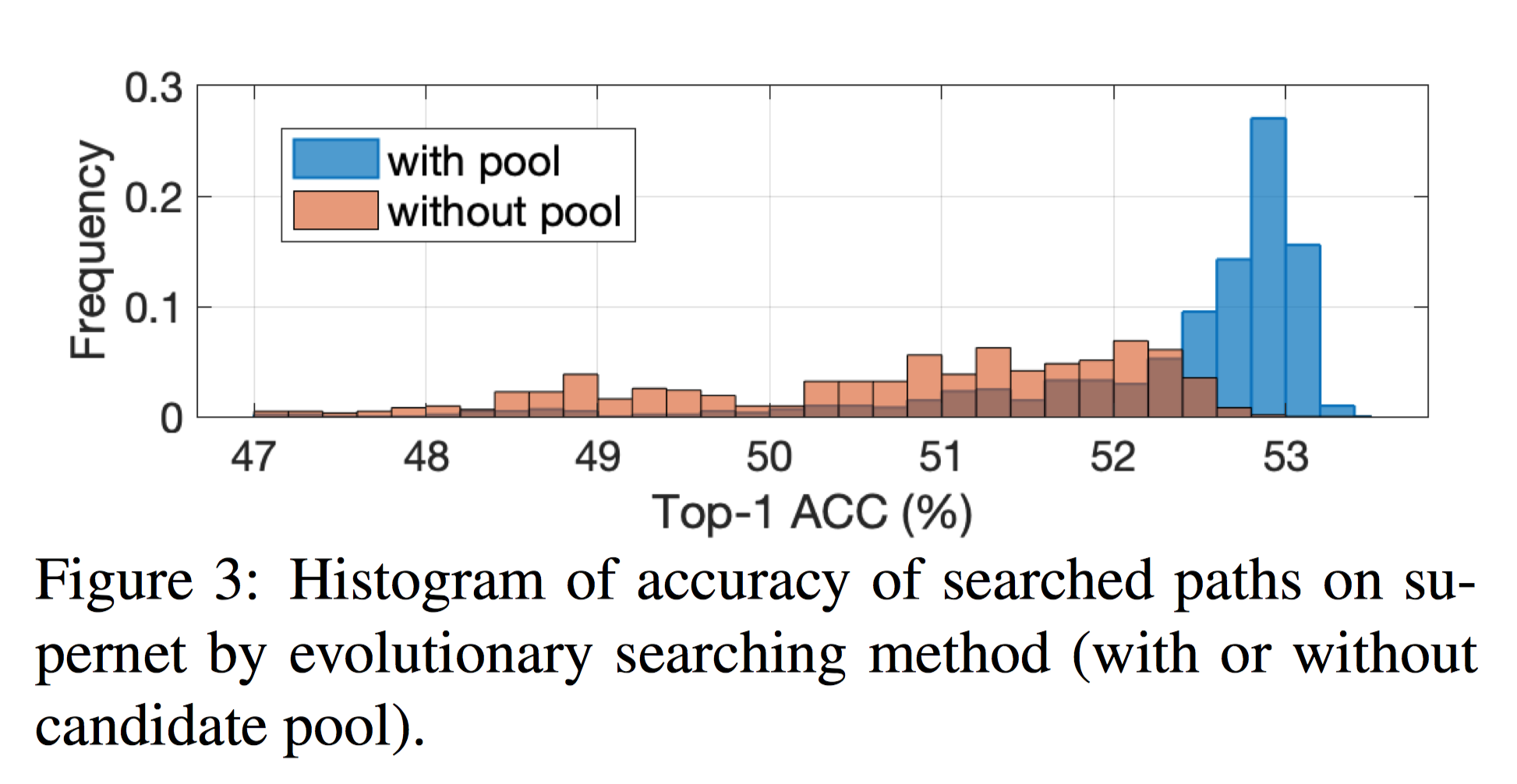
实验结果
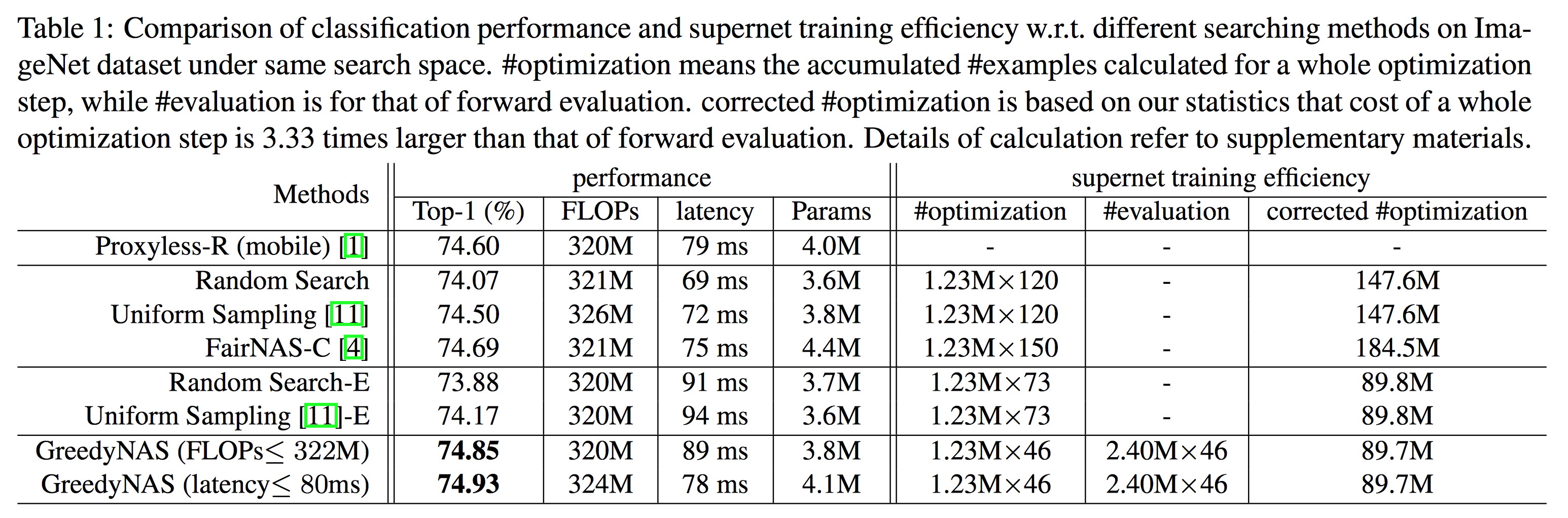
为了与目前的one-shot方法进行对比,我们首先在与 ProxylessNAS[6] 一样的 MobileNetV2 搜索空间上进行结构搜索,结果见 Table 1 。
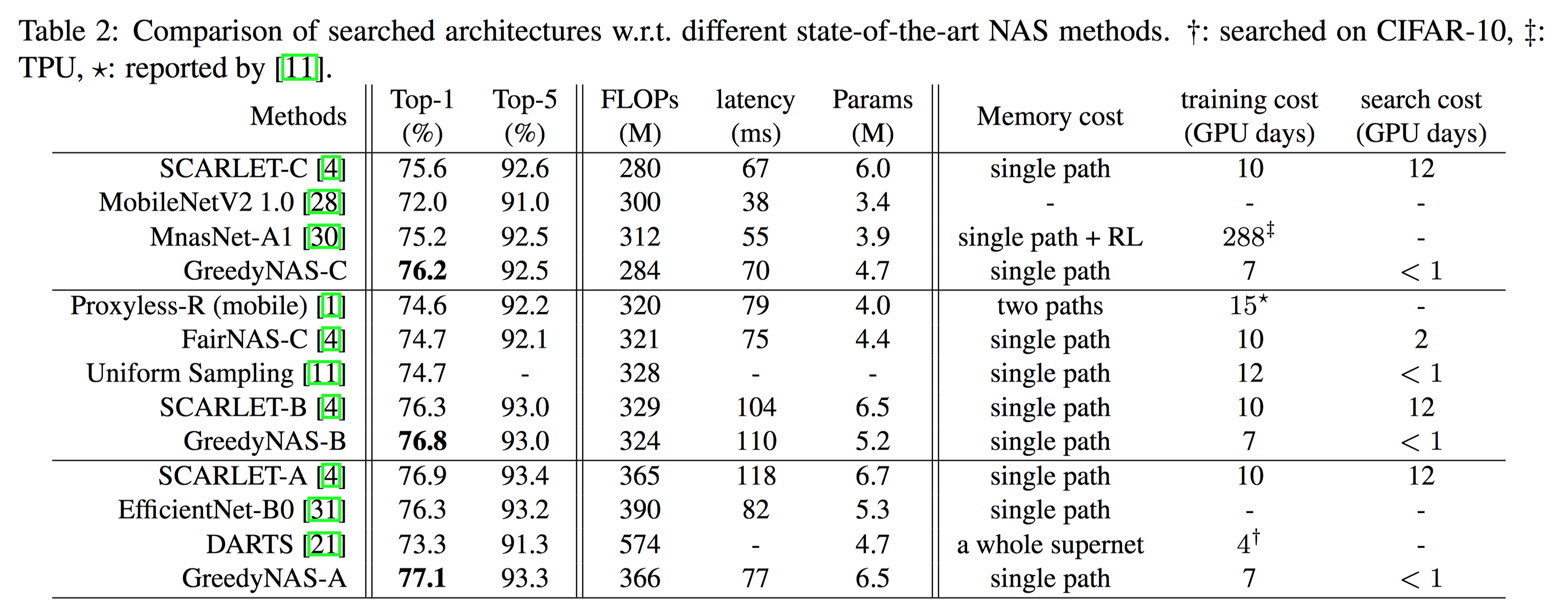
同时为了进一步提升网络性能,我们在加入了SE的更大搜索空间上进行搜索,结果见 Table 2 。
Ablation Study
多路径拒绝式采样中的路径评估相关性
我们对随机初始化、uniform sampling、greedy方法训练得到的supernet下的小验证集指标与完整验证集ACC相关性进行了评估,如 Table 3 所示。可见在小验证集上使用loss相比ACC会得到更高的相关性,我们的贪心方法训练出的supernet有着更好的相关性。

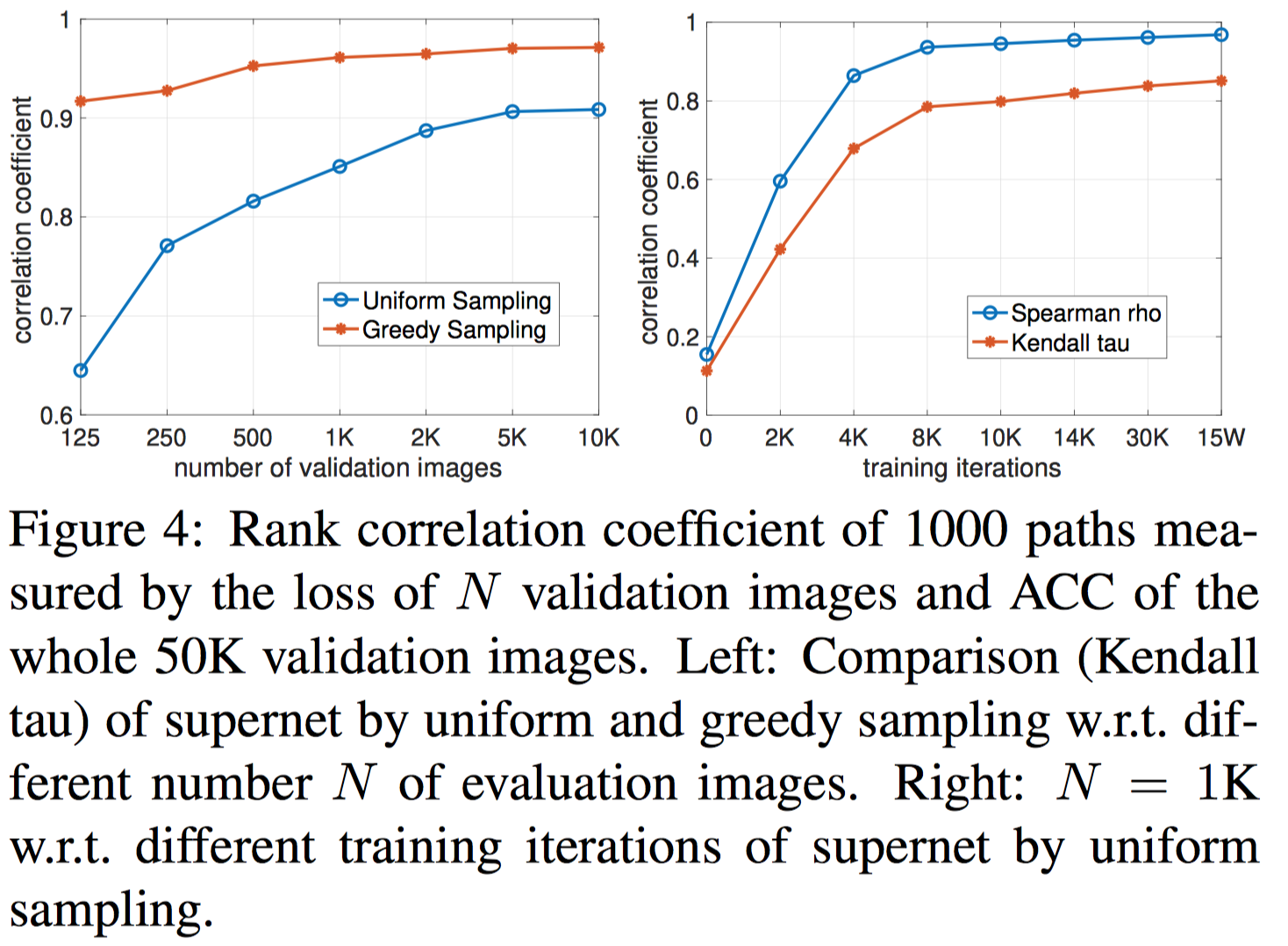
我们对不同大小小验证集与完整验证集的相关性进行了评估(Figure 4 左图),同时对uniform-sampling算法在不同迭代轮数下的相关性作了评估(Figure 4 右图)。可以看出我们的算法在较小的验证集大小上仍能保持较高的相关性,在精度与效率的权衡下,我们最终选取 1000 作为小验证集大小。
对多路径贪心采样及候选池效果的评估
