Neo4j与Cypher语言学习笔记(一)
-
Neo4j与Cypher语言学习笔记(一)
前言
因为一些特殊原因偶然接触到一个叫做
citespace的关系可视化软件,citespace大致的应用情景是从特定的 引文关系数据库(web of science等)中,获得论文研究方向的关系图,但是效果并不美观,不同标签之间的连线显得有些杂乱,效果并不是很理想。之后被朱良辉安利了Neo4j——一个图形化数据库平台,出于兴趣就开始学习图形化数据库以及对应的查询语言Cypher。关于Neo4j和Cypher语言的相关介绍,有一本官方的英文书籍,但是讲解的非常浅显易懂,在Neo4j的官网上能找到下载地址。该篇是基于这本《O'reillyGraphDatabases》来写的,但是由于在此之前没有学习过传统数据库的相关知识,所以我个人的理解可能会存在偏差,如果表述中有不合理或者错误的地方,欢迎在评论区中指出。什么是图形化数据库
首先从传统的数据库说起,传统数据库是基于表格的形式构建的,打个比方——学生的学籍管理系统,我们可以通过sql非常方便地录入或是查询学生的学籍信息,包括学号姓名联系方式等,就像填表然后查表一样;但是如果我们想录入学生之间的社交关系呢,这个时候传统数据库可能会 额外 用一个2*n的表格,前一列记录学生,后一列罗列与前一列的同学是朋友的同学。那么每个人在这个数据表格中可能就会占用好几行,并且“朋友”是一个非对称关系(我拿你当朋友你却拿我当**?),这样就有必要对所有同学的朋友关系进行罗列,数据量就比较大了。然后,当我们要查询“Ryougi同学的朋友有谁”时,只需要遍历“朋友关系”数据库中Ryougi同学相关的那一部分数据项;但是如果我们要查询“谁是Ryougi同学的朋友”时,我们就必须遍历整个数据库了,而要是关系再加深一层,查询“朋友的朋友”的话,查询的时间消耗就更大了。
因为传统数据库在数据关系性查询方面的局限性以及图论的发展,开始有了基于图的数据库。其基本组成也像图一样,包含节点和边,其中节点包含各种数据属性,边包含关系属性(边也可以包含数据属性)图数据管理平台
顾名思义是用来管理图数据库的平台,一个图数据管理平台需要能对图数据库进行创建、读取、更新和删除(CRUD)操作。
应用情景
世界上很多互联网公司都会使用到图数据库,涉及的领域包含社交、零售、金融、电信等。在社交关系领域图数据库可以很好地管理用户的人际关系,而在零售领域可以应用在用户推送,金融领域可以用来做风控,而电信领域可以用来管理网络。根据具体的情景图形化数据库还能应用在很多其他需要体现数据内联关系的领域。
优点
性能
图数据库的查询只会遍历整个数据库中相关联的一个子图,所以数据库规模的成长不会对查询的难度有非常大的影响。
灵活性
图数据库的结构是可以随着需求的理解变更而逐步变化的,而不用提前做好完备的设计。而图本身是有良好的可扩展性的,不需要一开始就给出详尽的细节。
敏捷性两个重要属性
①图存储
有的图数据库使用专门为存储管理图而设计的本地图存储技术,但并不是所有图数据库都是用的本地图存储。有的图数据库将图数据序列化,然后保存到关系型数据库或者面向对象数据库,或其他通用数据存储中。
②图处理引擎
原生图处理(也称“无索引邻接”)是处理图数据的最有效方法,因为连接的节点在数据库中物理地指向彼此。非本机图处理使用其他方法来处理CRUD操作。小结
以上是《O'reillyGraphDatabases》前两章的内容,主要讲了图数据库的技术背景,特点,以及与传统数据库的区别。
-
雷博士牛逼!!!!(破音)
-
我上周刚好也在看这个...当时用的可视化工具是VOSviewer,获得学者的论文合作者关系图,这个直接导入文献信息就可以了;还想根据论文的title、abstract分析学者的研究方向,VOSviewer是基于co-occurrence分析的,效果也不太好
-
不过不是因为连线混论,而是VOSviewer根据聚类结果画出来的图看不出来研究领域...类似这种
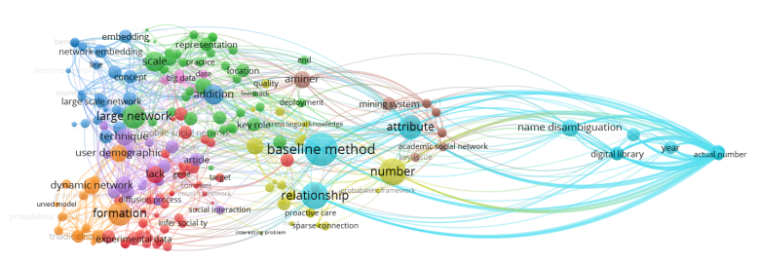
请问学长最后对于获得研究方向的关系图有什么想法吗?
