移动端实时人脸关键点识别综述2.1 - Object Detection综述之Faster RCNN
-
References
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- Fast Optimization Methods for L1 Regularization
- 一文读懂Faster RCNN
- DianAI培训3 - CNN for Object Detection
RCNN的发展
在说Faster RCNN之前,我们先简单介绍一下RCNN、FastRCNN。RCNN算法是由RCNN->Fast RCNN->Faster RCNN逐步发展来的,且效果和速度为递增关系,因此可以直接学习Faster RCNN,它的前辈已经淘汰了。
CNN作为特征提取器,对图片特征有很好提取效果,因此有了使用CNN进行物体检测的想法,我们可以采用滑动窗口的方法,将图片resize成不同大小,使用同一卷积网络对图片进行卷积,得到很多个窗口的分类概率及坐标回归,但这样的网络计算量显然太大了,如果我要识别的物体非常小,就需要把图片resize成很大,让卷积网络滑过无数个窗口。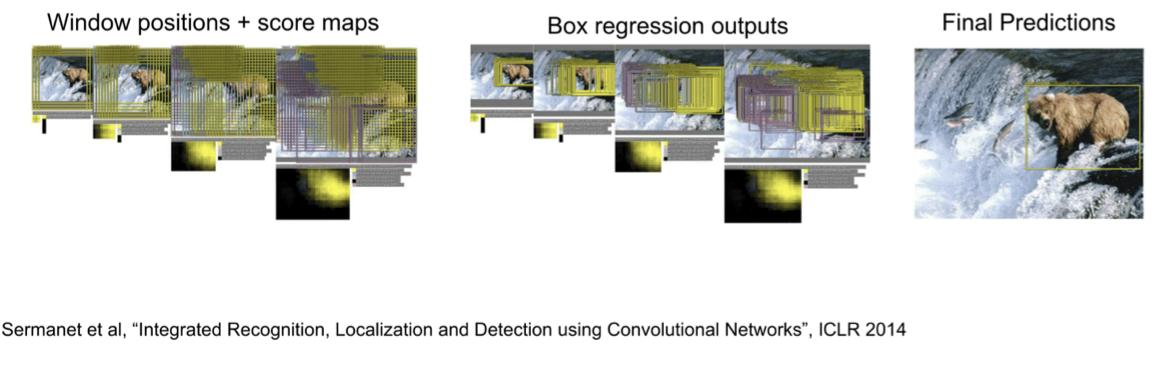
上面的滑动窗口的方法很粗暴,绝大多数窗口都是没有物体的,这样对计算造成了很大的浪费,我们是否能在将图片输入网络之前先确定一些有可能是物体的框?当然可以。
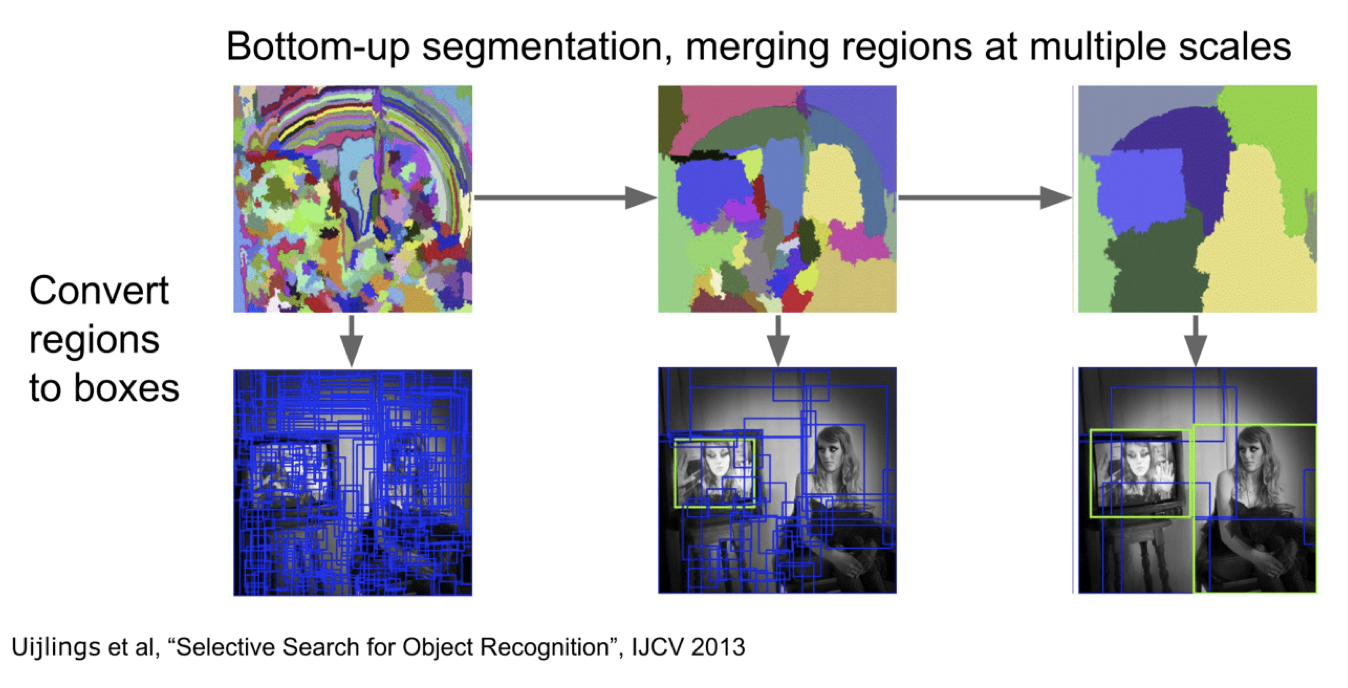
Selective Search
对于一张图片,我们可以按照颜色、纹理等特征划分成多个部分,将每一个部分作为一个备选框输入网络,可以极大地减少计算量。本部分我们不再详细介绍。
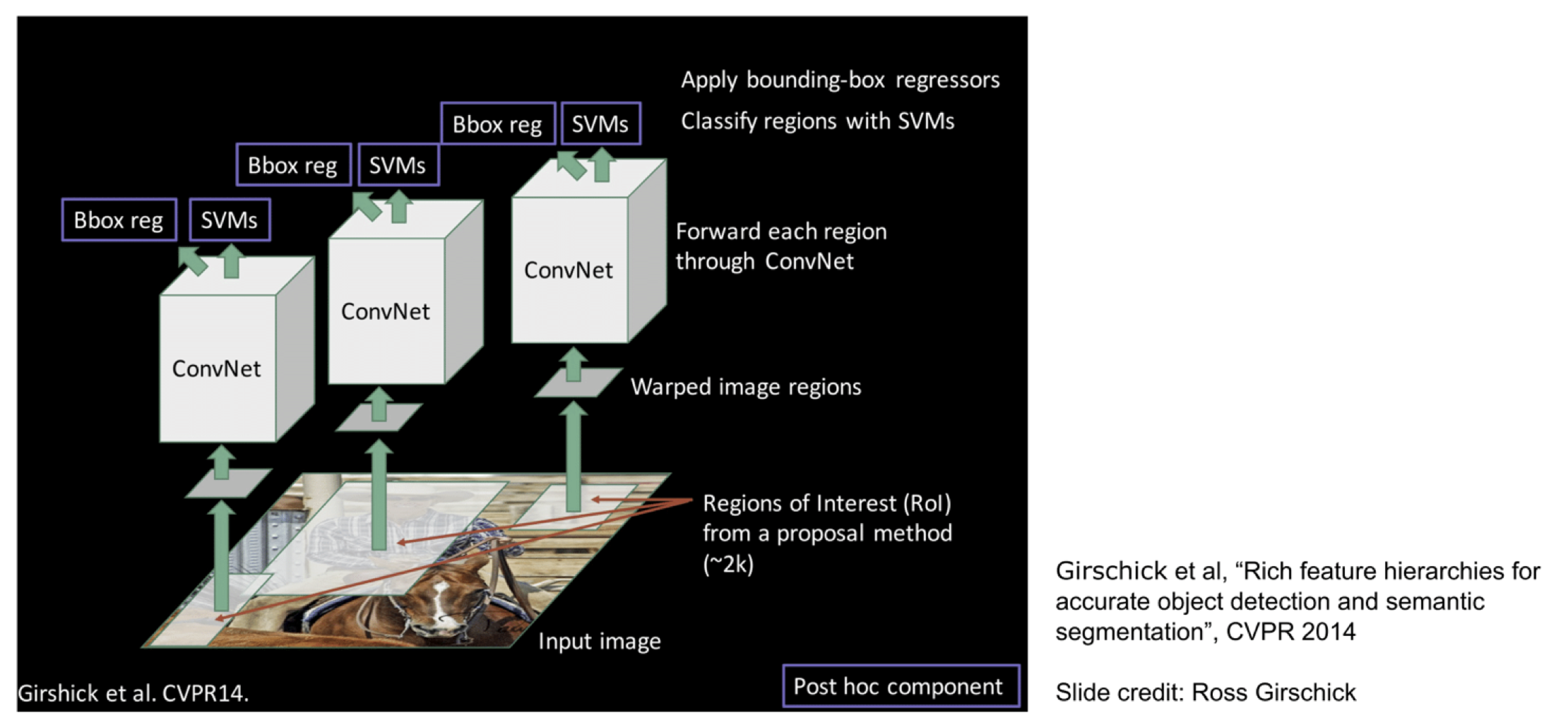
RCNN
