【学习笔记】cs229机器学习笔记(二)
-
分类问题
逻辑回归(分类算法)
想要预测的0,1二元分类问题
sigmoid将分类的结果很好的映射成为[0,1]之间的概率

- 逻辑回归最大的优势在于它的输出结果不仅可以用于分类,还可以表征某个样本属于某类别的概率。
- 逻辑斯谛函数将原本输出结果从范围(−∞,+∞)(−∞,+∞) 映射到(0,1),从而完成概率的估测。
- 逻辑回归得判定的阈值能够映射为平面的一条判定边界,随着特征的复杂化,判定边界可能是多种多样的样貌,但是它能够较好地把两类样本点分隔开,解决分类问题。
- 求解逻辑回归参数的传统方法是梯度下降,构造为凸函数的代价函数后,每次沿着偏导方向(下降速度最快方向)迈进一小部分,直至N次迭代后到达最低点。
-
逻辑回归补充
逻辑回归的损失函数
-
如果采用线性回归的损失函数采用的平方损失函数
即
则会导致成本函数sigmoid()是一个非凸函数,收敛于局部最低点而无法收敛在全局最低点上。
如图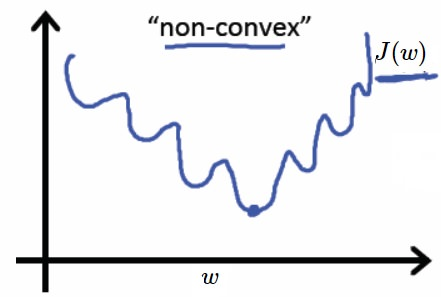
因此逻辑回归中在针对二分类问题上以下代价函数:

进而得到的损失函数能保证是凸函数:

它保证了一种代价“惩罚机制”,随着预测值与实际值偏差越大,代价函数将激增。
梯度下降找θ最小化
同时更新所有的θ值,与线性回归的梯度下降规则完全相同。。
但是假设两者不相同。 - 实现方法上向量法便于所有θ的同步更新。
比梯度下降更高效的优化算法
优化逻辑回归的速度,主要考虑对于J(θ)和偏导项计算的效率优化。
优点在于收敛速度更快并且学习速率α可以自动调整,缺点在于算法较为复杂。-
共轭梯度法Conjugate gradient
-
-
多分类问题(one-vs-all)
主要思想:将二元分类问题拓展到n元分类问题中去。
采用“一对余”方法,将其分解为n个二元分类问题,选定一个i类别的训练集为正样本(1),其它设定为负样本(0)。然后通过二元分类,得到 ( )的逻辑回归分类器。
其中( )=P(y=i|x;θ).
最后,在多类别分类时,在n个分类器中选取max{( )}对应的i即可。
-
过拟合overfitting(高方差)问题
- 当函数的变量很多、训练集较小时,函数能够很高的拟合训练集的数据,而无法泛化到新的样本中去。
e.g:线性回归下的三种情形:- 欠拟合(高偏差)
- 恰好
- 过拟合(高方差)
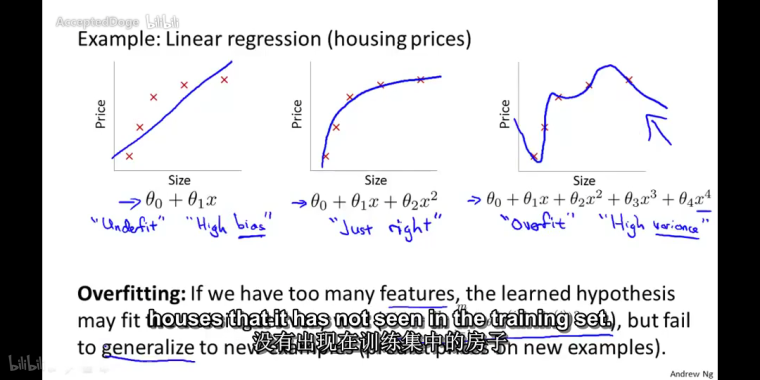
解决方案 - 减少选取变量的数量(人工检查,模型选择算法)(问题:减少特征变量的同时也舍弃了问题中的一些信息)
- 正则化(保留所有的特征变量但是减少参数值的大小或者是数量级)
- 当函数的变量很多、训练集较小时,函数能够很高的拟合训练集的数据,而无法泛化到新的样本中去。
-
为什么通常Relu比sigmoid和tanh强,有什么不同?(收藏一下)
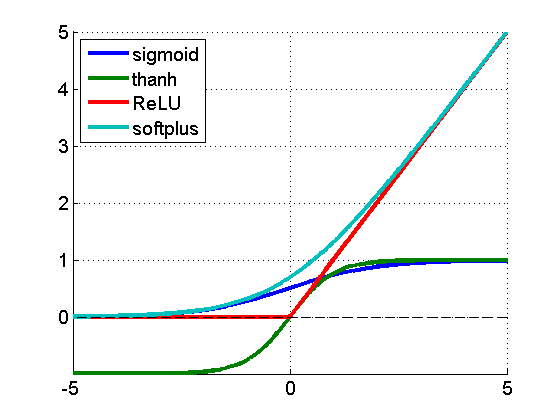
主要是因为它们gradient特性不同。sigmoid和tanh的gradient在饱和区域非常平缓,接近于0,很容易造成vanishing gradient的问题,减缓收敛速度。vanishing gradient在网络层数多的时候尤其明显,是加深网络结构的主要障碍之一。相反,Relu的gradient大多数情况下是常数,有助于解决深层网络的收敛问题。Relu的另一个优势是在生物上的合理性,它是单边的,相比sigmoid和tanh,更符合生物神经元的特征。
而提出sigmoid和tanh,主要是因为它们全程可导。还有表达区间问题,sigmoid和tanh区间是0到1,或着-1到1,在表达上,尤其是输出层的表达上有优势。为什么引入Relu呢?
