从最优化角度分析Focal loss
-
关于softmax可以从概率角度思考为概率分布的相似的的比较,但是这位大神【从最优化的角度看待Softmax损失函数】 https://zhuanlan.zhihu.com/p/45014864 从最优化理论重新分析了softmax函数,也非常棒。
于是我尝试用这个理论分析了Focal loss,结果和focalloss的提出是一致的。
focal loss的提出背景
让我们首先了解类别不平衡数据集的一般的处理方法,然后再学习 focal loss 的解决方式。
在多分类问题中,类别平衡的数据集的目标标签是均匀分布的。若某类目标的样本相比其他类在数量上占据极大优势,则可以将该数据集视为不平衡的数据集。这种不平衡将导致两个问题:
- 训练效率低下,因为大多数样本都是简单的目标,这些样本在训练中提供给模型不太有用的信息;
- 简单的样本数量上的极大优势会搞垮训练,使模型性能退化。一种常见的解决方案是执行某种形式的困难样本挖掘,实现方式就是在训练时选取困难样本 或 使用更复杂的采样,以及重新对样本加权等方案。
对具体图像分类问题,对数据增强技术方案变更,以便为样本不足的类创建增强的数据。
Focal loss旨在通过降低简单样本的权重来解决类别不平衡问题,这样即使简单样本的数量很大,但它们对总损失的贡献却很小。也就是说,该函数侧重于用困难样本稀疏的数据集来训练。
Focal loss介绍
Focal loss是在交叉熵损失函数基础上进行的修改 :
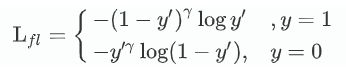
首先在原有的基础上加了一个因子,其中gamma>0使得减少易分类样本的损失。使得更关注于困难的、错分的样本。此外,加入平衡因子alpha,用来平衡正负样本本身的比例不均:文中alpha取0.25,即正样本要比负样本占比小,这是因为负例易分。
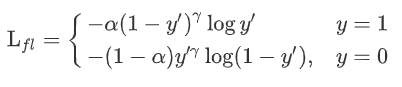
alpha的引入只用来解决类别平衡问题,gamma的引入用于解决困难样本问题。从优化角度分析
首先,分析几个常见函数的smooth版本
-
max函数
max函数的一种近似是LogSumExp函数
越大,效果越好 -
min函数
即LSE的负数版本
-
relu函数
将focal loss转化为多分类形式
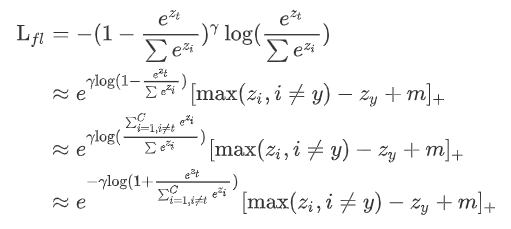
到目前为止的的推理是在基于对softmax的理解的基础上,继续推导的结果。接下来只对左边的focal loss独有的部分推导。
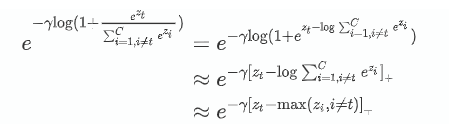
即focal loss可以写为:
gamma为0时与交叉熵一致,当gamma大于1时,相当于在loss前乘以了一个系数。这个系数的值可以小于1也可以约等于1,表示对loss的惩罚增加还是减少。
当
时,表明正确类的得分已经比其他类的最大得分大了, 的值小于1,可以减少后面交叉熵损失函数的值。 当
时,由于使用了 函数,所以 的值约等于1,之后交叉熵的损失函数不变。 这与focalloss的函数图像也是吻合的:
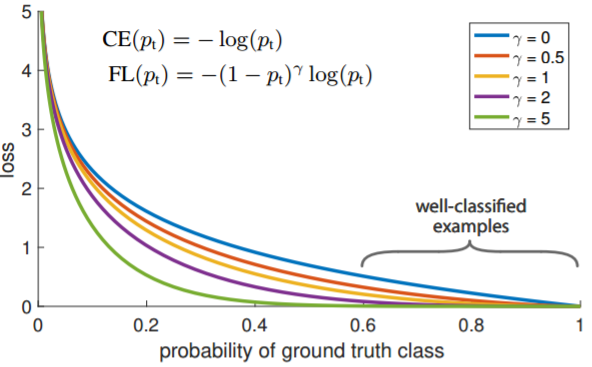
focalloss的平衡问题
由于cross entropy回传loss时,正负类得到的梯度绝对值都是1,所以我们认为cross entropy是平衡的损失函数。
对于focalloss求导:
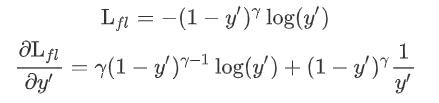
这里带入值求解 a = [0.3,0.7],则y'=[0.40131234, 0.59868766],y=[1,0],取gamma=2
求对z0的梯度:
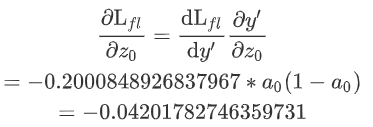
求对z1的梯度:
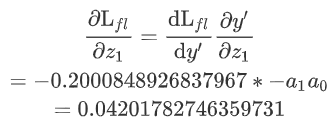
这是由于softmax函数的梯度本身是均衡的:
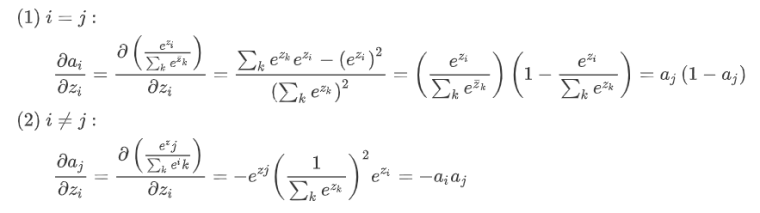
而梯度的和为0,保证了只要是以softmax为预测层的loss都是均衡的。