多月之后的GAN进阶
-
-
WGAN
WGAN作为GAN中的战斗机,对于稳定收敛、防止模式崩溃具有奇效。
WGAN相对于基础的GAN只有四点变化- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss发生变化
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD
loss的变化
原始的问题
原始的GAN会有什么问题呢?归结起来说,原始GAN的loss一般基于KL散度与JS散度
- JS散度 :
:
如果两个分布没有重叠,则JS散度为常数,训练学习梯度为0。男女朋友之间差异太大,如果没办法去寻找交集,不合适的相处就会让两方无法磨合,相处再久都没有改善。 - KL散度:
trick
然而KL散度不是一个对称的衡量。当出现“生成器没能生成真实的样本”错误时,惩罚微小,导致缺乏多样性;当“生成器生成了不真实的样本” 时,惩罚巨大,导致缺乏准确性。不对称的处理,生成器宁可多生成一些重复但是很“安全”的样本,也不愿意去生成多样性的样本,从而产生mode collapse。如果你找了一个喜怒无常的对象,不和他交流他对你抱怨几句,和他错误交流他要和你分手,时间久了,你就会下意识去避免交流,这样即使被抱怨了,也不会变成单身狗。
WGAN的loss
WGAN基于Wasserstein距离,即Earth-Mover(EM)距离。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
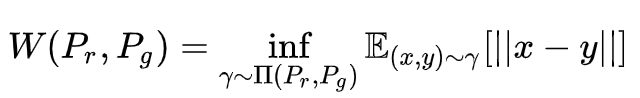
尝试的结果
经过尝试,在多视角数字上出现了多样性,初步认为GAN学到了数字的基本分布。下一步,就是尝试去控制一些特征,比如,视角。
-
更换数据集
在WGAN初步奏效后,楼主尝试着去通过增加Discriminator的功能,让其有意的分辨角度,从而达到训练生成器关注角度的作用。然而问题在于,对于3D数字0-9的多视角,很多数字存在迷惑性,比如6和9、2和5、1和7在多视角下会存在混淆。如果排开易于混淆的,可用的数据类别降低一半以上,训练起来没有前景,故决定开始更换数据集。
新数据集
新数据集选择的chair_dataset数据集,数据集中有999张椅子,每张椅子有2*31张不同角度的照片。
换了新数据集中,更改dataset文件读取数据,采用同样的WGAN去训练,模式崩溃现象严重,生成的图片完全相同,没有多样性,在此我们认为GAN并没有学到东西。
GAN的模式崩溃,是所有做GAN的新手非常容易遇到,也很难找到具体原因的问题。一点挣扎
我尝试在Discriminator中加入对pose的识别,结果还是崩溃,要想解决这个问题,大概还需要一点新论文的辅助。
-
Pix2Pix 大约是个救星?
论文地址 https://arxiv.org/pdf/1611.07004.pdf
看到论文中提到
Past conditional GANs have acknowledged this and provided Gaussian noise z as an input to the generator, in addition to x (e.g., [55]). In initial experiments, we did not find this strategy effective – the generator simply learned to ignore the noise......
我的心头顿时起了波澜,也许这次的mode collapse就与noise的被忽略有关,所以没有多样性。Pix2Pix的结构优秀之处
对于Generator,如果使用普通的卷积神经网络,那么会导致每一层都承载保存着所有的信息,这样神经网络很容易出错,因而,使用U-Net来进行减负。