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
copied from ReLu(修正线性单元)、sigmoid和tahh的比较
-
Tensorflow搭建神经网络初步实践(基础)
(正好学习到了cs229的神经网络部分,开始跟着教程实践一下!)
神经网络的基本模型是神经元,基本模型其实就是乘加运算。
一些概念:-
基于TensorFlow的NN:用张量表示数据,用计算图搭建神经网络,用会话执行计算图,优化线上的权重,得到模型。
-
张量是多维数组,用阶表示张量的维度。
-
0阶张量称作标量,是一个单独的数
-
1阶张量称作向量,是一维数组
-
2阶张量称作矩阵,表示一个二维数组
-
n阶张量,表示为t[[[[[...]]]]](n 个)
-
-
数据类型:主要有tf.float32,tf.int32
-
计算图:搭建神经网络法人计算过程,只是承载一个或多个计算节点的一张图,只搭建网络,不运算。
-
会话:执行计算图中的节点运算
-
神经网络的参数:指的是神经网络线上的权重w,一般会先随机生成。生成参数方法是让w=tf.Variable(生成方式)
神经网络中常见的生成随机数/数组的函数有:
tf.random_normal()生成正态分布随机数
tf.truncated_normal()生成去掉过大偏离点的正态分布随机数
tf.random_uniform()生成均匀分布的随机数

补充(正态分布和均匀分布(高斯分布))

Ex1:(张量加法)
import tensorflow as tf a=tf.constant([1.0,2.0]) b=tf.constant([3.0,4.0]) result=a+b print(result)Output:
Tensor("add:0",shape=(2,),dtype=float32)Ex2:(矩阵乘法)
import tensorflow as tf #计算图的实现 x=tf.constant([[1.0,2.0]]) w=tf.constant([[3.0],[4.0]]) y=tf.matmul(x,w) print(y) #会话的with结构实现 with tf.Session() as sess: print(sess.run(y))Output:
Tensor("matmul1:0",shape(1,1),dtype=float32) [[11.]]
-
-
Tensorflow搭建神经网络初步实践(前向传播)
神经网络的实现过程
1.准备数据集、提取特征作为输入喂给神经网络(NN)
2.搭建NN结构,从输入到输出(先搭建计算图再用会话执行)
( NN 前向传播算法计算输出)
3.大量特征数据喂给NN,迭代优化NN参数
(NN反向传播算法优化参数训练模型)
4.使用训练好的模型预测和分类
前向传播就是搭建模型的计算过程,让模型具有推理能力 可以针对一组输入给出相应的输出。
EX1:#coding:utf-8 import tensorflow as tf #输入层 x=tf.constant([[0.7,0.5]]) #w为待优化的权重 #其中,stddev为标准差,seed为随机种子 w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) #将每层输入乘以权重进行矩阵乘法,得到输出y a=tf.matmul(x,w1) y=tf.matmul(a,w2) with tf.Session() as sess: init_op=tf.global_variables_initializer() #在sess.run中写入init_op实现对于所有变量的初始化 sess.run(init_op) #计算图运算,输出结果 print(sess.run(y))EX2:
import tensorflow as tf #tf.placeholder给输入占位,以便一次喂入一组或者多组数据 x=tf.placeholder(tf.float32,shape=(1,2)) w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) #前向传播 a=tf.matmul(x,w1) y=tf.matmul(a,w2) with tf.Session() as sess: init_op=tf.global_variables_initializer() sess.run(init_op) print(sess.run(y,feed_dict={x:[[0.7,0.5]]}))#,feed_dict喂数据EX3:
import tensorflow as tf x=tf.placeholder(tf.float32,shape=(None,2)) w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) a=tf.matmul(x,w1) y=tf.matmul(a,w2) with tf.Session() as sess: init_op=tf.global_variables_initializer() sess.run(init_op) print(sess.run(y,feed_dict={x:[[0.7,0.5],[0.2,0.3],[0.3,0.4],[0.4,0.5]]})) print(sess.run(w1)) print(sess.run(w2))
-
@xuxiaohao 建议尝试不用深度学习框架,只用numpy实现神经网络的前向传播和反向传播
-
@zkhust 谢谢学长!那我去学习一下numpy!