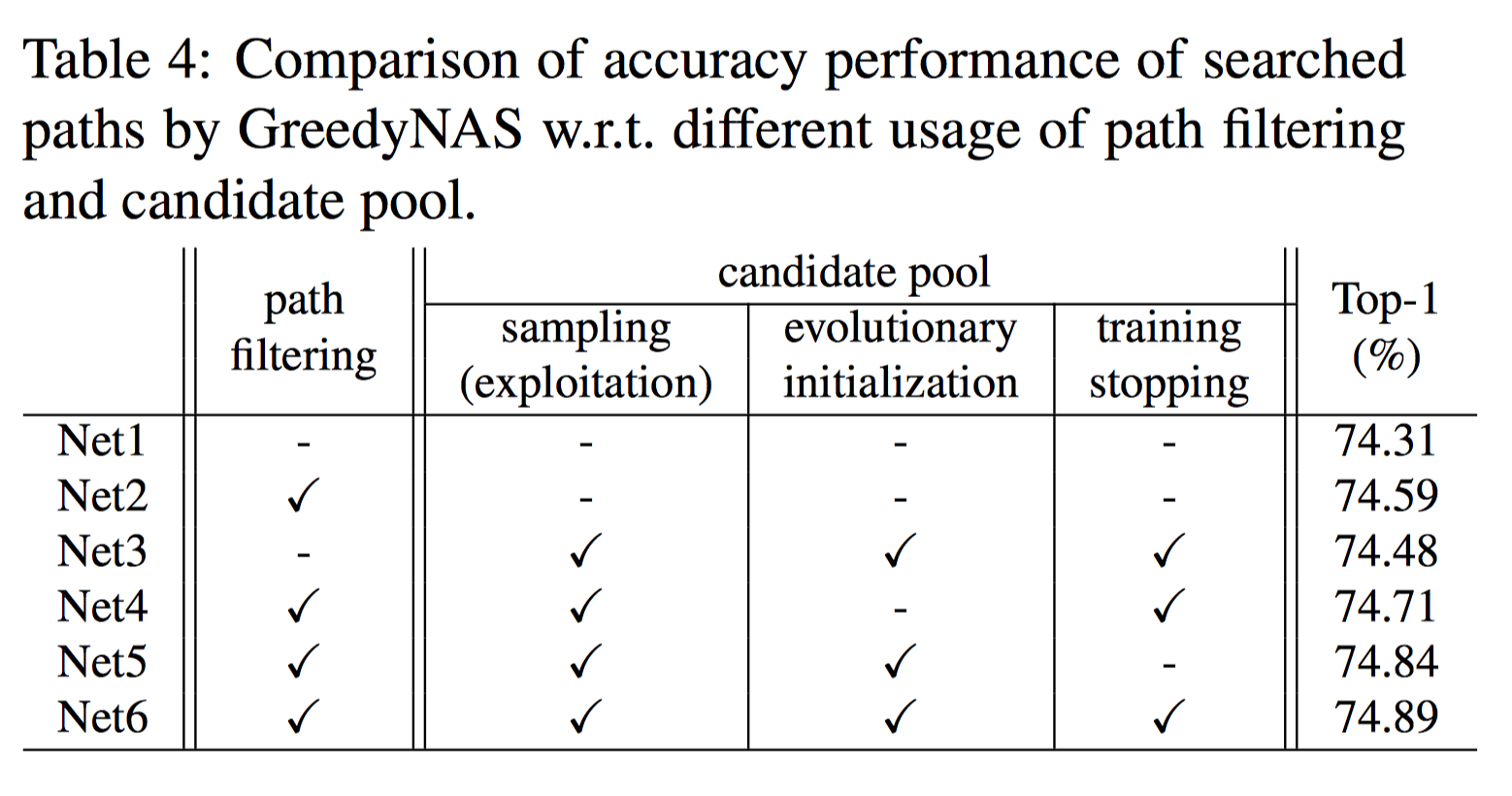
我们在MobileNetV2的search space下评估了多路径贪心采样及候选池的效果,如 Table 4 所示。
总结
超网络训练是单分支One-Shot NAS 方法的关键。与目前方法的对所有分支一视同仁不同,我们的方法贪心地注重于有潜力的好分支的训练。这种贪心地分支滤波可以通过我们提出的多分支采样策略被高效地实现。我们提出的 GreedyNAS 在准确率和训练效率上均展现出了显著的优势。
Reference
[1] Christian Sciuto, Kaicheng Yu, Martin Jaggi, Claudiu Musat, and Mathieu Salzmann. Evaluating the search phase of neural architecture search. arXiv preprint arXiv:1902.08142, 2019.
[2] Zichao Guo, Xiangyu Zhang, Haoyuan Mu, Wen Heng, Zechun Liu, Yichen Wei, and Jian Sun. Single path oneshot neural architecture search with uniform sampling. arXiv preprint arXiv:1904.00420, 2019.
[3] Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and TAMT Meyarivan. A fast and elitist multiobjective genetic algorithm: Nsga-ii. IEEE transactions on evolutionary computation, 6(2):182–197, 2002.
[4] Levente Kocsis and Csaba Szepesv´ari. Bandit based montecarlo planning. In European conference on machine learning, pages 282–293. Springer, 2006.
[5] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
[6] Han Cai, Ligeng Zhu, and Song Han. Proxylessnas: Direct neural architecture search on target task and hardware. arXiv preprint arXiv:1812.00332, 2018.
-
A Brief Introduction to One-Shot Neural Architecture Search发布在 AI方向
An introduction to current mainstream weight sharing NAS methods.
