Attention Mechanism系列1 - RNN与Attention
-
References
- 完全图解RNN、RNN变体、Seq2Seq、Attention机制
- Sequence Modeling using Gated Recurrent Neural Networks
- CS224n笔记-lecture9
- CS224n笔记-lecture10
- Attention机制详解(一)——Seq2Seq中的Attention
在介绍Attention之前,我们先回顾一下RNN及Improved RNN。
RNN
RNN的hidden state计算公式如下:
其中,
为激活函数。 GRU

如图,GRU在RNN的基础上引入了
reset gate和update gate两个门,其计算公式如下:当前输入状态公式如下:
最终的隐藏层状态如下:
reset gate用于控制前一记忆对当前输入的影响程度,若,则之前层的记忆被遗忘。 update gate用于控制当前输入对隐藏层状态的影响程度,若,则当前状态与输入无关,只会复制前一状态。
LSTM

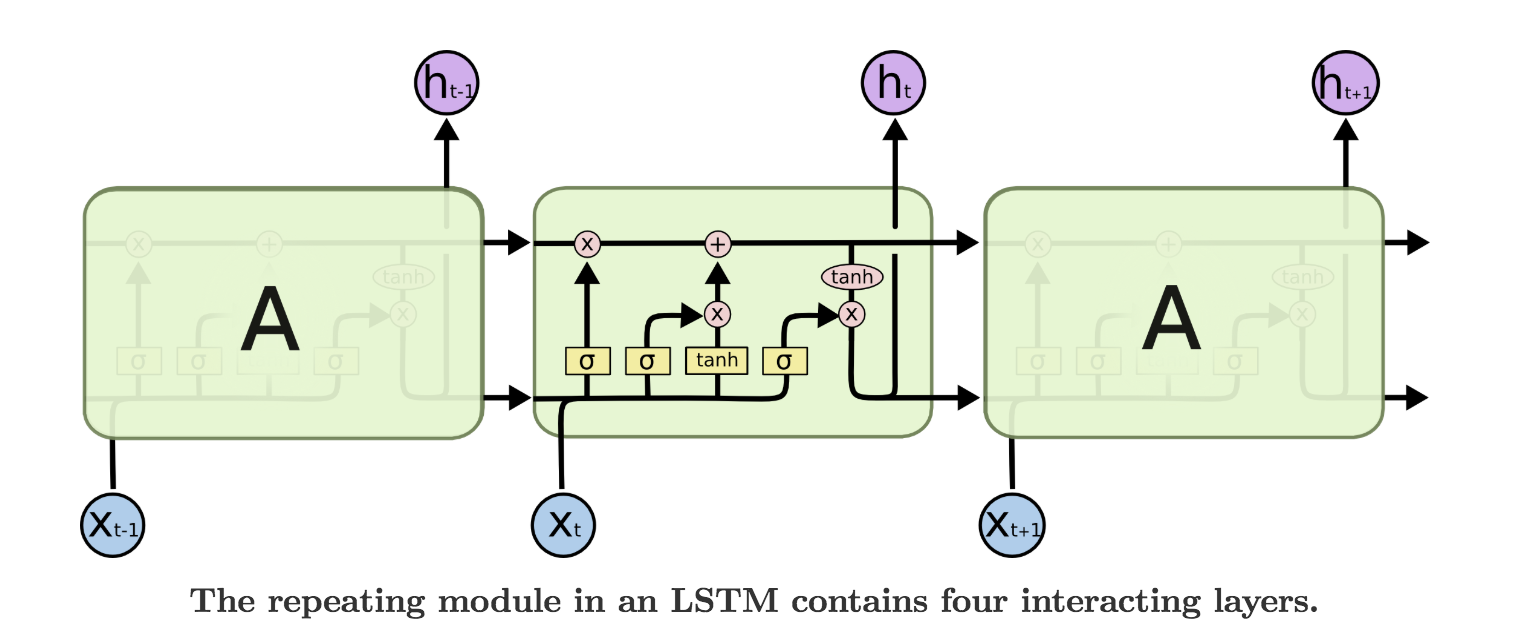
RNN结构
1. 经典的RNN结构 (N to N)
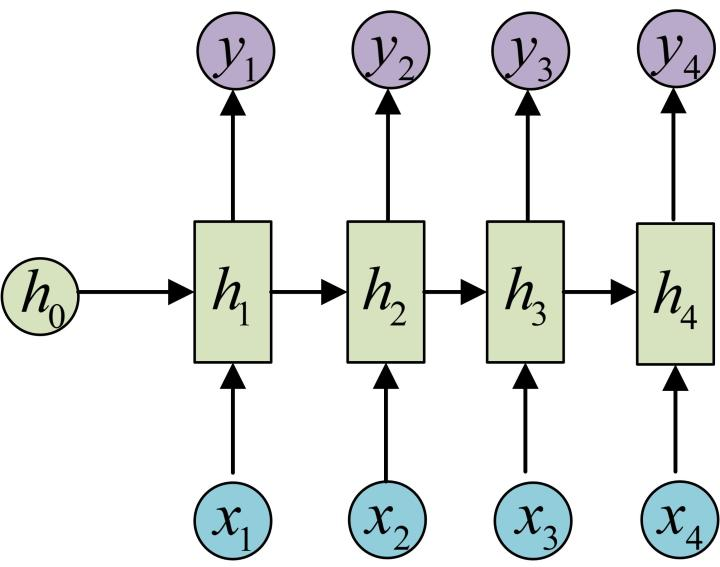
经典的RNN结构输入与输出均为相同
长度的序列,其将每一节点均作为输出。输入与输出序列长度相同限制了其的应用,可用于视频帧分类、下一字符概率预测等任务。 2. N to 1
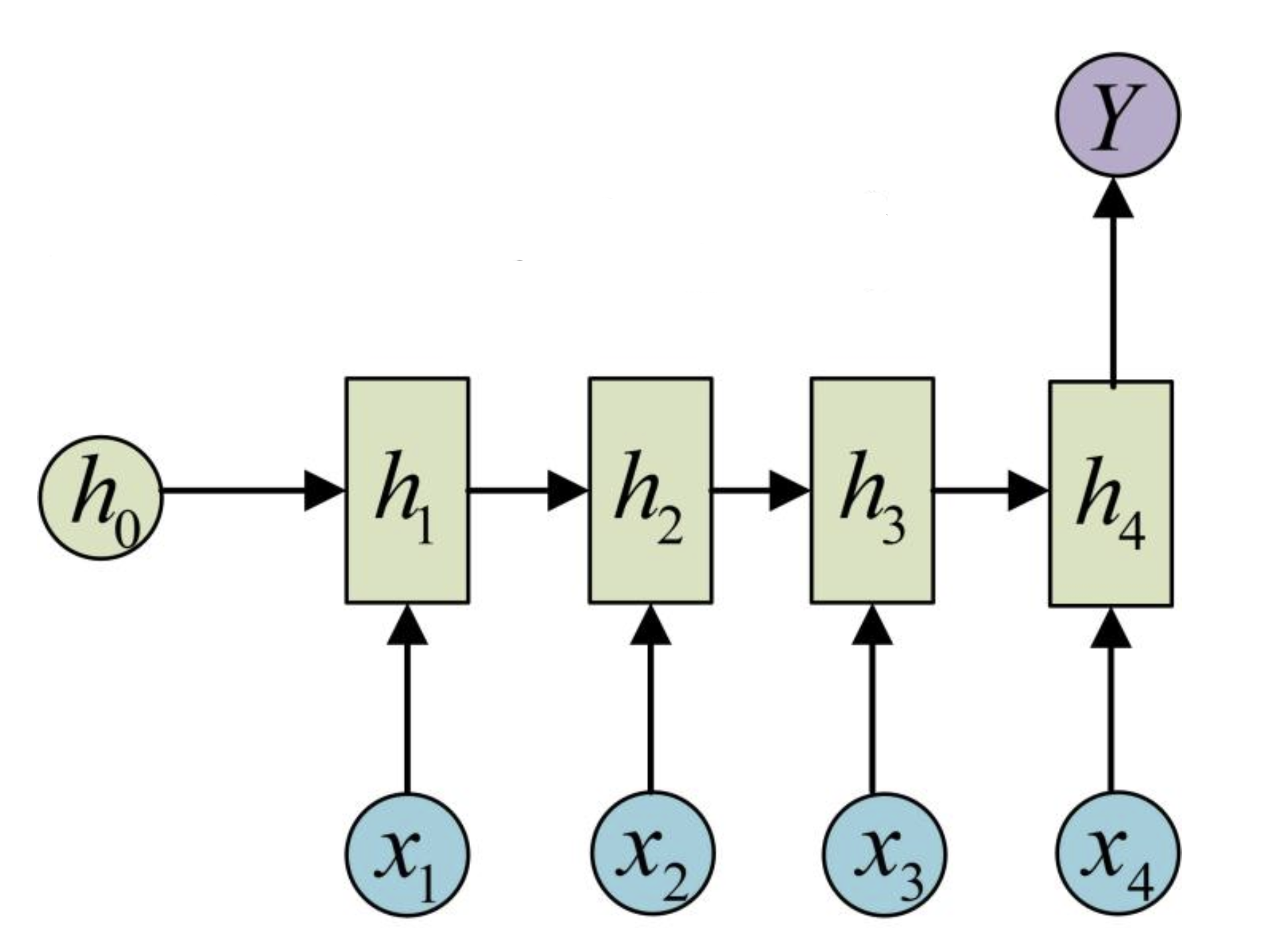
N to 1结构通过长度为的输入序列得到长度为1的输出,其将最后节点的hidden state作为输出用于下层网络,主要用于分类问题,如:文本分类,视频分类。 3. 1 to N
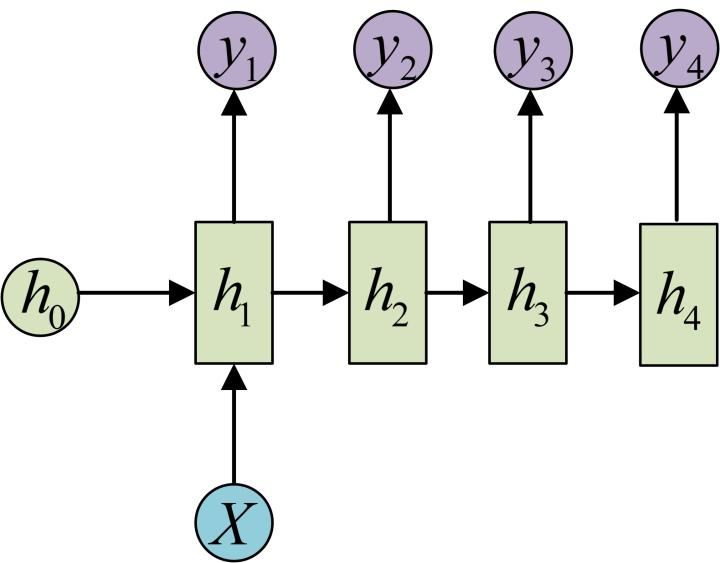
如果是想通过1得到长度为
的序列输出呢? 这里有两种方法:
-
只在序列开始时将向量输入进行计算
-
在每一个节点均作为输入进行计算