RCNN就是用了这样的Region Proposal思想构建的。先使用selective search得到备选框,再按框将图片裁剪出来输入网络中,得到物体的图片特征,再通过SVM和线性回归得到分类以及框的偏移量,这样的好处是训练非常简单,我们只需要训练好一个模型作为判别器,判断框中的物体分类即可。
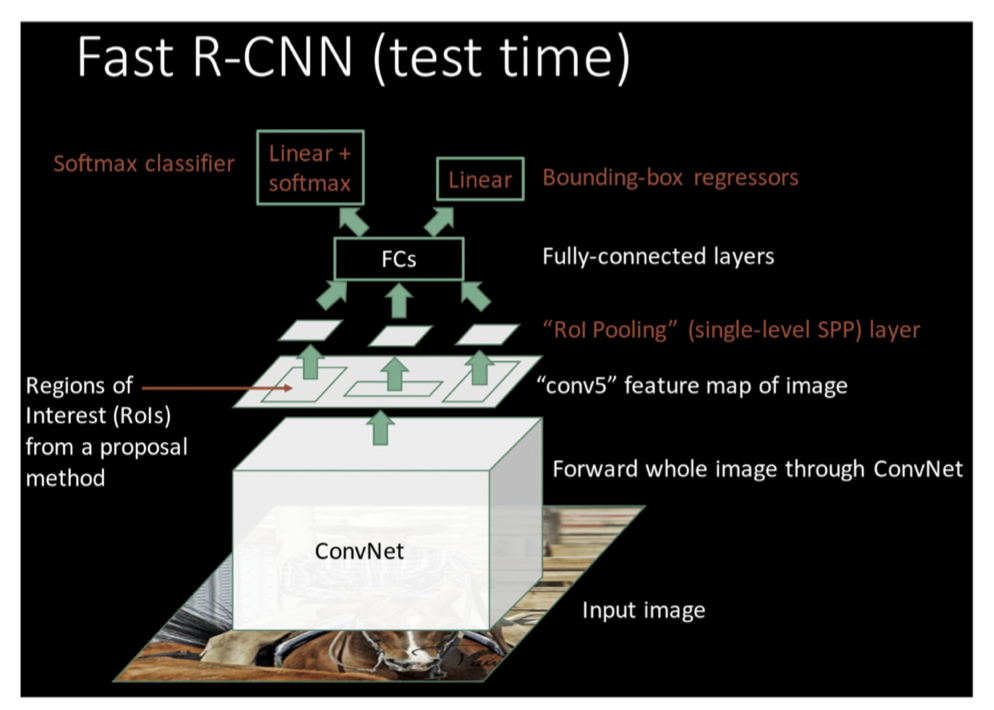
Fast RCNN
既然可以用CNN提取图片特征,为什么不直接写一个网络预测物体分类和坐标回归?于是有了Fast RCNN。
当然Fast RCNN也有一个问题,selective search算法耗时很长。可不可以用CNN来做region proposal?于是就有了Faster RCNN。
RCNN、Fast RCNN、Faster RCNN的区别
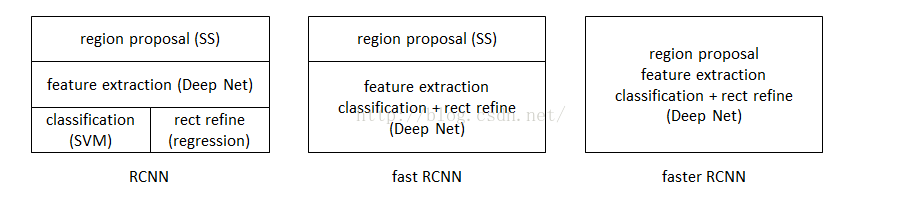