-
@chivas 在 Neo4j与Cypher语言学习笔记(一) 中说:
不过不是因为连线混论,而是VOSviewer根据聚类结果画出来的图看不出来研究领域...类似这种
请问学长最后对于获得研究方向的关系图有什么想法吗?@Ryougi 雷博土来看看别人这个效果, 感觉有内味了诶.
-
@chivas
VOSviewer和citespace的原理和用法还挺像的,但是citespace好像只针对特定的几个数据库(web of science等),这个是我同学当时用citespace导出的效果图,因为词条比较少所以连线还是比较清晰的。

但是这个图的问题也是和你说的一样的看不出来研究领域什么的,首先是出现的词条类别就比较混乱,有的是研究领域,有的是专业名词,还有的是动词等等杂七乱八的;其次就是连线本身只是表明节点之间有关,没有具体的关系内容。我觉得有可能是citespace本身不能检索出这层信息,所以我打算自己用Neo4j整理一下这张图的词条,先对节点分类然后自己补充一些关系,再用Neo4j的浏览器把关系图导出来,但是我现在不是很清楚有哪些内容是我能够完善的以及词条之间到底怎么划分关系,所以我这边的图还没画完。
-
@ryougi
简单来说就是我怀疑这些个可视化工具并不能实现图中节点的归类的效果,或者是原来的数据库里面没有包含这部分信息,所以我现在想自己整理一个小的数据库然后用Neo4j的可视化工具导出一张图。
-
此回复已被删除!
-
此回复已被删除!
-
@ryougi 在 Neo4j与Cypher语言学习笔记(一) 中说:
@ryougi
简单来说就是我怀疑这些个可视化工具并不能实现图中节点的归类的效果,或者是原来的数据库里面没有包含这部分信息,所以我现在想自己整理一个小的数据库然后用Neo4j的可视化工具导出一张图。这个其实是和它们背后选用的算法有关...像VOSviewer的话就是对abstract做词共现分析,简单说就是如果这两个词总是同时出现,就认为它们关系紧密...然后根据关系远近聚类,关系近的就划分为同一类
-
@ryougi 在 Neo4j与Cypher语言学习笔记(一) 中说:
@chivas