- DARTS
- ProxylessNAS
- Non-parametered (Sampling)
-
RE: PRML - Pattern Recognition and Machine Learning 笔记发布在 AI方向
2. Probability Distributions
2.1 Binary Variables
- Bernoulli Distribution (Binary Distribution)
-
Image Classification Paper List - CNN to Deeper CNN to Efficient CNN to NAS发布在 AI方向
CNN
- AlexNet
- VGG
Deeper CNN with short cut residual module
- ResNet
Efficient CNN
- MobileNet V1/V2
- ShuffleNet V1/V2
- Squeeze-and-Excitation
NAS
- EfficientNet
- DARTS
- MnasNet
- ProxylessNAS
- MobileNet V3
- Single Path One-Shot
- FairNAS、ScarletNAS
- GreedyNAS
-
移动端实时人脸关键点识别综述2.0 - Object Detection综述发布在 AI方向
Object Detection

Object Detection领域目前主要有几种主流方法,一类是Faster RCNN为代表的two-stage模型,一类是以YOLO、SSD为代表的one-stage模型。在速度方面,one-stage网络具有绝对的优势,而在精确度上,Faster RCNN效果会更好。
同时,对于单目标检测,也有一些多级网络做到了非常快的速度,例如MTCNN(Multi-task Cascaded Convolutional Networks),目前我们的项目也是使用的MTCNN进行人脸定位。
在之后的内容中,我会选取几个Object Detection模型进行讲解。
Object Detection更基础的介绍可见 DianAI培训3 - CNN for Object Detection。Multi-stage 级联网络
- Faster RCNN
- MTCNN
One-stage 单级网络
- YOLO
- SSD
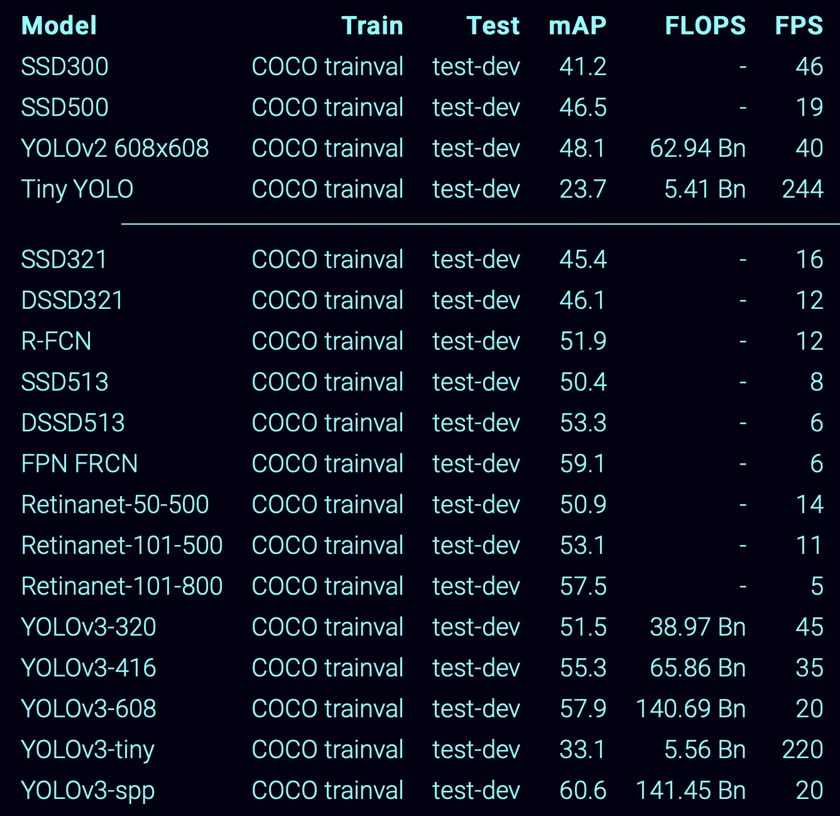
