年度爆款BERT!
-
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》阅读笔记
BERT算是今年的一个爆款了,同一个模型,只微调就刷新了十一个记录,都有很大的提升...
它的出现为之后NLP的发展打下了很好的基础
下面来看论文中的做法Related works
论文中介绍了预训练的各种方法:
- Feature-based Approaches (ELMo)
- Fine-tuning Approaches (OpenAI GPT, BERT)
- Transfer Learning from Supervised Data
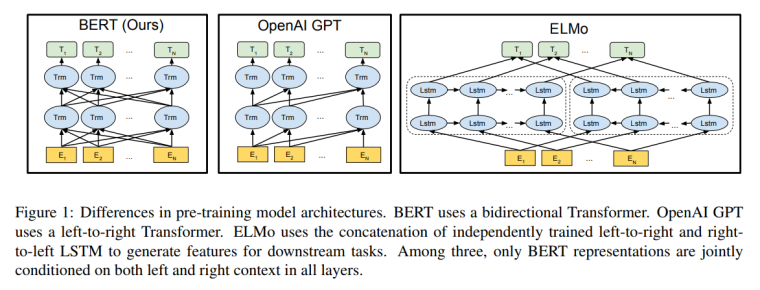
论文中介绍了BERT与其他各种预训练模型ELMo和OpenAI GPT的区别,ELMo使用了双向LSTM提取特征,属于feature-based方法。给downstream的任务生成features。OpenAI GPT只使用了left-to-right的Transformer,而token的right方向的信息是获取不到的。而BERT在所有层中都融合left-to-right和right-to-left的信息。
Input Representations
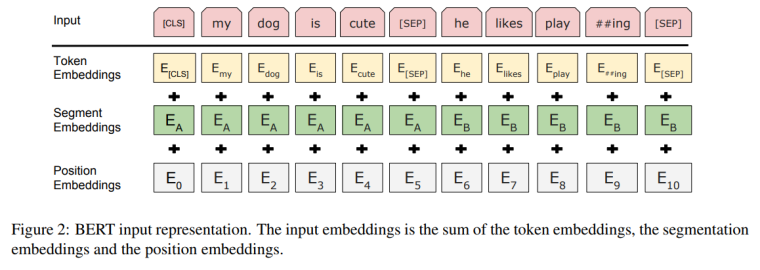
BERT简单粗暴的将句子拼接在一起(无论是单句还是句子对,连在一块就完事了),它的Input Representations 如图- Token embedding 用了WordPiece embedding,这个方法是用来解决oov的word的,就是把一些单词拆成两个词,比如playing就可以拆成play和##ing,拆的时候就用贪心去搜索最少的token来覆盖所有的单词
- Segment embedding 区分一下句子一和二
- Position embedding 融入了位置信息,是通过模型学到的
- The input embeddings is the sum of the token embeddings, the segmentation embeddings and the position embeddings. 没错,就这么粗暴
Core innovation Points
Task #1: Masked LM
作者认为用单向模型或者把两个单向模型拼接起来不如直接用双向的模型。但是传统方法只能是单向训练。BERT没有使用传统的left-to-right和right-to-left的language model,提出了一种Masked Language Model
随机屏蔽或替换一些单词,然后去预测这些单词,相当于完形填空...
- 80%的概率将单词换为[mask]标记 , my dog is hairy → my dog is [MASK]
- 10%的概率将单词换为字表中其他单词 , my dog is hairy → my dog is apple (可能是为了加噪声,防止过拟合)
- 10%的概率不替换 , my dog is hairy → my dog is hairy (这个我猜可能是为了让模型学到正常理解方式,而非完型填空的理解方式)
Task #2: Next Sentence Prediction
输入一个句子对,来预测第二个句子是不是第一个句子的下一句,学习句子之间的逻辑关系
Fine-tuning Procedure
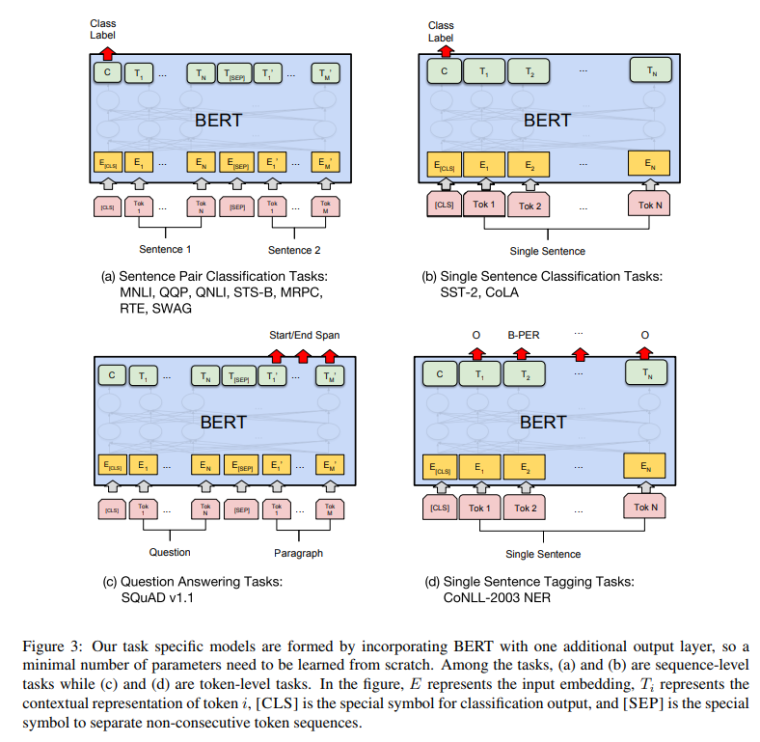
最后,一般自监督模型的泛化能力是比较强的,BERT从头到尾都是自监督
还有模型简直太大了,不是大公司根本训练不起...
不过用用预训练词向量还是可以的https://github.com/google-research/bert,目前支持英文,中文(很难受,只有字),其他的语言(不清楚有哪些)
应该是有史以来最好的TPU推广广告吧...