常用数据结构和算法一般都怎么应用?一些业界常见做法收集
-
相对于枯燥的理论课,想必团队的大家还是更喜欢能实际应用的玩意。这里就来收集一些业界是怎么把这些数据结构和算法应用起来的知识,并附带一些实现。
-
radix tree在router(路由)中的应用
先不说
radix tree,先思考一个问题,平时我们访问web页面的url那么大一串。Server是依靠什么快速通过这些路径返回指定资源的呢?比如https://bbs.dian.org.cn/topic/756/balabala,我们可以看出来这个url是有层次结构的。自然理解就是/topic路径下的id=756号的名为balabala的资源(抽象来说)。一看到字符串匹配,查找,常数时间这几个关键字,可能会下意识想到哈希表的办法。但是很遗憾的是http的url一般没有什么特定规律,散列函数可不好找,Hash Conflict是很大几率会出现的。就算使用分离链接消除冲突,大量动态内存分配的耗时不一定是可以接受的。用开放定址法也无法避免表的查找性能降低。且哈希表丢失了原有的url的层级信息,得不偿失。
一般自然的想法是使用树的结构描述层级数据, 然后我们发现这个场景对插入性能要求并不高,http路由一般是在运行之前就写好,编译到程序中的。一般来说只需要读取一次,也就是只需要建树那一次Insert就足够了,这上面的耗时都在程序启动,不构成影响。
-
那么我们确定用树的结构描述这个url了,有个字典查找树Trie Tree好像有点类似我们的需求。
课本上讲的:Trie树有3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符;
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
- 每个节点的所有子节点包含的字符都不相同。
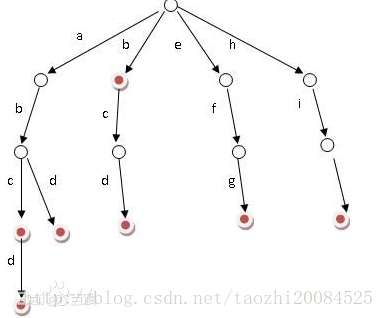 Trie树应用:
Trie树应用:
a. 串的快速检索:
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
在这道题中,我们可以用数组枚举,用哈希,用字典树,先把熟词建一棵树,然后读入文章进行比较,这种方法效率是比较高的。
b. “串”排序:
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出。
用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可。
c. 最长公共前缀
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为当时公共祖先问题(以后补上)。
好吧上面这些只是在水贴。Trie Tree其实不符合需求,因为我们的url的path并不需要一个字符一个字符地匹配。
-
业界针对路由或类似需求时一般使用前缀树的变体———基数树(radix tree)。
之前和郭英才讨论这个问题时,他下意识地说可能是用后缀树自动机。但实际上应该用前缀树,后缀树在解决串查找比较好,http router更多的应该是匹配而不是查找,输入实际上在一定程度上是可知的(胡乱输入的字符串自然是返回404 status code了, 这时候全查一遍反而浪费),用后缀树有点杀鸡牛刀。
-
实现:(Talk is cheap)
C版本麻烦点,我想好再写。
go版本(章口就莱):type Router struct { // 这个radix tree是最重要的结构 // 按照method将所有的方法分开, 然后每个method下面都是一个radix tree trees map[string]*node // 当/foo/没有匹配到的时候, 是否允许重定向到/foo路径 RedirectTrailingSlash bool // 是否允许修正路径 RedirectFixedPath bool // 如果当前无法匹配, 那么检查是否有其他方法能match当前的路由 HandleMethodNotAllowed bool // 是否允许路由自动匹配options, 注意: 手动匹配的option优先级高于自动匹配 HandleOPTIONS bool // 当no match的时候, 执行这个handler. 如果没有配置,那么返回NoFound NotFound http.Handler // 当no natch并且HandleMethodNotAllowed=true的时候,这个函数被使用 MethodNotAllowed http.Handler // panic函数,错误处理 PanicHandler func(http.ResponseWriter, *http.Request, interface{}) }type node struct { // 保存这个节点上的URL路径 path string // 判断当前节点路径是不是参数节点 // 节点类型包括static, root, param, catchAll // static: 静态节点, 例如上面分裂出来作为parent的s // root: 如果插入的节点是第一个, 那么是root节点 // catchAll: 有*匹配的节点 // param: 除上面外的节点 nType nodeType // 记录路径上最大参数个数 maxParams uint8 // 和children[]对应, 保存的是分裂的分支的第一个字符 // 例如search和support, 那么s节点的indices对应的"eu" // 代表有两个分支, 分支的首字母分别是e和u indices string // 保存孩子节点 children []*node // 当前节点的处理函数 handle Handle // 优先级, 保证健壮性用的,免得有沙雕用户输入冲突的路由 priority uint32 }建树过程:
// 向tree中增加节点 func (n *node) addRoute(path string, handle Handle) { fullPath := path n.priority++ numParams := countParams(path) // non-empty tree // 如果之前这个Method tree中已经存在节点了 if len(n.path) > 0 || len(n.children) > 0 { walk: for { // Update maxParams of the current node // 更新当前node的最大参数个数 if numParams > n.maxParams { n.maxParams = numParams } // Find the longest common prefix. // This also implies that the common prefix contains no ':' or '*' // since the existing key can't contain those chars. // 找到最长公共前缀 i := 0 max := min(len(path), len(n.path)) // 匹配相同的字符 for i < max && path[i] == n.path[i] { i++ } // Split edge // 说明前面有一段是匹配的, 例如之前为:/search,现在来了一个/support // 那么会将/s拿出来作为parent节点, 将child节点变成earch和upport if i < len(n.path) { // 将原本路径的i后半部分作为前半部分的child节点 child := node{ path: n.path[i:], wildChild: n.wildChild, nType: static, indices: n.indices, children: n.children, handle: n.handle, priority: n.priority - 1, } // Update maxParams (max of all children) // 更新最大参数个数 for i := range child.children { if child.children[i].maxParams > child.maxParams { child.maxParams = child.children[i].maxParams } } // 当前节点的孩子节点变成刚刚分出来的这个后半部分节点 n.children = []*node{&child} // []byte for proper unicode char conversion, see #65 n.indices = string([]byte{n.path[i]}) // 路径变成前i半部分path n.path = path[:i] n.handle = nil n.wildChild = false } // Make new node a child of this node // 同时, 将新来的这个节点插入新的parent节点中当做孩子节点 if i < len(path) { // i的后半部分作为路径, 即上面例子support中的upport path = path[i:] // 如果n是参数节点(包含:或者*) if n.wildChild { n = n.children[0] n.priority++ // Update maxParams of the child node if numParams > n.maxParams { n.maxParams = numParams } numParams-- // Check if the wildcard matches // 例如: /blog/:ppp 和 /blog/:ppppppp, 需要检查更长的通配符 if len(path) >= len(n.path) && n.path == path[:len(n.path)] { // check for longer wildcard, e.g. :name and :names if len(n.path) >= len(path) || path[len(n.path)] == '/' { continue walk } } panic("path segment '" + path + "' conflicts with existing wildcard '" + n.path + "' in path '" + fullPath + "'") } c := path[0] // slash after param if n.nType == param && c == '/' && len(n.children) == 1 { n = n.children[0] n.priority++ continue walk } // Check if a child with the next path byte exists // 检查路径是否已经存在, 例如search和support第一个字符相同 for i := 0; i < len(n.indices); i++ { // 找到第一个匹配的字符 if c == n.indices[i] { i = n.incrementChildPrio(i) n = n.children[i] continue walk } } // Otherwise insert it // new一个node if c != ':' && c != '*' { // []byte for proper unicode char conversion, see #65 // 记录第一个字符,并放在indices中 n.indices += string([]byte{c}) child := &node{ maxParams: numParams, } // 增加孩子节点 n.children = append(n.children, child) n.incrementChildPrio(len(n.indices) - 1) n = child } // 插入节点 n.insertChild(numParams, path, fullPath, handle) return // 说明是相同的路径,仅仅需要将handle替换就OK // 如果是nil那么说明取消这个handle, 不是空不允许 } else if i == len(path) { // Make node a (in-path) leaf if n.handle != nil { panic("a handle is already registered for path '" + fullPath + "'") } n.handle = handle } return } } else { // Empty tree // 如果是空树, 那么插入节点 n.insertChild(numParams, path, fullPath, handle) // 节点的种类是root n.nType = root } }
-
在实现C语言radix tree之前,我先挂一道挑战大的面试题目,当作是
真实任务驱动我也是刚刚看到,有兴趣的同学可以一起来解一下,互相交流:
这是百度的面试题:url地址 比如https://www.baidu.com/s?wd=baidu 的属性,包括定长属性(比如其被系统发现的时间)和不定长属性(比如其描述)实现一个系统
a. 储存和维护100亿个url及其属性。
b. 实现url及其属性的增删改。
c. 查一个url是否在系统中并给出信息。
d. 快速选出一个站点下所有url