细胞分类实验中遇到的问题
-
[目录页]
我在细胞分类实验中遇到的问题大致有以下几条,特此记录在案。- normalize参数设置
- 训练集、验证集、测试集数据增强
- transform设置
同时也有一些未解决的疑难杂症记录如下:
- 不同批次数据差别较大,在新批次上准确率很低
-
[normalize参数设置]
背景
normalize,学长说这是解决数据背景不一致的有效处理方法。
具体而言,假如说我们有两批数据的背景不同,但是数据特征相似,那我们经过normalize处理就可以将数据特征“位移”到同样的位置,网络学习效果就会好。对于normalize的误区
网上很多关于normalize的博客都会给出类似于这样的描述
transforms.Normalize(mean = (0.5, 0.5, 0.5), std = (0.5, 0.5, 0.5))他们的理由是将数据归一化到[-1,1]之间,这是因为在normalize之前会进行totensor操作,这回将数据变为[0,1]分布,然后经过减去均值mean,除以标准差的操作后就会归一化到[-1,1]之间。
[-1,1]之间的好处在于如果假设输入为一个均值0,方差为定值的输入在很多情况下会对网络有比较好的性质。比如说如果你的loss函数用的是sigmoid+bce,其实你的假设就是,在训练的刚开始,sigmoid输入的值满足一个(0,x)的正态分布/其他分布,训练初期sigmoid的输出的期望就是0.5,而不是一个有偏见的值(来自yss)
但是经过我的分析,我觉得这并不是一个好的做法,因为这样处理后数据就不会以0为中心了,经过我的训练,我发现效果并不如计算数据集的meanstd后normalize好。
因此最好的方法是,将所有数据进行汇总,计算整个数据集的meanstd,然后再normalize设置此meanstd。
-
[训练集、验证集、测试集数据增强]
背景
网上大部分数据增强都是建议只对训练集操作,验证集和测试集都不操作。但是!
我很好奇,如果在训练集里面加入centercrop操作,但是在验证集和测试集都不加,那效果肯定不好。那怎么理解数据增强呢?对于数据增强的误区
事实上我刚才所述的centercrop应该对于所有数据都进行处理,而且这不能理解为数据增强,而是理解为数据预处理。
除此以外,normalize、totensor、resize等操作都应该被视作数据预处理。
数据增强主要指的是随机增强或者颜色增强等。
比如随机裁剪(randomcrop)、随机缩放(randomresize)、随机翻转(randomhorizontal)。这些增强手段只能用在训练集上,不能用在验证集和测试集上。
-
[transform设置]
背景
我发现在训练集加入randomcrop之后,保存下来的模型在验证集达不到原有效果了。
比如本身模型val_acc为95%,但是我重新用脚本测试的时候发现效果只有80%+,具体原因未知。
-
[不同批次数据差别较大]
背景
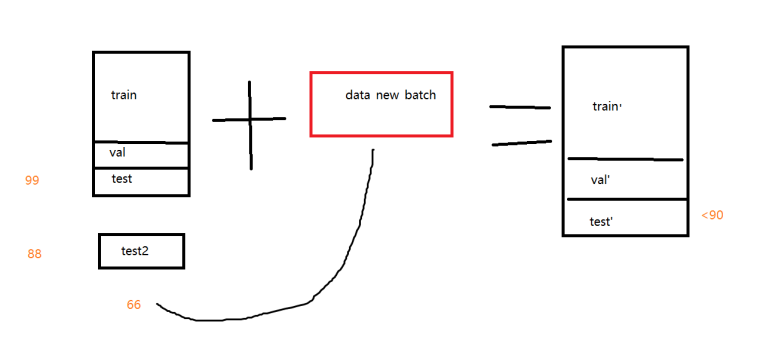
我在一个批次里面将数据集分为训练集、验证集和测试集,其中测试集能够达到99,但是用另一个数据集当做测试集,就只有88(所有badcase全部是真的badcase)
更恐怖的是我将最新批次数据拿来进行测试,发现效果只有66,把最新数据和原数据合并后,即使新测试集上准确度都达不到90。问题定义
这个问题主要是不同批次数据的背景不相同

另一个批次

总而言之,背景不同导致模型泛化能力不足。
接下来我的打算是用GAN生成数据补充现有数据,以及对背景进行处理。
除此以外,CAM画图可视化以及绘图看不同批次数据集准确度的变化曲线。
-
@zyh GAN生成数据用来数据扩充挺有意思的,你有什么具体的idea吗?
-
之前我一个同学做大创的时候也做过用VAE(变分自编码器)生成新数据的尝试,所以我觉得用GAN的原理是相同的。采用GAN进行数据扩充的主要目的是消除背景对于数据集的影响。暂时还没有尝试,我觉得应该生成5-10倍的新数据,然后与原数据一起训练。请问学长有什么建议吗?