模型效果比较
-
移动端实时人脸关键点识别综述2.1 - Object Detection综述之Faster RCNN发布在 AI方向
References
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- Fast Optimization Methods for L1 Regularization
- 一文读懂Faster RCNN
- DianAI培训3 - CNN for Object Detection
RCNN的发展
在说Faster RCNN之前,我们先简单介绍一下RCNN、FastRCNN。RCNN算法是由RCNN->Fast RCNN->Faster RCNN逐步发展来的,且效果和速度为递增关系,因此可以直接学习Faster RCNN,它的前辈已经淘汰了。
CNN作为特征提取器,对图片特征有很好提取效果,因此有了使用CNN进行物体检测的想法,我们可以采用滑动窗口的方法,将图片resize成不同大小,使用同一卷积网络对图片进行卷积,得到很多个窗口的分类概率及坐标回归,但这样的网络计算量显然太大了,如果我要识别的物体非常小,就需要把图片resize成很大,让卷积网络滑过无数个窗口。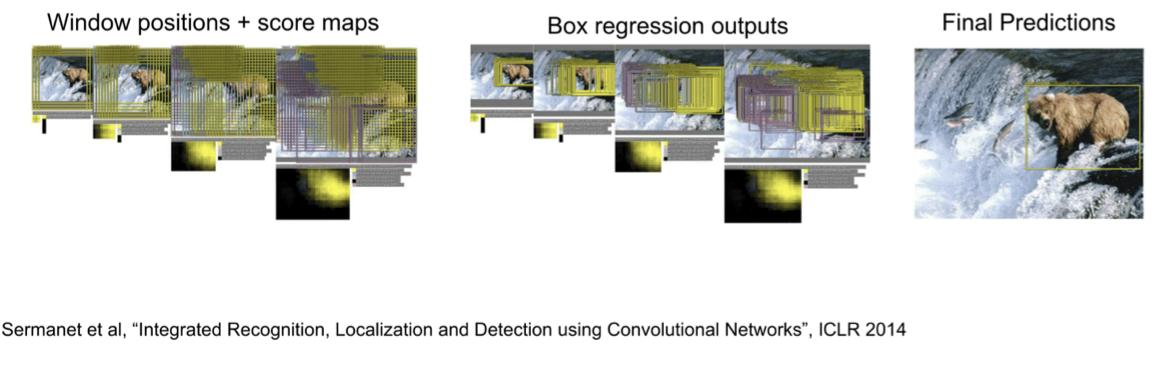
上面的滑动窗口的方法很粗暴,绝大多数窗口都是没有物体的,这样对计算造成了很大的浪费,我们是否能在将图片输入网络之前先确定一些有可能是物体的框?当然可以。
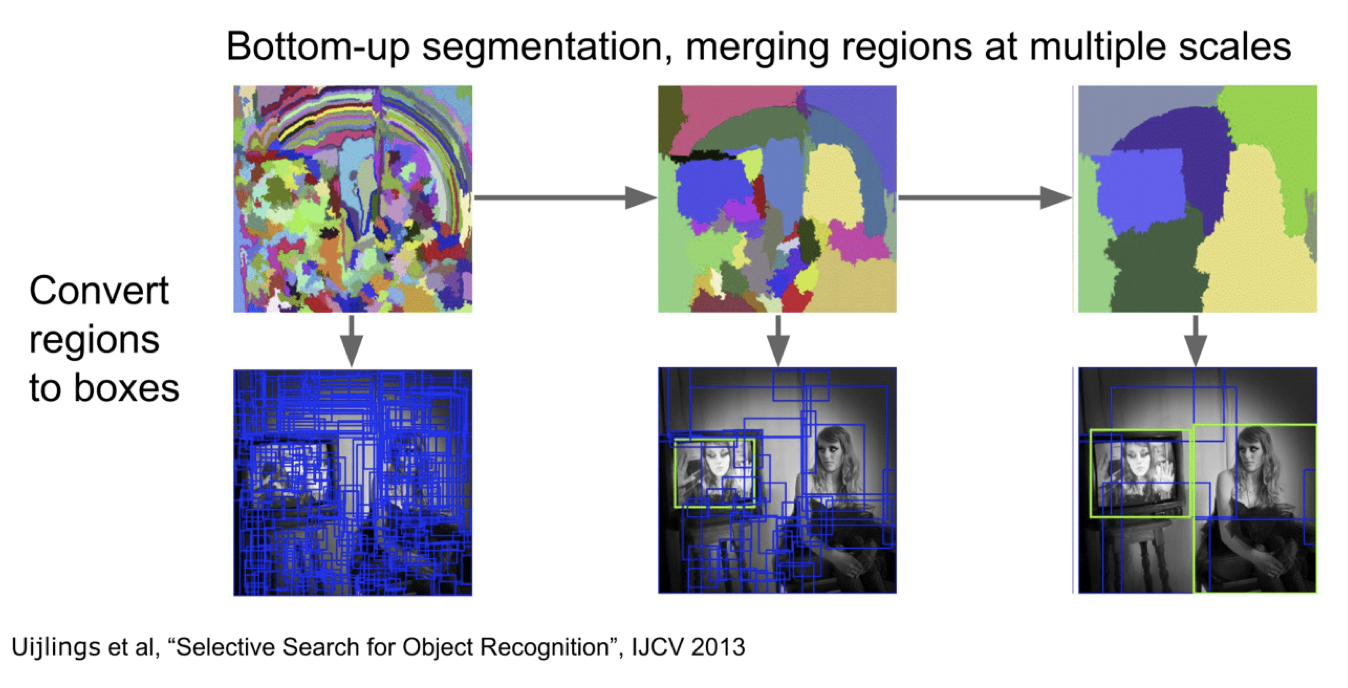
Selective Search
对于一张图片,我们可以按照颜色、纹理等特征划分成多个部分,将每一个部分作为一个备选框输入网络,可以极大地减少计算量。本部分我们不再详细介绍。
RCNN
RCNN就是用了这样的Region Proposal思想构建的。先使用selective search得到备选框,再按框将图片裁剪出来输入网络中,得到物体的图片特征,再通过SVM和线性回归得到分类以及框的偏移量,这样的好处是训练非常简单,我们只需要训练好一个模型作为判别器,判断框中的物体分类即可。
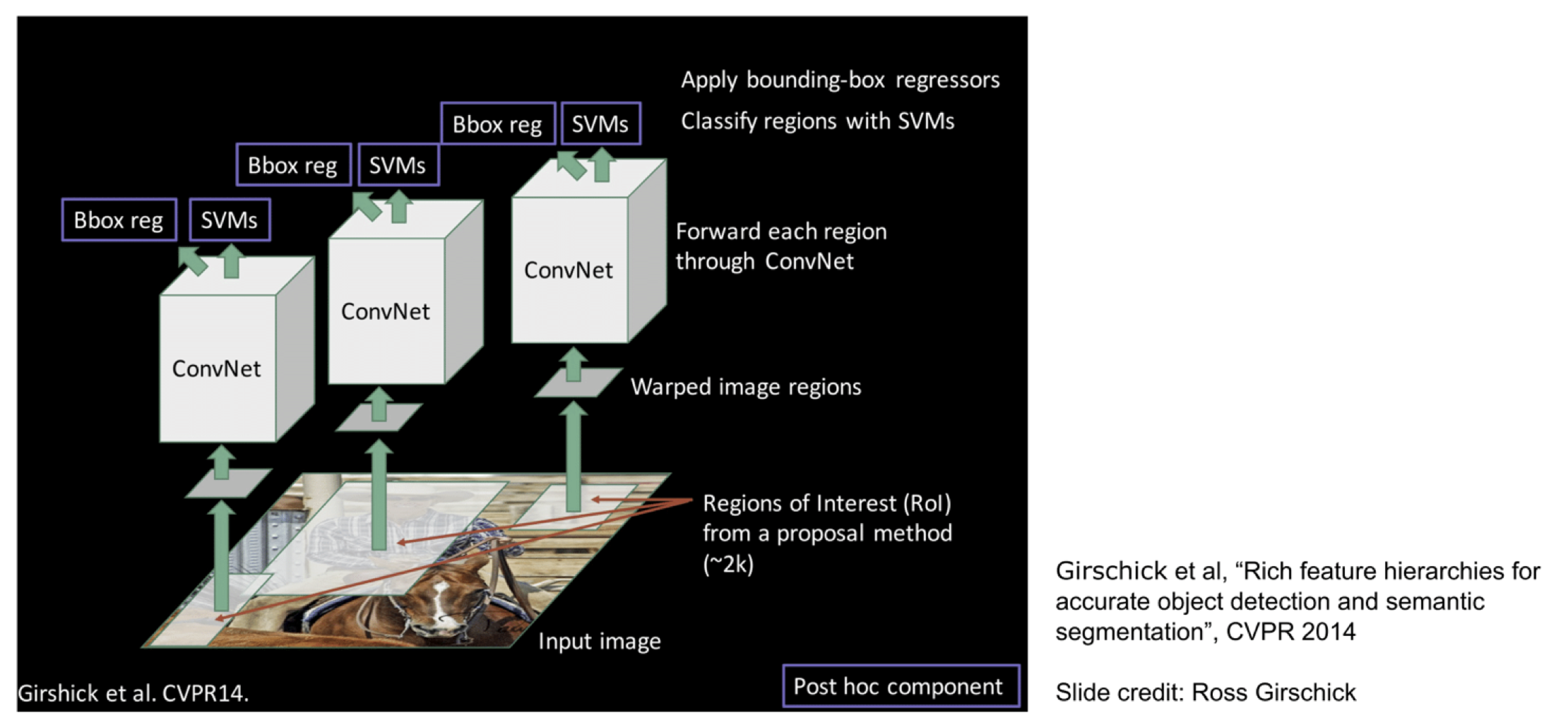
Fast RCNN
既然可以用CNN提取图片特征,为什么不直接写一个网络预测物体分类和坐标回归?于是有了Fast RCNN。
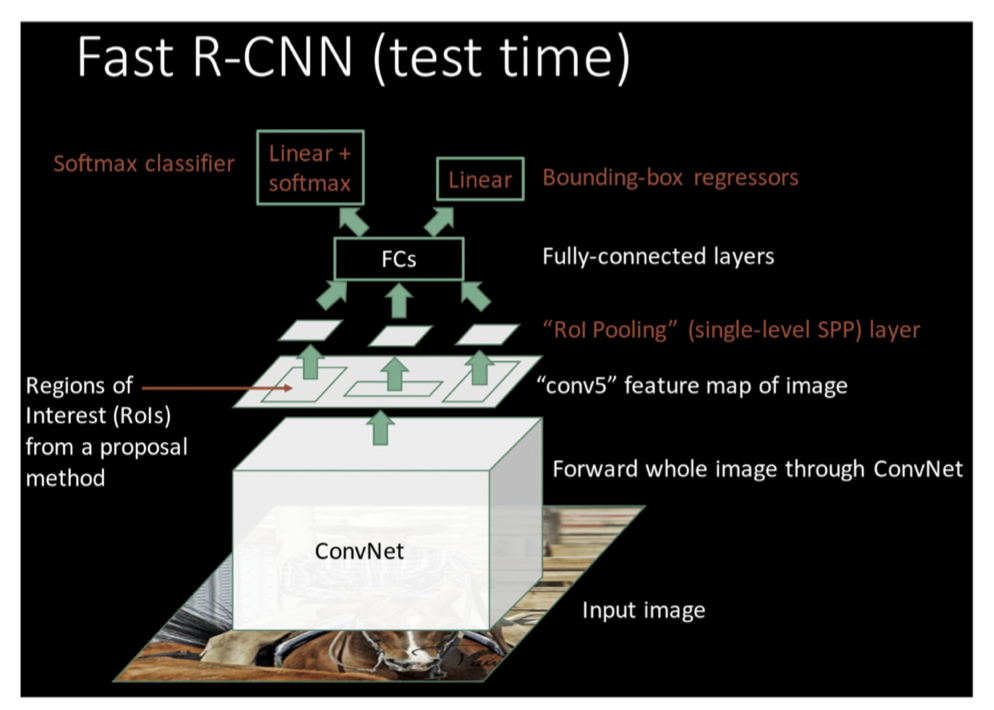
