Hidden Markov Model (上)
-
什么是马尔可夫链
马尔可夫链是满足马尔可夫性质的随机过程,描述了一个状态序列,每个状态序列取决于前面的有限种状态,包含状态空间,状态转移矩阵,初始状态概率向量。下面例子来自知乎:
假设一同学,每天中午12点有三种状态,状态转移矩阵,初始时的状态概率:
状态:[吃,玩,睡] 状态转移矩阵:[0.2,0.3,0.5 0.1,0.6,0.3 0.4,0.5,0.1] 初始时刻状态概率:[0.6,0.2,0.2]注意这里的状态转移矩阵每一行的概率和为1,先要预测接下来第n天的时候他的状态,使用矩阵相乘即可。
此处的状态转移的链式过程就叫做马尔可夫链HMM(隐马尔可夫模型 Hidden Markov Model)
可以参看此笔记
- 隐马尔可夫模型五要素:初始状态向量、状态转移矩阵、观测概率矩阵、状态集合、观测序列
- HMM当中的Hidden体现在哪? Hidden隐藏到是变量,称为隐藏变量,有很多数据我们无法直接得到,与之相对到是观测变量,也就是直接观测到的数据。一个例子:我现在需要识别音频文件当中的文字,音频则为观测值,文字则为隐藏变量,也就是我们需要的预测的部分。
- 下面是一个看病的例子:
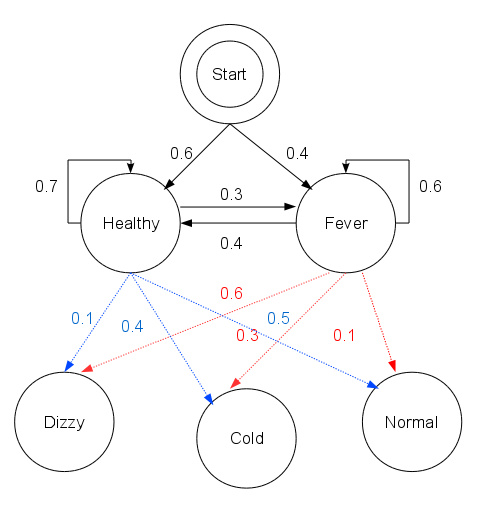
其中Healthy/Fever为要预测的状态空间,Dizzy/Cold/Normal为观测序列
HMM所要讨论的问题
- 概率问题:给定模型和观测序列,计算在模型下,观测序列出现的概率
- 学习问题:为了使上面的概率最大, 使用极大似然估计,确定参数
- 预测问题:对于给定的观测序列,计算概率最大的状态序列
前向算法
在MLAPP一书当中,将这个算法分为两个部分
- Prediction Step
- Update Step
首先要弄清楚几个问题:
- 这个算法的输入是什么?
- 这个算法的输出是什么?
- 什么是前向概率?
- 算法当中如何确保总概率为1?
在MLAPP当中给出了算法的伪码:
Input:Transition matrices(转移矩阵),local evidence vectors(观测概率矩阵),initial state distribution(初始概率向量)1 Input: Transition matrices ψ(i, j) = p(zt = j|zt−1 = i), local evidence vectors ψt(j) = p(xt|zt = j), initial state distribution π(j) = p(z1 = j); 2 [α1,Z1]=normalize(ψ1⊙π); 3 fort=2:Tdo 4 [αt, Zt] = normalize(ψt ⊙ (ΨT αt−1)) ; 5 Return α1:T and log p(y1:T ) = log Zt; t 6 Subroutine: [v,Z] = normalize(u) : Z = uj; vj = uj/Z;这里使用log取对数是为了防止数字下溢
后向算法
后向算法也就是前向算法的逆推
这里有一个问题是我们在进行后向算法时候的初值概率设置为了1,这是为什么?这里有一个前向算法和后向算法的盒子取球例子,
前向概率和后向概率的关系
第t时刻有第i个状态的概率 = t时刻的前向概率 * t时刻的后向概率