-
深度学习算法学习
神经网络前向传播递推矩阵递推公式(推导练习,加深对深度学习理解)
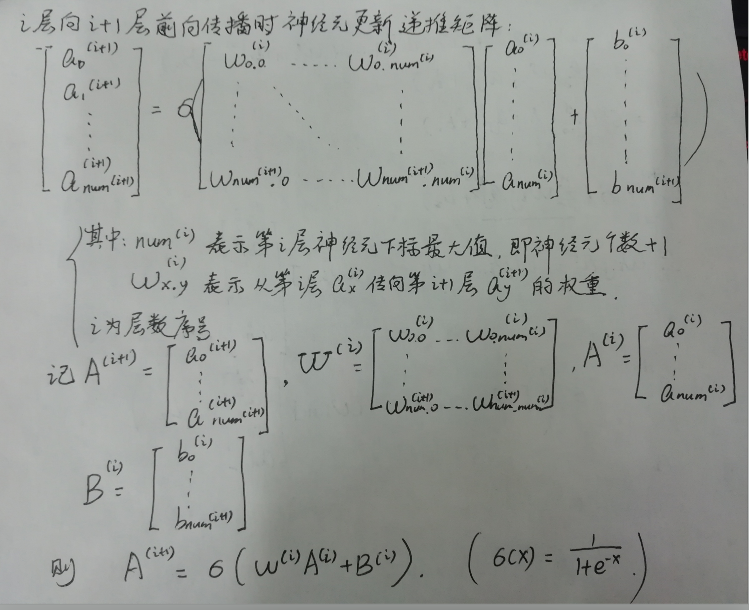
【温故知新】:-
神经元可以看做一个函数
-
函数的梯度反映的是函数的最陡增长方向
-
代价函数是以bias和weight为输入,大量带标记训练数据集为参数,以一个代价数为输出的函数
-
梯度下降算法首先计算梯度值,然后每次沿着梯度向量的反方向行走一小步 ,不断重复可以收敛。
-
梯度向量的相反数告诉我们如何微调权重偏置的值。变动大小与 |现值-目标值| 成正比。
-
反向传播算法算的是单个训练样本想怎样修改权重与偏置,不仅是说每个参数应该变大还是变小,还包括了每个参数应该变大还是变小,才能够最快地降低代价。
-
反向传播算法的微积分原理:
如图:计算代价函数对于权重的敏感程度计算公式

-
-
深度学习反向传播算法学习
- 反向传播,用于训练模型参数,在所有参数上采用梯度下降,使得NN模型在训练数据上的损失函数最小
- 损失函数,是预测值与已知答案的差距
- 采用sigmoid等激励函数是为了当权重与偏置有一定改变时,损失函数的变化较小(相比较,感知器的激活函数则是一个阶跃函数,损失函数的会因为权重的微小变化而发生突变)。
- 学习率,决定了参数每一次更新的幅度。
反向传播算法的方法:
1.将输出层的误差按权重分配,反向传播给隐藏层
2.链式求导,根据求得的误差来求各个误差值对权重的偏导
: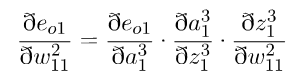
其中:
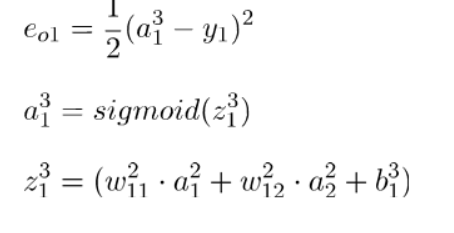
3.将计算所得的偏导值代入梯度下降公式中,进一步对于每一层的参数进行更新。
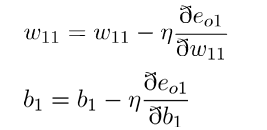
敲重点
经典书籍《神经网络与深度学习》中对于delta的描述为在第l层第j个神经元上的误差,定义为误差对于当前带权输入求偏导,公式如下:
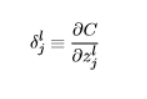
反向传播4大公式(矩阵化后便于利用矩阵乘法编程实现)
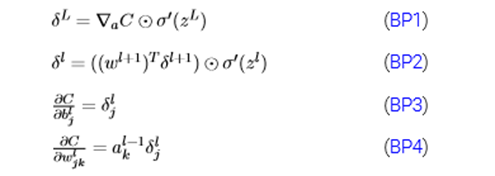
(看了一下Stanford上面的CS229的note和problem set,感觉自己看的吴恩达机器学习CS229的版本简单好多啊)
-
用numpy实现最简单的NN
写了一个没有bias,没有正则化,没有很多隐藏层的NN,
后续不断优化吧。。
(bug:一开始写了一个有问题的输入,导致输入矩阵不可逆,出现了函数没法收敛问题。)#-*- coding:utf-8 -*- import numpy as np #将变量映射到(0,1)区间 def sigmoid(x): return 1/(np.exp(-x)+1) def deriv(x): return x*(1-x) #输入数据 x=np.array([[0,0,1], [0,1,1], [1,0,1], [1,1,1]]) #输出数据 y=np.array([[0], [1], [1], [0]]) #初始化随机种子,保证每一次生成的随机数相同 np.random.seed(1) #权重随机初始化 w0=2*np.random.random((3,4))-1 w1=2*np.random.random((4,1))-1 #训练 for j in range(60000): #正向传播 a0=x a1=sigmoid(np.dot(a0,w0)) a2=sigmoid(np.dot(a1,w1)) a2_error=(y-a2) if(j%10000)==0: print("Error:"+str(np.mean(np.abs(a2_error)))) #反向传播误差值 a2_delta=a2_error*deriv(a2) a1_error=a2_delta.dot(w1.T) a1_delta=a1_error*deriv(a1) #梯度下降更新权值 w1+=(a1.T).dot(a2_delta) w0+=(a0.T).dot(a1_delta)误差收敛情况:
Error:0.4964100319027255 Error:0.008584525653247157 Error:0.005789459862507806 Error:0.004629176776769983 Error:0.003958765280273646 Error:0.0035101225678616736
-
NUMPY学习
(跟着教程走了一遍NUMPY的基本语法,待日后方便查询。。。)
#NUMPY ARRAY BASIC import numpy as np ###########################3 #part1:basis ############################ a=np.array([[1,2],[0,3]],dtype=np.int64) a.dtype#dtype=np.int64 a.dtype.name#int64 a.size(4) a.shape#(2,2) a.ndim#dimension 2 np.zeros((2,3))#all 0s np.ones(((3,4))#all 1s np.empty((4,5))#all numbers->0 np.arange(12).reshape((3,4))#generate numbers ranging from 0-11 #and shape is (3,4) np.arange(10,20,2)#step is 2 np.linspace(1,10,20)#cut a line into 20 parts np.linspace(1,10,2).reshape(2,1)#change the vector into matrix ############################ #part2:calculations1 ########################### c=b**2#c=b^2 b=np.array(4),print(b==3) #output:[False,False,False,True] c=a*b#output,ci=ai*bin np.dot(a,b)#matrix multi <=>a.dot(b) ######################### #part3:random number ######################### a=np.random.random((2,4))#generate a (2,4) matrix whose values are in (0,1) np.max(a) np.min(a) np.sum(a) np.max(a,axis=0)#find max in rows np.min(a,axis=1)#find min in cals ######################### #part4:calculations2 #################### A=np.arange(2,14).reshape((2,6)) indexOfMin=np.argmin(A) np.mean(A)#average1 np.average(A)#average np.median(A)#zhong wei shu