VOSviewer和citespace的原理和用法还挺像的,但是citespace好像只针对特定的几个数据库(web of science等),这个是我同学当时用citespace导出的效果图,因为词条比较少所以连线还是比较清晰的。
但是这个图的问题也是和你说的一样的看不出来研究领域什么的,首先是出现的词条类别就比较混乱,有的是研究领域,有的是专业名词,还有的是动词等等杂七乱八的;其次就是连线本身只是表明节点之间有关,没有具体的关系内容。我觉得有可能是citespace本身不能检索出这层信息,所以我打算自己用Neo4j整理一下这张图的词条,先对节点分类然后自己补充一些关系,再用Neo4j的浏览器把关系图导出来,但是我现在不是很清楚有哪些内容是我能够完善的以及词条之间到底怎么划分关系,所以我这边的图还没画完。那可能是直接用citespace对的这些数据库接口然后在线分析的,不知道这样做提供的数据项有哪些...我是收集了一位学者的94篇论文pdf,然后进行元数据提取,能得到论文的title、author、kewywords、abstract、jounral、year等等信息,然后将RIS文件导入。而且其实我可以对VOSviewer最后筛选出来的关键词进行手动选择,如果是动词等等乱七八糟的我是可以划掉的,最后的可视化就不会出现这些词...但是我不可能对每一个学者都手动去操作QAQ
-
@unrealluver 是这样的,但是我还是觉得这个图显示的关系太杂乱了,有色图还好能在视觉上有个区分,但是如果引用在论文中黑白的话就啥都看不出来了。。。
-
@chivas
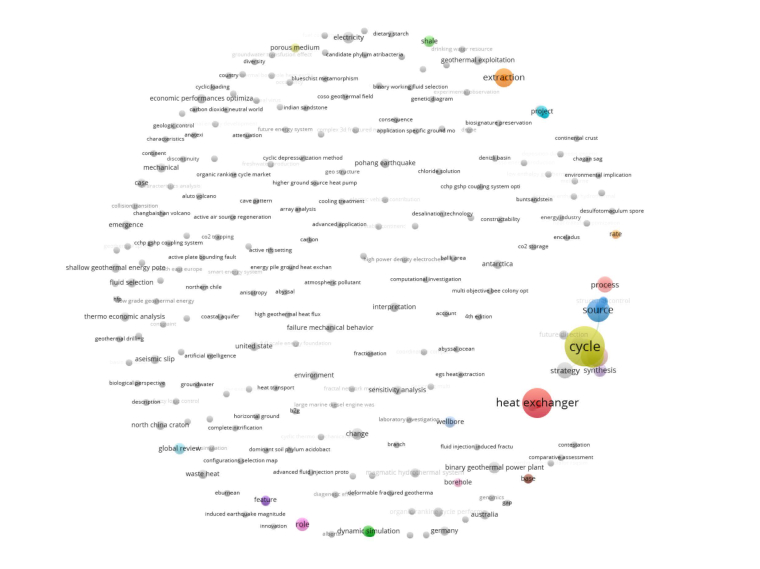
这个是我用VOSviewer绘制的关于“地热”的相关研究方向的图,我是直接在web of science数据库里检索“地热”词条然后导出的数据,然后直接丢到VOSviewer里面了。我记得配置里面好像有一项是过滤最小的关联子图,我好像是把那一项设置成1了结果所有的都显示出来了......但是如果我把那个设到最大,就只会显示图中右边这一个部分的子图,而且词条之间隔得很远,有什么好的解决方案吗(还是说我的使用方法不太对)
-
@ryougi 原来是这样!
-
@ryougi 在 Neo4j与Cypher语言学习笔记(一) 中说:
@chivas
这个是我用VOSviewer绘制的关于“地热”的相关研究方向的图,我是直接在web of science数据库里检索“地热”词条然后导出的数据,然后直接丢到VOSviewer里面了。我记得配置里面好像有一项是过滤最小的关联子图,我好像是把那一项设置成1了结果所有的都显示出来了......但是如果我把那个设到最大,就只会显示图中右边这一个部分的子图,而且词条之间隔得很远,有什么好的解决方案吗(还是说我的使用方法不太对)
你选的是based on text data还是bibliographic data啊?从图上看好像是bibliographic中的keyword...如果是这样的话很正常,因为VOSviewer是基于共现的,也就是说看一句话里几个词同时出现的频率和距离情况...而如果你选的是基于keyword分析的话,最后的结果当然大部分是一个个孤立且频次为1的词
-
@chivas 在 Neo4j与Cypher语言学习笔记(一) 中说:
不过不是因为连线混论,而是VOSviewer根据聚类结果画出来的图看不出来研究领域...类似这种
请问学长最后对于获得研究方向的关系图有什么想法吗?用VOSviewer分析abstract和title才会看出一点效果来...这张图就是的,因为abstract中才看得出上下文,能计算词出现的频率和关联度
-
@ryougi 我上周看见收到了回复但一直没找出时间好好回...最近实验实在太多了QAQ不好意思
直接在web of science数据库里检索“地热”词条然后导出的数据
这样导出的数据在基于abstract和title的分析情况下,如果信息条数足够多,应该还是能看出一点效果来的。不过这种做法通常是用来分析某一领域今年来的研究热点:导出某一领域在某段时间内的高引或热点论文。这里有一个例子:基于文献计量的大数据研究现状分析 这样的情况下用VOSviewer等现成的分析工具是能得到不错的效果。
我后来自己实验的时候换了一种方法,从CNKI上导出了data mining、social network、natural language processing、semantic network、predictive model这五个研究方向下各100条文献信息进行分析,然后VOSviewer得到了一张这样的图:
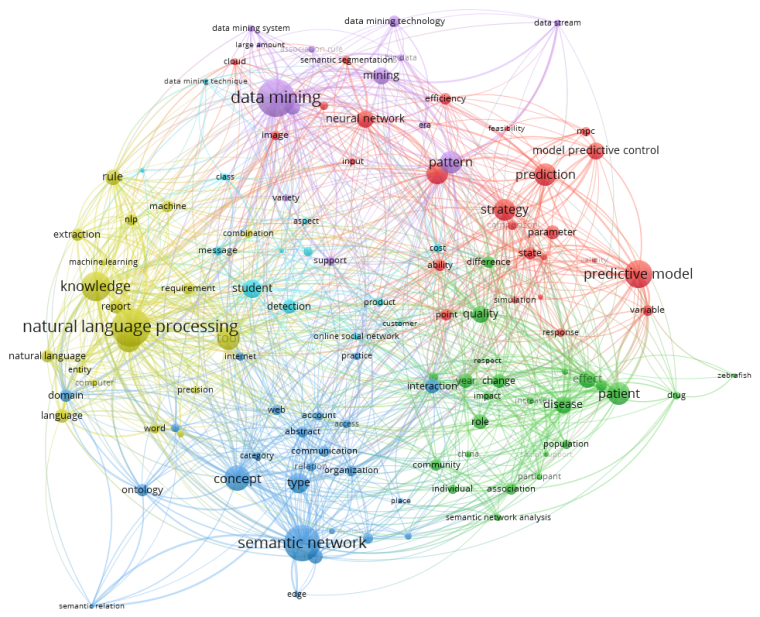
分析结果和我筛选数据时的选择基本吻合。
-
但如果是想针对某一学者的所有论文信息分析出他/她的研究方向的话,我觉得VOSviewer可能就不太行了...但可能也和数据集大小有关,我选的那位学者我只拿到了90+论文的文献信息,所以分析结果看不出什么来。如果是那种paper上千的大牛,拿到其所有论文的文献信息的话,应该也会效果不错?
-
总而言之,我认为这些现成的分析工具只适用于两种情况:
- 答案基本唯一的分析,通常只是进行一些count的工作:例如基于论文合作者信息的学者关系网络,基于引文信息的论文关系图等等。这种分析基本上就是跑一个图的算法,遍历或者计数统计一下,类似VOSviewer这样的工具省去了自己写代码的功夫;
- 使用它们背后的模型(例如VOSviewer就是词共现)并适当调参能得到较好效果的分析,具体来说还是以VOSviewer为例,分析领域研究热点和关键词,但这需要一定的数据集支撑。而像我这种情况——想分析出每位学者的研究方向和领域变化,更“个性化”一些的分析,一般来说数据集较小,还是只能另寻他法。
-
记得第一次接触是雷博士的技术分享,学到了!!!