使用方法 缺点 改进 R-CNN(Region-based Convolutional Neural Networks) 1、SS提取RP;2、CNN提取特征;3、SVM分类;4、BB盒回归。 1、 训练步骤繁琐(微调网络+训练SVM+训练bbox);2、 训练、测试均速度慢;3、 训练占空间 1、 从DPM HSC的34.3%直接提升到了66%(mAP);2、 引入RP+CNN Fast R-CNN(Fast Region-based Convolutional Neural Networks) 1、SS提取RP;2、CNN提取特征;3、softmax分类;4、多任务损失函数边框回归。 1、 依旧用SS提取RP(耗时2-3s,特征提取耗时0.32s);2、 无法满足实时应用,没有真正实现端到端训练测试;3、 利用了GPU,但是区域建议方法是在CPU上实现的。 1、 由66.9%提升到70%;2、每张图像耗时约为3s。 Faster R-CNN(Fast Region-based Convolutional Neural Networks) 1、RPN提取RP;2、CNN提取特征;3、softmax分类;4、多任务损失函数边框回归。 1、 还是无法达到实时检测目标;2、 获取region proposal,再对每个proposal分类计算量还是比较大。 1、 提高了检测精度和速度;2、真正实现端到端的目标检测框架;3、生成建议框仅需约10ms。
Faster RCNN
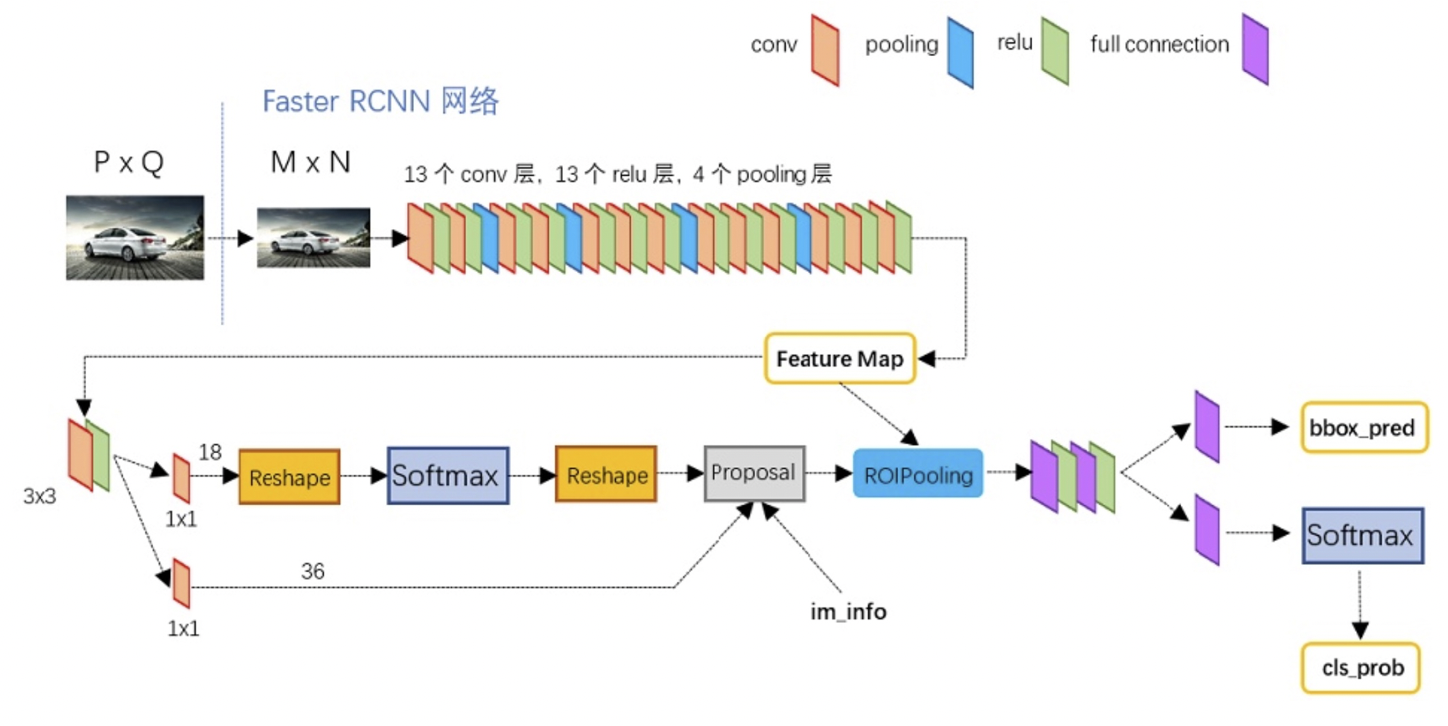
Faster RCNN总体流程
Conv Layers: 使用基础CNN网络提取图像的feature mapRegion Proposal Network: 使用RPN判断feature map的anchors是否为物体,同时修正box坐标Roi Pooling: 该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别Classification: 利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置