当然Fast RCNN也有一个问题,selective search算法耗时很长。可不可以用CNN来做region proposal?于是就有了Faster RCNN。
RCNN、Fast RCNN、Faster RCNN的区别
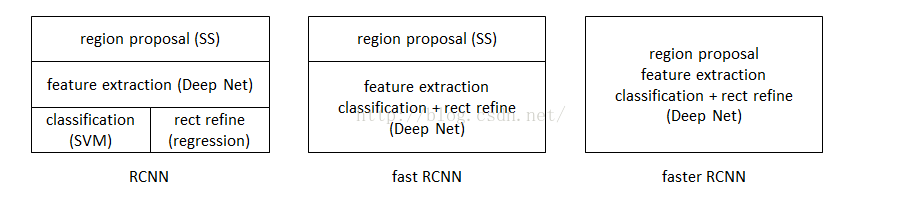
使用方法 缺点 改进 R-CNN(Region-based Convolutional Neural Networks) 1、SS提取RP;2、CNN提取特征;3、SVM分类;4、BB盒回归。 1、 训练步骤繁琐(微调网络+训练SVM+训练bbox);2、 训练、测试均速度慢;3、 训练占空间 1、 从DPM HSC的34.3%直接提升到了66%(mAP);2、 引入RP+CNN Fast R-CNN(Fast Region-based Convolutional Neural Networks) 1、SS提取RP;2、CNN提取特征;3、softmax分类;4、多任务损失函数边框回归。 1、 依旧用SS提取RP(耗时2-3s,特征提取耗时0.32s);2、 无法满足实时应用,没有真正实现端到端训练测试;3、 利用了GPU,但是区域建议方法是在CPU上实现的。 1、 由66.9%提升到70%;2、每张图像耗时约为3s。 Faster R-CNN(Fast Region-based Convolutional Neural Networks) 1、RPN提取RP;2、CNN提取特征;3、softmax分类;4、多任务损失函数边框回归。 1、 还是无法达到实时检测目标;2、 获取region proposal,再对每个proposal分类计算量还是比较大。 1、 提高了检测精度和速度;2、真正实现端到端的目标检测框架;3、生成建议框仅需约10ms。
Faster RCNN
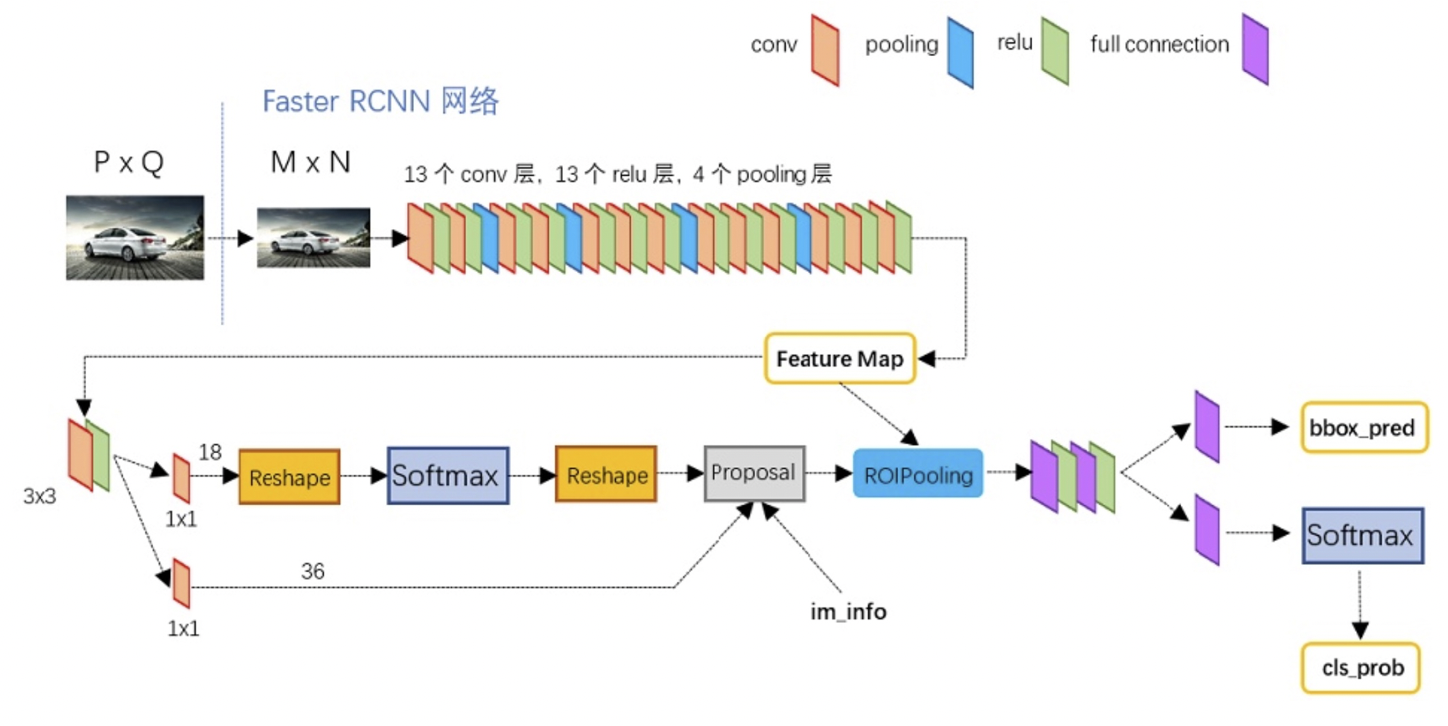
Faster RCNN总体流程
Conv Layers: 使用基础CNN网络提取图像的feature mapRegion Proposal Network: 使用RPN判断feature map的anchors是否为物体,同时修正box坐标Roi Pooling: 该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别Classification: 利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置