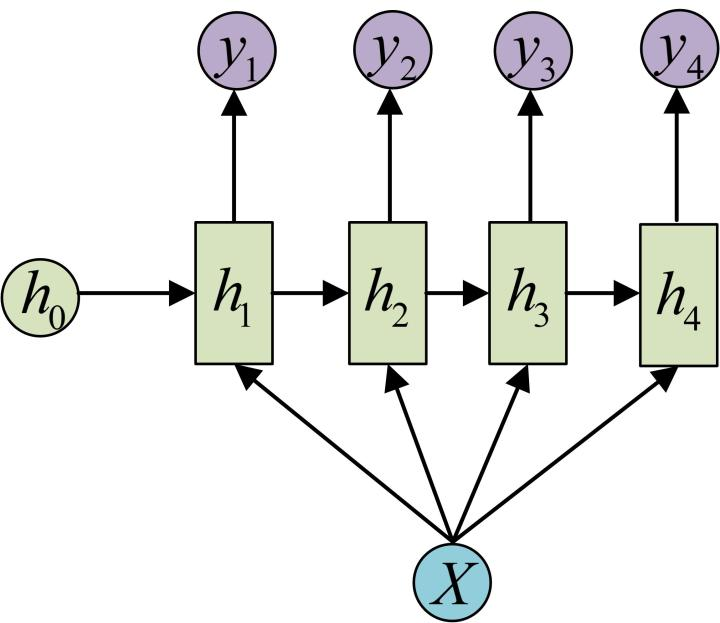
这样的应用有:看图说话、通过类别生成音乐等。
4. N to M
这种结构是RNN最重要的一种变种,可以通过变长的输入得到变长的输出,这种模型称为Encoder-Decoder模型,也可以称为Sequence-to-Sequence模型。
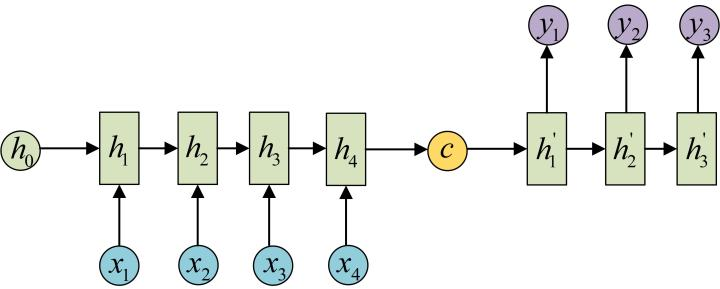
Seq2Seq结构是由两个RNN构成的,一部分为
N to 1,一部分为1 to M,这样就可以将 模型变为N to M,由于1 to N有两种方式,因此Seq2Seq也有两种结构:-
Decoder只在序列开始时输入c
-
Decoder在序列的每一步均输入c
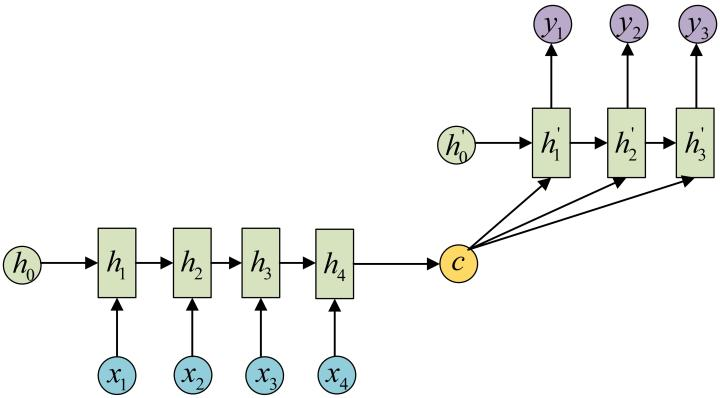
Seq2Seq的模型应用范围十分广泛,如:机器翻译、语音识别、文本摘要等。
Attention Mechanism
关于Attention的更详细介绍可见:CS224n笔记-lecture10
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码,因此, c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个c可能存不下那么多信息,就会造成翻译精度的下降。
于是我们想通过将所有encoder的hidden state输出,在不同的decoder时间节点根据当前decoder状态选择不同的c作为输入,来解决这一瓶颈。
Seq2Seq Attention
下面我们来详细介绍Seq2Seq中attention的计算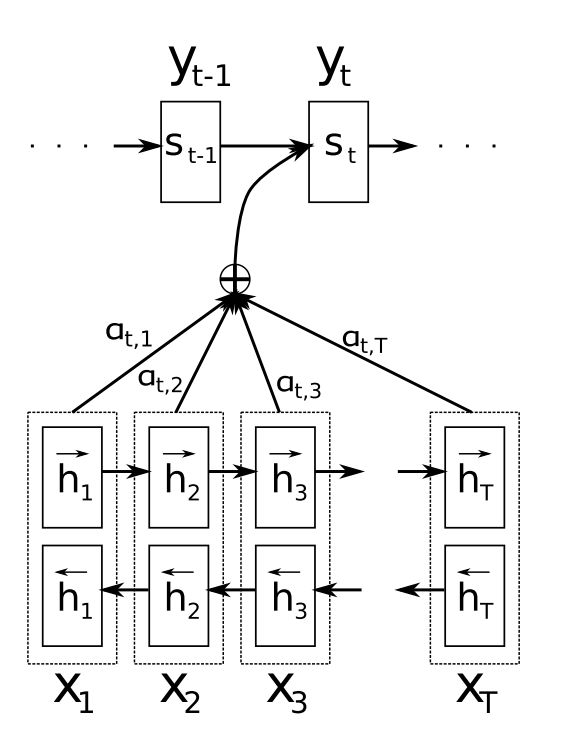
在这里,我们先通过encoder得到每一个时间节点的隐藏状态:
假设decoder当前的隐藏状态是
,那么我们可以得到其与每一个 的关联性 这里,
为计算相关性的方法,常见的有点乘、加权点乘、加权和。 接着我们使用softmax对
进行归一化: 再接着我们用
对 进行加权求和得到当前输入: 因此,我们的decoder隐藏状态为:
-
attention怎么就没了?