Region Proposal Networks
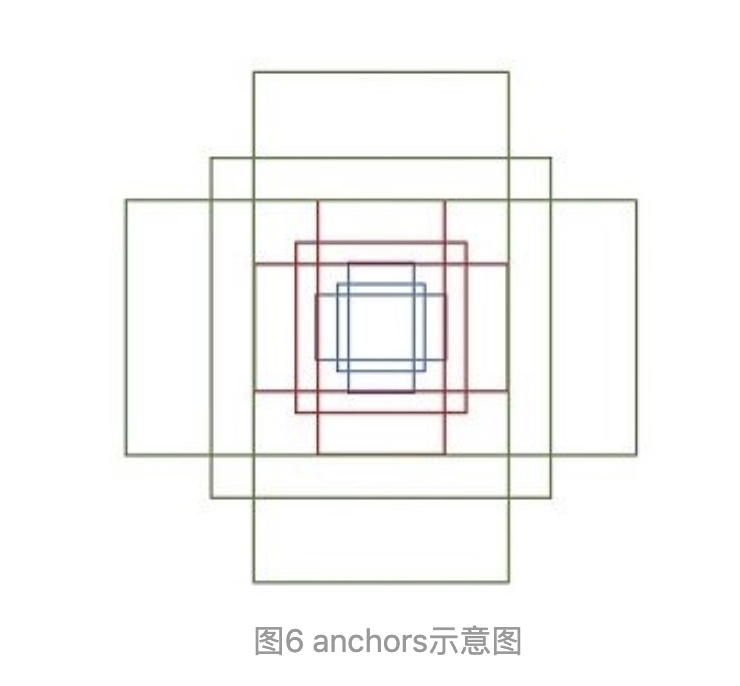
Faster RCNN将feature map的每一个点作为中心点,为其成k(默认k=9)个anchors,anchors按大小分为3组,每组框的长宽比为[2, 1, 0.5]。 个anchors,RPN会对每个anchors都输出对应的是否物体概率及框坐标,因此每个点都会有k * 2个scores输出、k * 4个坐标回归输出。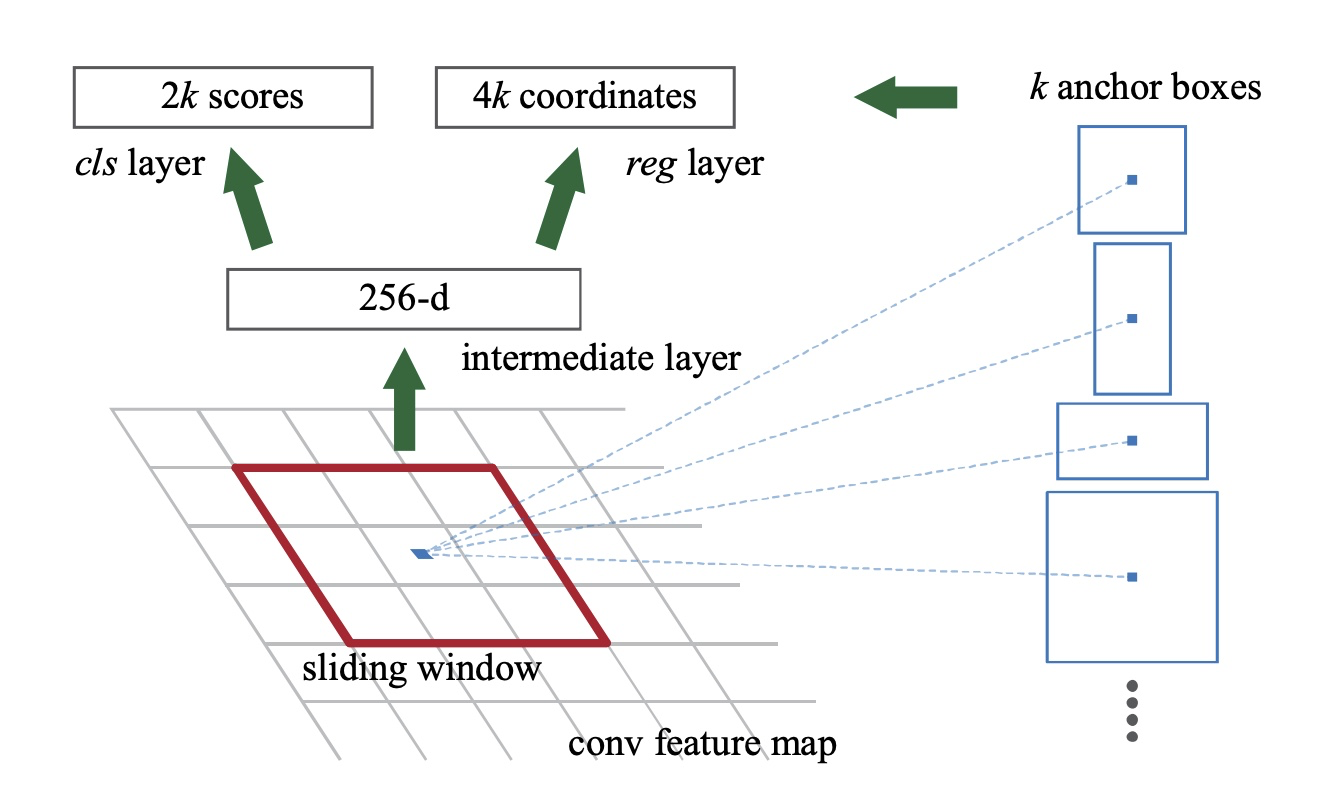
其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的foreground anchor,哪些是没目标的backgroud。所以,仅仅是个二分类而已!
那么anchor一共有多少个呢?