Region Proposal Networks
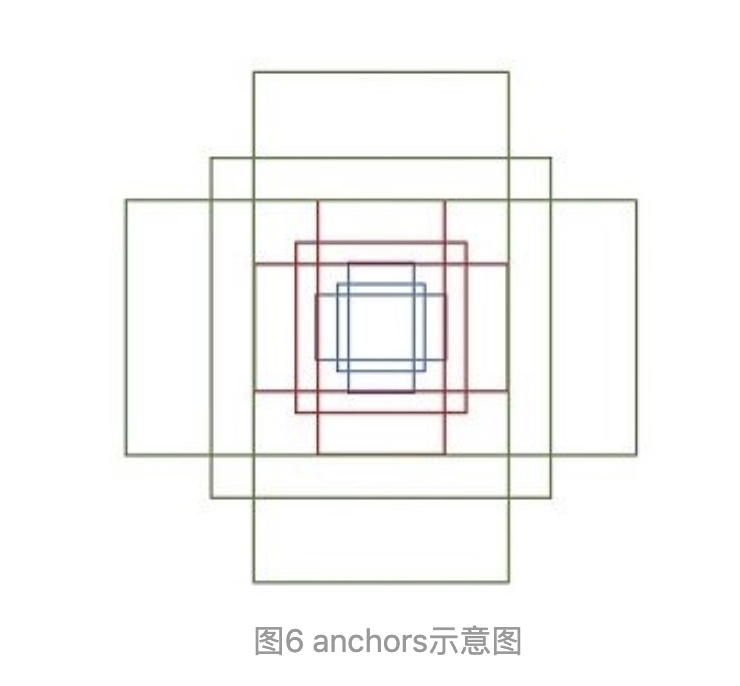
Faster RCNN将feature map的每一个点作为中心点,为其成k(默认k=9)个anchors,anchors按大小分为3组,每组框的长宽比为[2, 1, 0.5]。 个anchors,RPN会对每个anchors都输出对应的是否物体概率及框坐标,因此每个点都会有k * 2个scores输出、k * 4个坐标回归输出。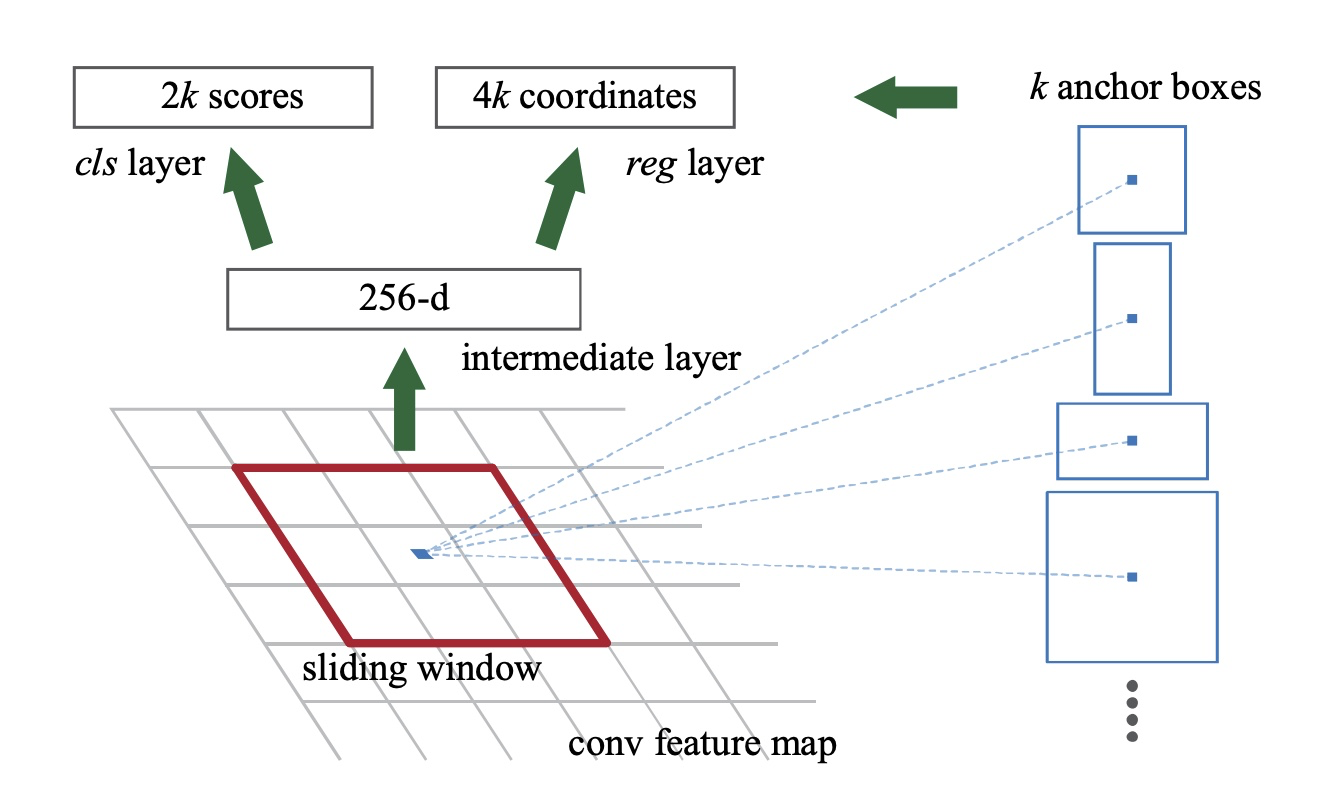
其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的foreground anchor,哪些是没目标的backgroud。所以,仅仅是个二分类而已!
那么anchor一共有多少个呢?
若原图为, 使用VGG网络下采样 倍,每个点的anchor数为9,那么总anchor数为: 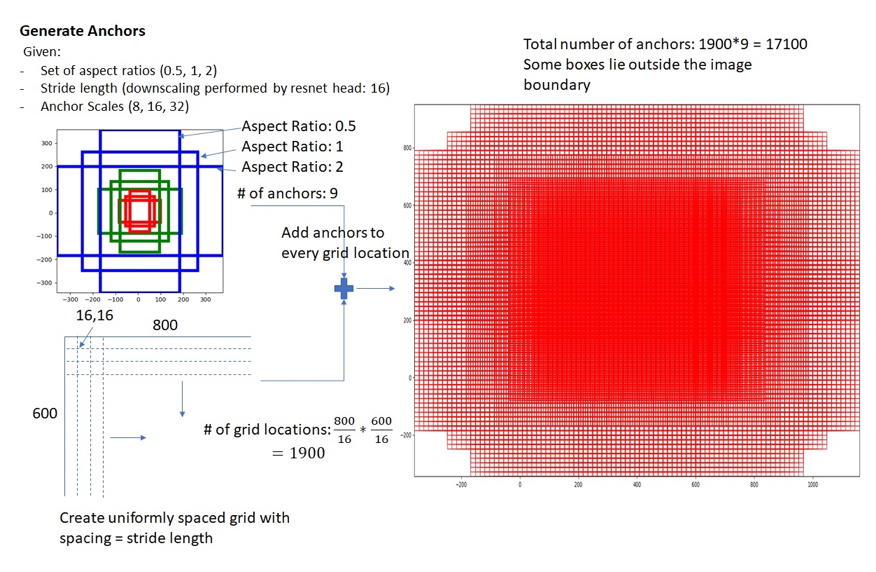
在得到所有anchors的概率及坐标后,可使用nms(Non-Maximum Suppression)操作将重合度较高的框合并为同一个、将概率较低的框舍弃。
NMS
介绍NMS算法前首先要了解衡量框重合度的IOU公式:
IOU(Intersection over Union)的全称为交并比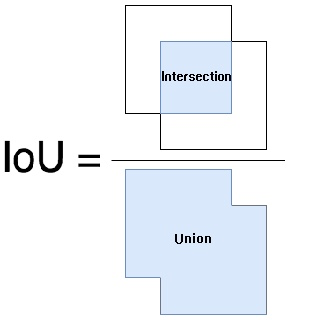
若框A的面积为SA,框B的面积为SB,两框重合面积为SI,则
非极大值抑制的主要操作步骤为:
- 对候选框按照分类概率进行筛选,概率低于某个阈值的视为非该物体直接剔除
- 对每一个分类的box进行排序,得到从大到小的box列表。如:A, B, C, D, E
- 从最大的框开始,分别与其后的框计算IOU,当两框IOU大于某个阈值时,将概率小的框舍弃。例如:A与C的IOU=0.9 > 阈值0.7,将C舍弃,剩余框为A, B, D, E
- 再按照顺序继续遍历,从B开始计算B与D、E的IOU
- 对每个分类均要执行一次上述过程
当然,使用nms方法会存在将重合的两个同类物体合并为一个的问题,也有soft nms等算法可以缓解此问题。
通过上述操作后,我们就可以得到可能为物体的备选框了
ROI Pooling
为什么需要ROI Pooling?
通常图像分类网络的输入大小都是固定的(例如224x224),那么要将一个长宽比为1:2的图片输入网络中,我们的两种做法是:裁剪、拉伸。
但这样会破坏图像原有的结构信息,因此Faster RCNN使用了ROI Pooling来处理不同长宽比的图片。其原理是,对输入矩阵的宽高维度使用不同大小的池化,例如160wx320h的图片,可以对w使用大小为10的池化,对h使用大小为20的池化,最终得到16x16的矩阵。
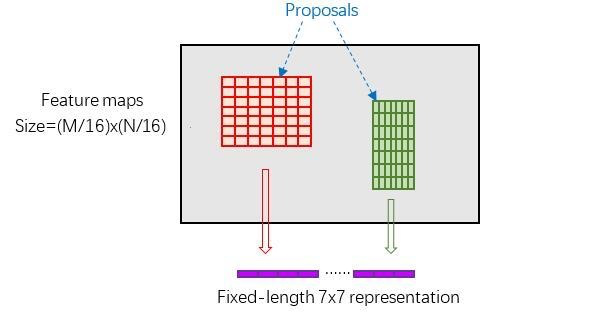
Classification
最后再将ROI Pooling得到的feature输入CNN网络中,得到其分类与最终坐标回归。
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
-
移动端实时人脸关键点识别综述0 - 概述发布在 AI方向
前言
移动端人脸关键点识别项目目前已经取得了不错的进展,大体的系统框架也已确定,从现在起我会陆续发表一系列的文章详细介绍移动端人脸关键点实现的技术,内容涵盖Object Detection、Face Landmark、移动端CNN模型、模型量化加速、神经网络边缘计算框架的对比与选择等,为目前网络上没有的对实时人脸关键点任务的综述,干货满满。
移动端实时人脸关键点识别需要解决的几大任务有:人脸定位 (Face Detection)、人脸关键点检测 (Face Landmark)、移动端网络计算,因此我们的文章也从这几个方面开始展开。
文章列表
Object Detection
- 移动端实时人脸关键点识别综述1.0 - Object Detection综述
- 移动端实时人脸关键点识别综述1.1 - Object Detection综述之Faster RCNN
- 移动端实时人脸关键点识别综述1.2 - Object Detection综述之YOLO
- 移动端实时人脸关键点识别综述1.3 - Object Detection综述之SSD
- 移动端实时人脸关键点识别综述1.4 - Object Detection综述之MTCNN
Face Landmark
- 移动端实时人脸关键点识别综述2.0 - Landmark综述
- 移动端实时人脸关键点识别综述2.1 - Landmark综述之数据处理
- 移动端实时人脸关键点识别综述2.2 - 移动端基础图像模型
- 移动端实时人脸关键点识别综述2.4 - Landmark综述之Loss
- 移动端实时人脸关键点识别综述2.3 - Landmark综述之网络的改进
Network Computation & Optimization
- 移动端实时人脸关键点识别综述3.0 - 神经网络边缘计算综述
- 移动端实时人脸关键点识别综述3.1 - 神经网络边缘计算框架的选择
- 移动端实时人脸关键点识别综述3.2 - 模型量化
- 移动端实时人脸关键点识别综述4 - Tips & Tricks
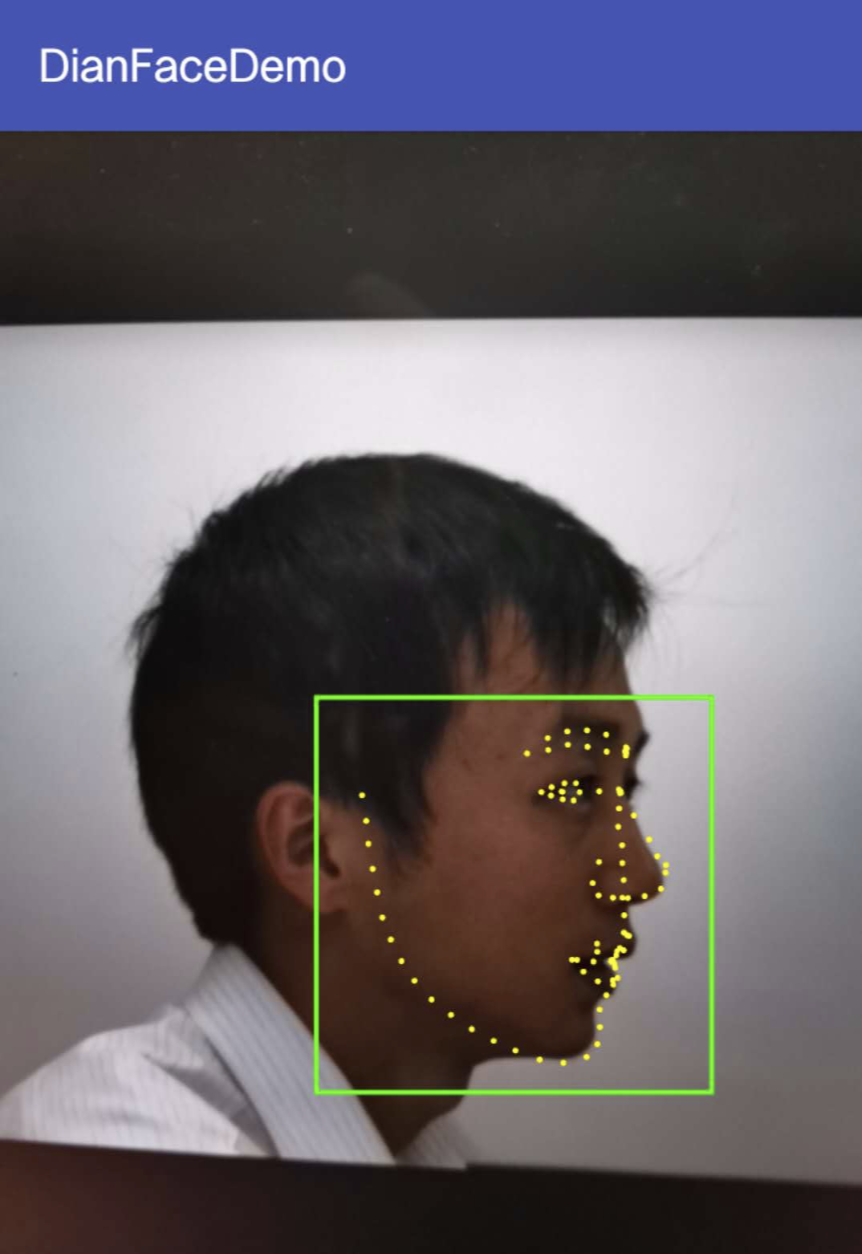
DianFace demo 1 DianFace demo 2