C=np.cumsum(A)#C[0]=A[i],C[i+1]=C[0]+A[i+1] D=np.diff(A)#D[i+1]=A[i+1]-A[i] np.nonzero(A)#find nonzero numbers np.sort(A)#sort for each rows np.transpose(A)#A.T (A.T).dot(A)=E np.clip(A,a_min,a_max)#{all numbers:<a_min}:=a_min,{all numbers:>a_max}:=a_max np.mean(A,axis=0) ############################ #part5:Index ############################# a[2] a[2,1]<=>a[2][1] a[2,:]# row vector 2 a[:,1]# cal vector 1 a[1,1:2]# number in row vector 1 and(cal index ranging from [1,2)) for row in A: print(row)#output its rows for col in A.T: print(col)#output its columns A.flatten()#change A into one dimension list for item in A.flat:#A.flat is a iteration ############################## #part7:Emerge ############################### A=np.array([1,1,1]) B=np.array([2,2,2]) np.vstack((A,B))# vertical stack np.hstack((A,B)) #horizontal stack,out put:[1 1 1 2 2 2] A[np.newaxis,:] #add a new dimension in front of original dimensions C=np.concatenate((A,A,B,B),axis=0)#Multi-Matrix emerge in the vertical axis ########################################## #part8: Split ########################################### A=np.arange(12).reshape(3,4) np.split(A,2,axis=1)#split the array into equal arrays np.array_split(A,3,axis=1)#unequal arrays np.vsplit(A,3) #vertical split np.hsplit(A,2) #horizontal split ########################## #copy&deep copy ########################## a=np.arange(4)#array([0,1,2,3]) b=a#IN NUMPY b<=>a,when a[0]:=11,b[0]turns into 11! b is a# output:Ture b=a.cpoy#only copy numbers->deep copy b is a#output False
-
PANDAS学习(1)
(大好时光,不如刷刷熊猫)#Series,一位数组,与numpy的array相类似 In [6]: s=pd.Series([1,3,6,np.nan,5,6]) In [7]: s Out[7]: 0 1.0 1 3.0 2 6.0 3 NaN 4 5.0 5 6.0 dtype: float64 #DataFrame,二维的表格型数据结构,每一个坐标轴都有自己的标签。是series的字典项。 In [19]: df=pd.DataFrame(np.random.randn(6,4),index=dates,columns=['a','b','c','d']) #index->hang suo ying ,columns->lie suoying In [20]: df Out[20]: a b c d 2016-01-01 1.083966 -1.131710 0.515652 0.837967 2016-01-02 0.950895 -0.100363 0.247957 0.753589 2016-01-03 0.370636 0.375547 -1.069627 1.738645 2016-01-04 -0.726578 1.390678 -0.309058 0.495773 2016-01-05 0.869181 -0.497488 0.550426 -0.928189 2016-01-06 1.330088 0.252316 0.272717 -1.151035 In [22]: df1=pd.DataFrame(np.arange(12).reshape((3,4))) In [23]: df1 Out[23]: 0 1 2 3 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 In [9]: df2=pd.DataFrame({'A':[1.], ...: 'B':['C']}) In [10]: df2 Out[10]: A B 0 1.0 C In [15]: df2=pd.DataFrame({'A':np.arange(4), ...: 'B':pd.Categorical(["test","train","test","train"])}) In [16]: df2 Out[16]: A B 0 0 test 1 1 train 2 2 test 3 3 train #得到DataFrame的各列数据类型 In [19]: df2.dtypes Out[19]: A int64 B category dtype: object #列索引.index In [20]: df2.index Out[20]: RangeIndex(start=0, stop=4, step=1) #行索引.column In [21]: df2.columns Out[21]: Index(['A', 'B'], dtype='object') #DataFrame的数据部分.values In [23]: c=df2.values In [24]: c Out[24]: array([[0, 'test'], [1, 'train'], [2, 'test'], [3, 'train']], dtype=object) #.describe()可以做一些number的分析,如个数、平均值、方差等。 In [25]: df2.describe() Out[25]: A count 4.000000 mean 1.500000 std 1.290994 min 0.000000 25% 0.750000 50% 1.500000 75% 2.250000 max 3.000000 #看做矩阵,.T求转置 In [26]: df2.T Out[26]: 0 1 2 3 A 0 1 2 3 B test train test train #将行或者列(axis=0)进行升或降(ascending=False)序排列 In [31]: df2.sort_index(axis=0,ascending=False) Out[31]: A B 3 3 train 2 2 test 1 1 train 0 0 test Out[33]: A B 0 0 test 1 1 train 2 2 test 3 3 train #将某个索引下的values进行排序 In [34]: df2.sort_values(by='B') Out[34]: A B 0 0 test 2 2 test 1 1 train 3 3 train
-
Sklearn.datasets探索
1.boston数据集适合于Regression训练
1 from sklearn.datasets import load_boston 2 import numpy as np 3 boston=load_boston() 4 print(boston.data.shape) (506, 13)2.Iris数据集适合于multi-classifier训练
In [12]: from sklearn.datasets import load_iris In [13]: iris=load_iris() In [14]: print(iris.data.shape) (150, 4) In [15]: print(iris.target.shape) (150,) In [16]: list(iris.target_names) Out[16]: ['setosa', 'versicolor', 'virginica'] In [20]: data,target=load_iris(return_X_y=True) In [21]: print(data.shape) (150, 4) In [22]: print(target.shape) (150,)3.digits手写数字数据集(8*8)
+用matplotlib画图并保存图像Linux由于没有GUI,所以要以下面的方式导入matplotlib.pyplot
import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as plt以matplotlib.pyplot.savefig( )函数保存图片后查看
In [1]: from sklearn.datasets import load_digits In [2]: digits=load_digits() In [3]: print(digits.data.shape) (1797, 64) In [4]: print(digits.target.shape) (1797,) In [5]: print(digits.images.shape) (1797, 8, 8) In [6]: import matplotlib In [8]: matplotlib.use('Agg') In [9]: import matplotlib.pyplot as plt In [10]: plt.matshow(digits.images[0]) Out[10]: <matplotlib.image.AxesImage at 0x7ff5dce8c518> In [11]: plt.show() /home/xxh/.local/lib/python3.7/site-packages/matplotlib/figure.py:445: UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figure. % get_backend()) In [12]: plt.savefig('/home/xxh/tf/1.png')
-
KNN
-
K-近邻是聚类的一种算法,用于数据分类。
-
KNN算法主要步骤
1)计算测试数据与各个训练数据之间距离
(一般使用欧氏距离或曼哈顿距离)
2)按距离的递增关系进行排序
3)选取距离最小的K个点
4)确定前K个点所在类别的出现频率
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类
from numpy import * import operator def createDataSet(): data=array([[1.0,1.1],[1.0,0.9],[0.0,0.1],[0,0.1]]) target=['A','A','B','B'] return data,target def classify(test,data,target,k): datasize=data.shape[0] diff=tile(test,(datasize,1))-data#tile(,):test按照(x,y)方向复制datasize和1遍 sq_diff=diff**2 sq_dis=sq_diff.sum(axis=1) dis=sq_dis**0.5 sorted_dis_index=dis.argsort()#argsort()得出索引排序结果,升序 cnt={} for i in range(k): num=target[sorted_dis_index[i]] cnt[num]=cnt.get(num,0)+1#.get() 返回cnt[num]的值(如果 cnt[num]不存在,初始化cnt[num]=0) sorted_cnt=sorted(cnt.items(),key=operator.itemgetter(1),reverse=True)#operator.itemgetter(1),获取对象的第1个域的值 return sorted_cnt[0][0] data,target=createDataSet() print(classify([1,1],data,target,3))KNN算法的缺陷
(1) 样本不均衡
采用权值的方法来改进。和该样本距离小的邻居权值大,和该样本距离大的邻居权值则相对较小
(2) 计算非常耗时。为了提高kNN搜索的效率,可以考虑使用特殊的结构存储训练数据,以减小计算距离的次数。Solution:K Dimension Tree
- kd树是是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
-
-
机器学习实战--KNN分类器
1.KNN聚类算法from numpy import * import operator def classify(test,data,target,k): datasize=data.shape[0] diff=tile(test,(datasize,1))-data#tile() sq_diff=diff**2 sq_dis=sq_diff.sum(axis=1) dis=sq_dis**0.5 sorted_dis_index=dis.argsort() cnt={} for i in range(k): num=target[sorted_dis_index[i]] cnt[num]=cnt.get(num,0)+1#get() return value of cnt[num](if cnt[num] doesn't exist cnt[num]=0) sorted_cnt=sorted(cnt.items(),key=operator.itemgetter(1),reverse=True)#itemgetter(1) return sorted_cnt[0][0] #data,target=createDataSet() #print(classify([1,1],data,target,3))2.文件转矩阵形式
def file2matrix(filename): f=open(filename) array_line=f.readlines() len_line=len(array_line) data=zeros((len_line,3)) tar=[] index=0 for line in array_line: line=line.strip() line2list=line.split('\t') data[index,:]=line2list[0:3] tar.append(int(line2list[-1])) index+=1 return data,tar dt,tar=file2matrix('datingTestSet2.txt') #print(dt) #print(tar)3.作图观察数据集两列特征值之间的关系
import matplotlib as mlp mlp.use('Agg') import matplotlib.pyplot as plt fig=plt.figure() ax=fig.add_subplot(111) ax.scatter(dt[:,1],dt[:,2],15.0*array(tar),15.0*array(tar)) #plt.savefig('/home/xxh/tf/KNN/datingTestPic.png')得到散点图:
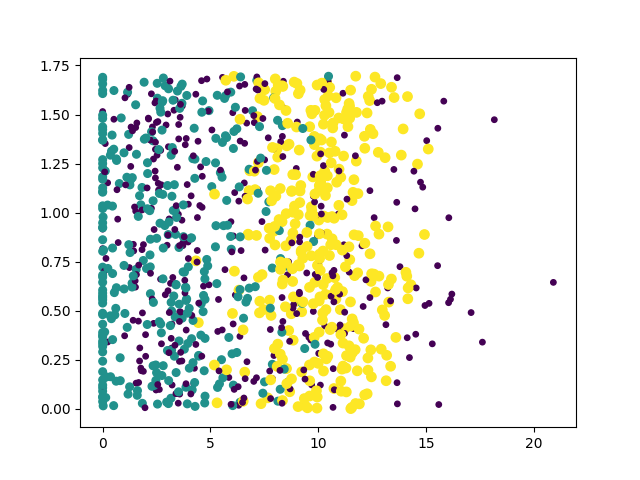
3.数据归一化
def autoNorm(dataset): minval=dataset.min(0) maxval=dataset.max(0) Range=maxval-minval normdataset=zeros(shape(dataset)) m=dataset.shape[0] normdataset=dataset-tile(minval,(m,1)) normdataset=normdataset/tile(Range,(m,1)) return normdataset,Range,minval #normdt,range,minval=autoNorm(dt) #print(normdt) #print(range) #print(minval)4.分类器测试(主函数)
def datingClassTest(): errorList=[] ratioList=[] data,target=file2matrix('datingTestSet2.txt') normdata,ranges,minval=autoNorm(data) m=normdata.shape[0] for j in range(1,100): ratioOfTrainingData=0.01*j ratioList.append(ratioOfTrainingData) numOfTrainingData=int(m*ratioOfTrainingData) errorNum=0.0 for i in range(numOfTrainingData): result=classify(normdata[i,:],normdata[numOfTrainingData:m,:],target[numOfTrainingData:m],3) if(result!=target[i]):errorNum+=1.0 errorRate=errorNum/float(numOfTrainingData) print(j,end=' ') print(errorRate) errorList.append(float(errorRate)) figure=plt.figure() axx=figure.add_subplot(111) axx.scatter(ratioList[:],errorList[:]) plt.savefig('/home/xxh/tf/KNN/KNN_TEST.png') datingClassTest()顺便画了一下测试集比例与准确率之间的关系图:
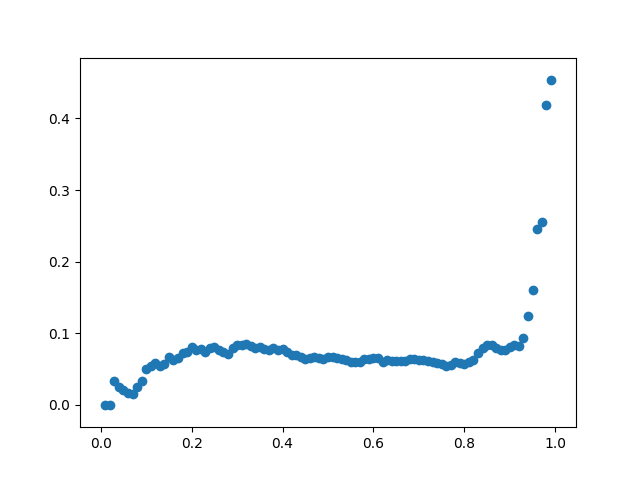
5.分类器使用def classifyPerson(): resultList=['not at all','in small doses','in large doses'] percent=float(input("percentage")) ffm=float(input("frequence")) icecream=float(input("ice-cream")) data,target=file2matrix('datingTestSet2.txt') normdata,ranges,minval=autoNorm(data) inArr=array([ffm,percent,icecream]) result=classify((inArr-minval)/ranges,normdata,target,3) print(resultList[result-1]) classifyPerson()
-
机器学习实战——KNN手写数字识别
from numpy import* from os import listdir import operator1.基于KNN的分类器
def classify(test,data,target,k): datasize=data.shape[0] diff=tile(test,(datasize,1))-data#tile(扩展行,扩展列) sq_diff=diff**2 sq_dis=sq_diff.sum(axis=1)#axis=1->求列的和;axis=0->求行的和 dis=sq_dis**0.5 sorted_dis_index=dis.argsort() cnt={} for i in range(k): num=target[sorted_dis_index[i]] cnt[num]=cnt.get(num,0)+1 sorted_cnt=sorted(cnt.items(),key=operator.itemgetter(1),reverse=True)#itemgetter(1) :0->index,1->key return sorted_cnt[0][0] #data,target=createDataSet() #print(classify([1,1],data,target,3))2.图片转向量
def img2vec(filename): returnVec=zeros((1,1024)) fr=open(filename) for i in range(32): lineStr=fr.readline() for j in range(32): returnVec[0,32*i+j]=int(lineStr[j]) return returnVec #testVector=img2vec("0_0.txt")3.手写数字识别主函数
def digitRecognition(): hwLabels=[] dataFileList=listdir('trainingDigits') len_fileList=len(dataFileList) data=zeros((len_fileList,1024)) for i in range(len_fileList): fileNameStr=dataFileList[i] fileStr=fileNameStr.split(',')[0] classNumStr=int(fileStr.split('_')[0]) hwLabels.append(classNumStr) data[i,:]=img2vec('trainingDigits/%s'% fileNameStr) testFileList=listdir('testDigits') errorCnt=0.0 len_testList=len(testFileList) for i in range(len_testList): fileNameStr=testFileList[i] fileStr=fileNameStr.split(',')[0] classNumStr=int(fileStr.split('_')[0]) testVector=img2vec('testDigits/%s'%fileNameStr) classifierResult=classify(testVector,data,hwLabels,3) print("classifier: %d, right: %d" %(classifierResult ,classNumStr)) if( classifierResult != classNumStr ): errorCnt+=1.0 errorRate=(errorCnt/float(len_testList)) #print(len_testList) print(errorCnt) print(errorRate)4.测试结果:
(好慢啊)#errorCnt:11.0 #errorRate:0.011627906976744186 #timeCost:19.133 seconds
-
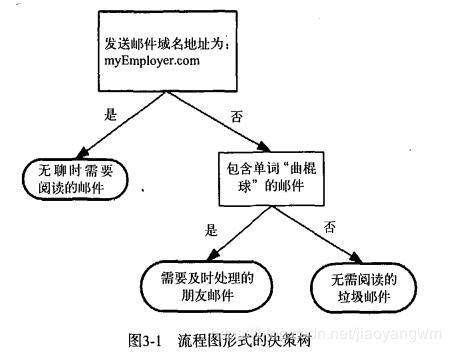
决策树
- 表示基于特征对实例进行分类的过程
- 计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据
- 数据类型:数值型(需要离散化)和标称型
- 可能会产生过度匹配的问题
信息熵
-
熵定义为信息的期望值
-
计算公式:
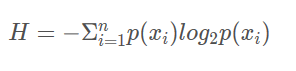
-
n为分类数目,熵越大,随机变量的不确定性就越大。
信息增益
- 划分数据集前后信息发生的变化
- 获得信息增益最高的特征就是最好的选择
基于ID3算法的决策树构造
1)从根开始,当前结点的最大信息增益的特征为作为结点特征。
2)由父特征节点建立子特征值节点,再对子结点递归地建树。
3)当所有特征的信息增益均很小或没有特征时,结束。
算法实质是一种贪心法的应用,所以得到的是局部最优,而不是全局最优。from math import log import operator def createData():#构造一个数据集&特征标签 data= [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']] datalabel=['A','B'] return data,datalabel def calcShannon(data):#计算信息熵 len_data=len(data) cnt_label={} for vec in data: target=vec[-1] if target not in cnt_label.keys(): cnt_label[target]=0 cnt_label[target]+=1 shannonVal=0.0 for key in cnt_label: p=float(cnt_label[key]/len_data) shannonVal-=p*log(p,2) return shannonVal mydat,mytar=createData() print(mydat) print(mytar) def divData(data,axis,value):#将某一特征列的向量删除掉 retData=[] for vec in data: if(vec[axis]==value): reducedVec=vec[:axis] reducedVec.extend(vec[axis+1:]) retData.append(reducedVec) return retData #print(divData(mydat,0,1)) def calcBestDiv(data):#返回信息增益最大特征的索引值 num_feature=len(data[0])-1 baseEntropy=calcShannon(data) bestInfoGain=0.0 bestRoot=-1 for i in range(num_feature): featureList=[example[i] for example in data] #print(featureList) uniqueVals=set(featureList) newEntropy=0.0 for val in uniqueVals: subData=divData(data,i,val) p=len(subData)/float(len(data)) newEntropy-=p*log(p,2) infoGain=baseEntropy-newEntropy if(infoGain>bestInfoGain): bestInfoGain=infoGain bestRoot=i return bestRoot #print(calcBestDiv(mydat)) def majorityCnt(classList):#计算出classList中出现次数最多的类标签 classCnt={} for item in classList: if item not in classCnt.keys(): classCnt[item]=0 classCnt[item]+=1 sortedClassCnt=sorted(classCnt.items(),key=operator.itemgetter(1),reverse=True) return sortedClassCnt[0][0] def createTree(data,labels):#建立决策树结构 classList=[example[-1] for example in data] #print(classList[0]) if classList.count(classList[0])==len(classList): return classList[0] if len(classList)==1: return majorityCnt(classList) bestRoot=calcBestDiv(data) bestLabel=labels[bestRoot] myTree={bestLabel:{}} del(labels[bestRoot]) featureValues=[example[bestRoot] for example in