在Pix2Pix中,值得注意的是U-Net也是Encoder-Decoder模型,其次,Encoder和Decoder是对称的。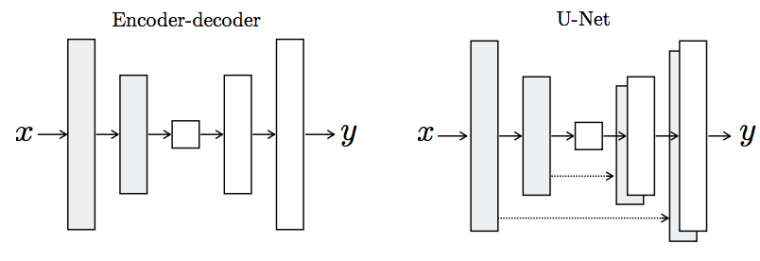
U-Net将第i层拼接到第n-i层,这样做是因为第i层和第n-i层的图像大小是一致的,可以认为他们承载着类似的信息。由此,noise的作用可以得到突出。也许就能缓解多样性问题。
尝试的结果
由于并没有直接搬Pix2Pix,只是借用Generator优秀的结构来改造原有网络,因此花了一点时间去设计每一层的结果。在设计的过程中,感受到了数学之美和对称的快乐,然后跑起来,发现有了轻微的多样性。即使是非常微小的角度差异,依旧能感觉到和之前的完全一样有一些进步,说明GAN有学到一些分布,感受得到轻微的差异。
然而,一切都还没完,还需要更好。
-
Cycle-Consistent GAN再来一把
Cycle GAN的优秀之处本身在于:相对于Pix2Pix方法提供在两个域中有相同数据的训练样本,CycleGAN能够在源域和目标域之间,无须建立训练数据间一对一的映射,就可实现这种迁移。先膜一把大神之作。论文地址http://openaccess.thecvf.com/content_ICCV_2017/papers/Zhu_Unpaired_Image-To-Image_Translation_ICCV_2017_paper.pdf
网络结构如下
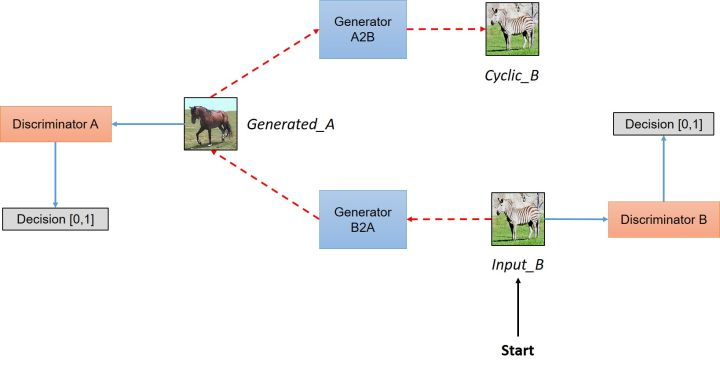
有兴趣的可以去拜读一下,然而我在此依旧是只借用了其一部分的精髓,用于解决多样性缺失的问题。
cycle loss
作者试图通过生成器将输入图像(inputA)从域DA映射到目标域DB中,转换成对应图像。但是为了确保这些图像之间存在有意义的关系,它们必须共享一些特征,这些特征可用于将此输出图像映射回输入图像,因此必须有另一个生成器能将此输出图像映射回原始域。
即我们希望这个输出图像必须与原始输入图像相似,用来定义非配对数据集中原来不存在的有意义映射。尝试结果
借用为了让输出图像必须与原始输入图像相似的目标思想,我构建了cycle loss,将生成的图片映射回原图,构建L1 loss,衡量生成图与原图的相似性。
结果多样性增多,角度多样性明显一些,每个图多少会有所不同,但是不足的是,多样性很多体现在深浅上,而不是我们希望的纯角度上,这个问题需要去分析解决。
-
新问题的定位
猜测问题
按照最初的目标,对于每个生成任务,给定的不同的目标为角度和样式。基准图片决定了样式的不同,通过控制noise来关注角度目标的不同。然而最后生成的图出现深浅的多样性,经猜测很有可能就是noise的选取或者使用有问题。
验证猜测
我采用PyTorch进行研究,方便打印中间的值。在val的过程中,打印noise,惊奇的发现,大家竟然长得差不多。
在最朴素的GAN中,Generator的noise考虑用高斯噪声,比如均值为0,方差为1的噪声。但是现在的noise差值仅仅只有0.1左右,因此不能较好的反应差别。努力的方向
去寻找一个性质良好的noise,以及适合的加入方式。
什么称为性质良好呢?
即与角度差异有正确的映射,noise的值标准化,每个noise具有一致的均值方差。
在表象上看,需要满足,对于角度差别较大的基准图,noise的值要小,对于角度差异小的基准图,noise的值大。
而且nosie不适宜一张noise一个值,否则容易让GAN误以为输入角度的不同实际上反映在图片的深浅上。
-
有没有神奇的noise生成方式呢?
还在用高斯噪声吗?
还在苦苦想办法去尝试编码特征标签吗?
也许noise也可以增强对抗训练了。如今的尝试方向
论文链接 https://www.ijcai.org/proceedings/2017/0404.pdf
尝试去对角度特征进行对抗训练,得到能反映角度特征的noise。
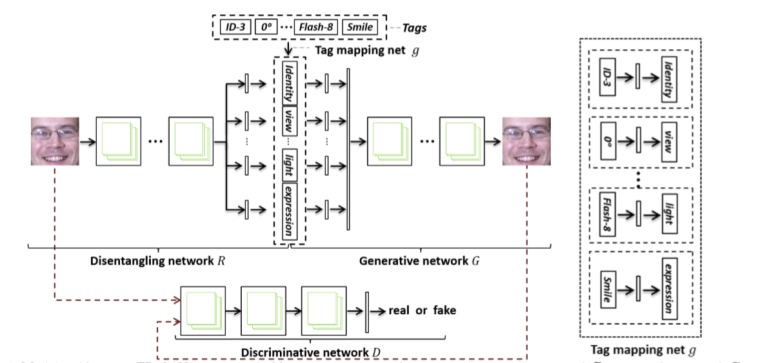
尝试ing