第一把Pytorch实现LSTM经验总结
-
LSTM模型简介
整体认识:
- 下图是LSTM模型的基本“细胞”,在处理一个句子时,每个单词都对应一个“细胞”。
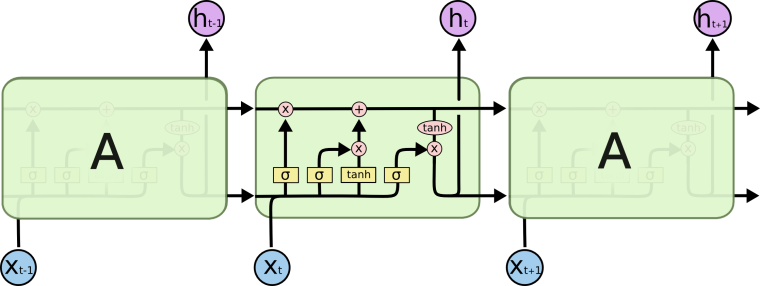

具体意义:
- 贯穿
和 的一条线中包含的信息是连贯的全文/句中蕴含的信息,可以理解为主干内容。
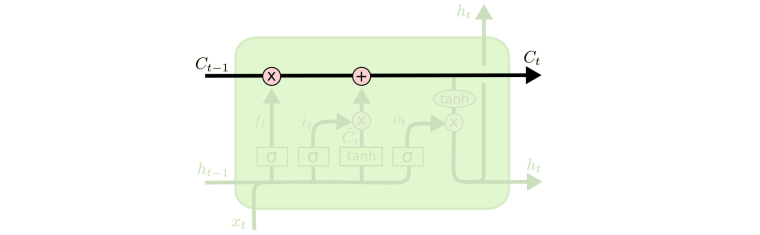
- LSTM 和普通 RNN 相比, 多出了三个控制器. (输入控制, 输出控制, 忘记控制)
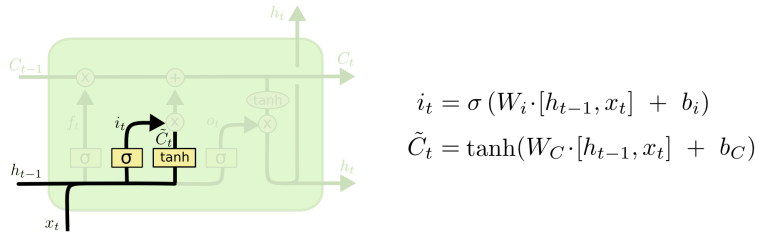
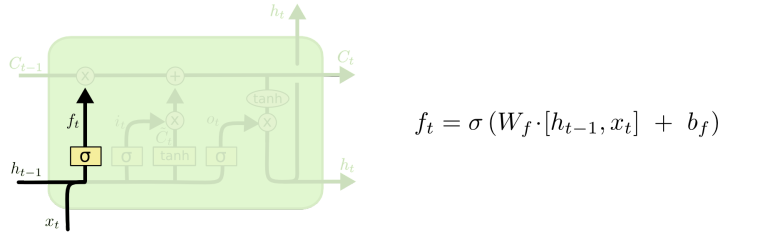
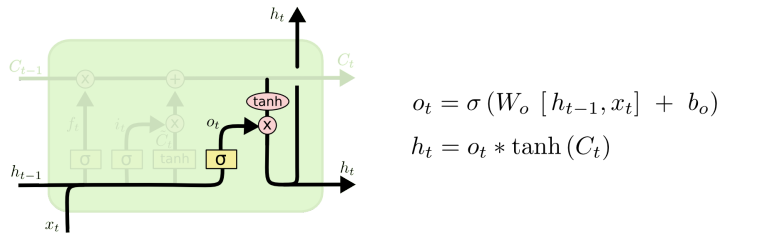
- 更详细的内容请参见:LSTM始祖级博客
- LSTM有两种 Input->Output 模式,一种是一对一,一种是多对一,如下图:
{% asset_img LSTM_many_to_one_many_to_many.jpg LSTM Paterns%}
其中,这里的“多”和“一”指的是输入和输出节点。输入节点在我们这个例子中意味着一句话的几个单词,每个单词都会输出一个hidden层的TensorFlow,而如果我们把每个Tensor都考虑再后续的层中,比如在给句子中的每个单词标注词性的时候,那么就是“多”个单词 -> “多”个输出(打上的标签);而像是句子分类情况下,就是“多”个单词 -> “一”个输出(句子的具体分类)。
采坑笔记(实践)
-
送入DataLoader中的数据一定要是numpy数组,不能是list
-
进入DataLoader中的数据如果有好几层,必须保证每一层都是list不能是numpy。如一个三层数组,最内层inner是np.array,则要做的操作是:np.array(list[list[list(inner), …],…]),否则会报各种奇怪的错误
-
计算loss的criterion中的各个output、label等必须是autograd.Variable变量而不是torch.tensor类型
-
nn.CrossEntropyLoss(output, labels)中的labels的类型必须是torch.LongTensor而不是torch.FloatTensor
-
读取数据最好还是老老实实用Dataloader,否则还是同样的,数据格式可能会出意想不到的错误
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class Beibei(Dataset):
def init(self, trainData, train_num, test_num, train=True):
self.train = train
self.train_num = train_num
self.test_num = test_num
if self.train:
self.train_data = trainData[:train_num]
else:
self.test_data = trainData[train_num:train_num+test_num]def __getitem__(self, index): if self.train: sentence, label = self.train_data[index] else: sentence, label = self.test_data[index] send2word = get_wordvecs(sentence=sentence) return send2word, label def __len__(self): if self.train: return self.train_num else: return self.test_num -
注意在一个cell里面定义了函数,有时候会顺便再同一个cell里面定义了一把随意的输入数据测试一把,但是千万记住不要把函数的输入形参搞成了你定义的那个测试量,否则会在暗地里炸的体无完肤
-
数据需要处理的部分最好放在Dataset的类里面返回值处处理,这样会节省空间和内存。如果把这些预处理提前一次性做了,尤其是Word2Vec这种操作,会吃掉大量内存
-
loss.backward(retain_variables=True)#retain_graph=True)的作用:
After loss.backward you cannot do another loss.backward unless retain_variables is true.
In plain words, the backward proc will consume the intermediate saved Tensors (Variables) used for backpropagation unless you explicitly tell PyTorch to retain them.- 由上述解答可知,retain_variables=True语句确保了用于计算后向传播的中间变量不会在计算中被销毁。
- 又由下可知,目前最好使用的方式是retain_graph=True
It is essentially the same, retain_variables argument has been deprecated in favor of retain_graph.
- 当batch参数放在第一个时,欲得到一个batch中每个句子的预测中最相近的一个值和其对应的序号:
values, indices = torch.max(tensor, 0) - LSTM在pytorch中的输入输出信息的顺序是:(sentence,batch,word2vec)这样不太自然,用下列写法可以更正至(batch,sentence,word2vec):
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=False)
我的代码实现:
Many to One
import torch import torch.nn as nn import torch.nn.functional as F import torch.autograd from torch.autograd import Variable import numpy as np import random import torch.nn.init as init torch.manual_seed(233) random.seed(233) np.random.seed(233) EMBEDDING_DIM = 200 HIDDEN_DIM = 640 BATCH_SIZE = 256 """ Neural Networks model : LSTM """ class LSTM(nn.Module): def __init__(self, embedding_dim, hidden_dim, tagset_size): super(LSTM, self).__init__() self.hidden_dim = hidden_dim self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=False) self.hidden2tag = nn.Linear(hidden_dim, tagset_size) self.hidden = self.init_hidden() def init_hidden(self): return (Variable(torch.zeros(1, 20, self.hidden_dim)), Variable(torch.zeros(1, 20, self.hidden_dim))) def forward(self, wordvecs): lstm_out, self.hidden = self.lstm(wordvecs, self.hidden) tag_space = self.hidden2tag(lstm_out[:,-1,:]) tag_scores = F.softmax(tag_space) self.hidden = self.init_hidden() return tag_scoresMany to many
import torch import torch.nn as nn import torch.nn.functional as F import torch.autograd from torch.autograd import Variable import numpy as np import random import torch.nn.init as init torch.manual_seed(233) random.seed(233) np.random.seed(233) EMBEDDING_DIM = 200 HIDDEN_DIM = 640 BATCH_SIZE = 256 """ Neural Networks model : LSTM """ class LSTM(nn.Module): def __init__(self, embedding_dim, hidden_dim, tagset_size): super(LSTM, self).__init__() self.hidden_dim = hidden_dim self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=False) self.hidden2tag = nn.Linear(hidden_dim*20, tagset_size) self.hidden = self.init_hidden() def init_hidden(self): return (Variable(torch.zeros(1, 20, self.hidden_dim)), Variable(torch.zeros(1, 20, self.hidden_dim))) def forward(self, wordvecs): lstm_out, self.hidden = self.lstm(wordvecs, self.hidden) tag_space = self.hidden2tag(lstm_out.view(-1, self.hidden_dim*20)) tag_scores = F.softmax(tag_space) self.hidden = self.init_hidden() return tag_scores两者最大的差别在于在lstm的输出之后是取output[:,-1,:],即截取一句话的最后一个节点的Hidden层的输出(Many to One),还是要所有的输出,即output.view(-1, self.hidden_dim*20),把batch的维度和sentence的维度打平,把两维降到一维。
- 下图是LSTM模型的基本“细胞”,在处理一个句子时,每个单词都对应一个“细胞”。
-
many to one的lstm是不是有个地方有问题?
在forward函数里面,取lstm最后一个节点的输出时,是不是应该是[-1, : , : ] ???
output 的 shape 应该是(seq_len, batch, hidden_size)?
-