data] uniqueVals=set(featureValues) for value in uniqueVals: subLabels=labels[:] myTree[bestLabel][value]=createTree(divData(data,bestRoot,value),subLabels) return myTree def classify(inputTree,featLabels,testVec):#根据得到的决策树进行分类 firstSides=list(inputTree.keys()) firstStr=firstSides[0] secondDict = inputTree[firstStr] featIndex = featLabels.index(firstStr) key = testVec[featIndex] valueOfFeat = secondDict[key] if isinstance(valueOfFeat, dict): classLabel = classify(valueOfFeat, featLabels, testVec) else: classLabel = valueOfFeat return classLabel labels1=mytar[:] myTree=createTree(mydat,labels1) #test_part labels1=mytar[:] print(labels1) print(classify(myTree,labels1,[1,1]))debug教训:(悟已往之不谏,知来者之可追)
1.python复制列表内容要写成label=mytar[:]形式,不能写成引用形式label=mytar。
2.在Python 3.x 里面,iteritems()方法已经废除了,要用 items()方法。
-
朴素贝叶斯分类器
一、预备知识
- 先验概率:基于经验对于事件概率的估计
- 后验概率:结合已有知识,考虑事件的相关因素后,对于随机事件的概率的预估
- 贝叶斯定理:(后验概率的获得方法)

c->随机事件发生的一种情况,x->与随机事件相关的因素
二、朴素贝叶斯定理
-
假设:以自变量之间的独立(条件特征独立)性和连续变量的正态性假设为前提
-
优点:在数据较小的情况下仍然有效,可以处理多类别问题
-
缺点:对输入数据的准备方式较为敏感
-
如果有一项概率值为0会影响后面估计,所以我们对未出现的属性概率设置一个很小的值。即进行拉普拉斯修正:

-
贝叶斯决策理论核心思想:选择高概率对应的类别
三、离散属性与连续属性值的分别处理
-
离散值属性->计算每个属性取值占所有样本的数量比例
-
连续值属性->用概率密度函数
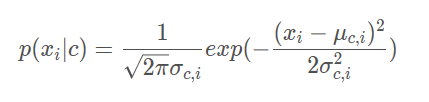
四、贝叶斯分类器训练
def loadDataSet():#载入数据集 dataList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] labelMark = [0,1,0,1,0,1] #1 is abusive, 0 not return dataList,labelMark my_dataList,my_labelMark=loadDataSet() #print(my_dataList) #print(my_labelMark) def createVocabList(data):#构造单词集合 vocaSet=set([]) for document in data: vocaSet=vocaSet|set(document) return list(vocaSet) my_vocaList=createVocabList(my_dataList) #print(my_vocaList) def setOfWords2Vec(vocaList,inputSet):#词表转词向量 returnVec=[0]*len(vocaList) for word in inputSet: if word in vocaList : returnVec[vocaList.index(word)]=1 else : print("this word is not in my vocaList") return returnVec my_returnVec=setOfWords2Vec(my_vocaList,my_dataList[0]) #print(my_returnVec) import numpy as np def trainNBC(dataMatrix,labelMark):#朴素贝叶斯分类器训练 lenDataMatrix=len(dataMatrix) numWords=len(dataMatrix[0]) pAbusive=sum(labelMark)/float(lenDataMatrix) print(pAbusive) p0Num=np.zeros(numWords) p1Num=np.zeros(numWords) p0Denom=0.0 p1Denom=0.0 for i in range (lenDataMatrix): #print("dataMatrix") #print(i) #print(dataMatrix[i]) if labelMark[i]==1: p1Num+=dataMatrix[i] p1Denom+=sum(dataMatrix[i]) else : p0Num+=dataMatrix[i] p0Denom+=sum(dataMatrix[i]) p1Vec=p1Num/p1Denom p0Vec=p0Num/p0Denom return p0Vec,p1Vec,pAbusive dataMat=[] for postinDoc in my_dataList: dataMat.append(setOfWords2Vec(my_vocaList,postinDoc)) print(dataMat) p0V,p1V,pAb=trainNBC(dataMat,my_labelMark) print(p0V) print(p1V) print(pAb)得到的单词集合在积极与消极的文章中出现的概率向量
[0. 0. 0.04166667 0.04166667 0.04166667 0.04166667 0. 0.04166667 0.04166667 0.04166667 0.04166667 0. 0.04166667 0. 0.04166667 0.04166667 0.04166667 0. 0. 0.08333333 0.04166667 0.04166667 0. 0.04166667 0. 0. 0.04166667 0.04166667 0.04166667 0. 0.125 0.04166667] [0.05263158 0.15789474 0. 0. 0. 0. 0.05263158 0. 0. 0. 0.05263158 0.05263158 0. 0.10526316 0. 0. 0. 0.05263158 0.05263158 0.05263158 0. 0. 0.05263158 0.10526316 0.05263158 0.05263158 0. 0. 0.05263158 0.05263158 0. 0. ]后续优化:考虑到贝叶斯分类器在概率计算过程中可能出现下溢出问题,解决办法是对于概率的乘积取对数