若原图为, 使用VGG网络下采样 倍,每个点的anchor数为9,那么总anchor数为: 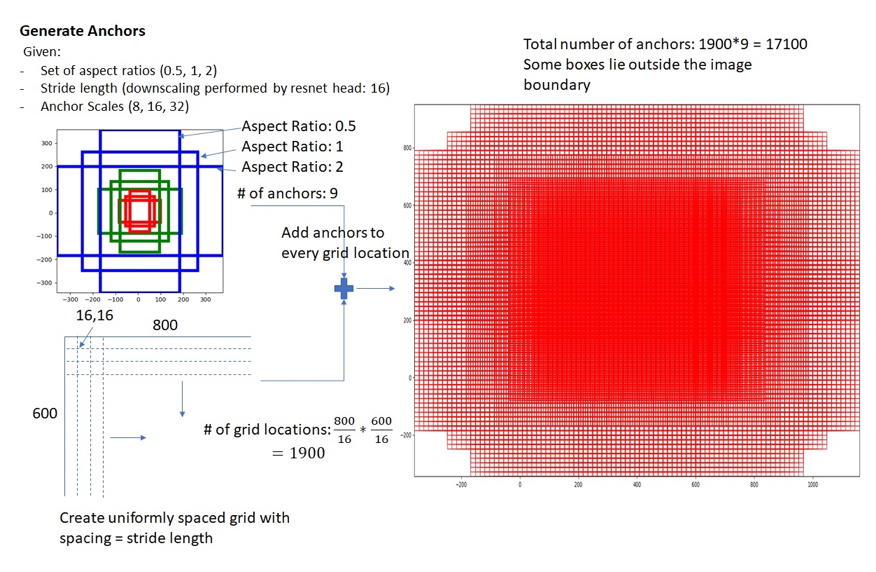
在得到所有anchors的概率及坐标后,可使用nms(Non-Maximum Suppression)操作将重合度较高的框合并为同一个、将概率较低的框舍弃。
NMS
介绍NMS算法前首先要了解衡量框重合度的IOU公式:
IOU(Intersection over Union)的全称为交并比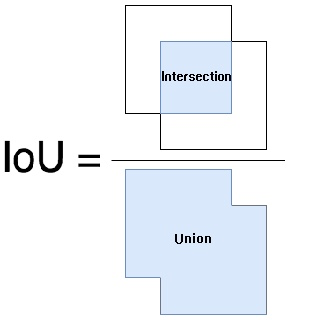
若框A的面积为SA,框B的面积为SB,两框重合面积为SI,则
非极大值抑制的主要操作步骤为:
- 对候选框按照分类概率进行筛选,概率低于某个阈值的视为非该物体直接剔除
- 对每一个分类的box进行排序,得到从大到小的box列表。如:A, B, C, D, E
- 从最大的框开始,分别与其后的框计算IOU,当两框IOU大于某个阈值时,将概率小的框舍弃。例如:A与C的IOU=0.9 > 阈值0.7,将C舍弃,剩余框为A, B, D, E
- 再按照顺序继续遍历,从B开始计算B与D、E的IOU
- 对每个分类均要执行一次上述过程
当然,使用nms方法会存在将重合的两个同类物体合并为一个的问题,也有soft nms等算法可以缓解此问题。
通过上述操作后,我们就可以得到可能为物体的备选框了
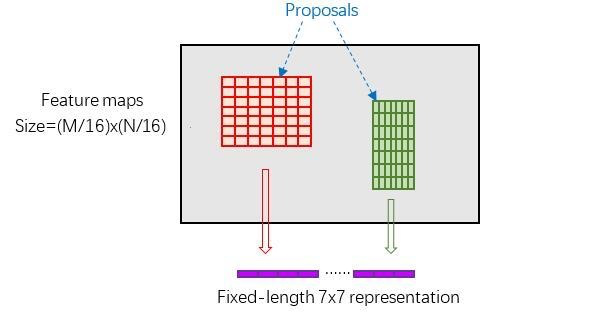
ROI Pooling
为什么需要ROI Pooling?
通常图像分类网络的输入大小都是固定的(例如224x224),那么要将一个长宽比为1:2的图片输入网络中,我们的两种做法是:裁剪、拉伸。
但这样会破坏图像原有的结构信息,因此Faster RCNN使用了ROI Pooling来处理不同长宽比的图片。其原理是,对输入矩阵的宽高维度使用不同大小的池化,例如160wx320h的图片,可以对w使用大小为10的池化,对h使用大小为20的池化,最终得到16x16的矩阵。
Classification
最后再将ROI Pooling得到的feature输入CNN网络中,得到其分类与最终坐标回归。
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks