C++常用数据结构使用总结
-
四、list(双向链表)[双向迭代器]
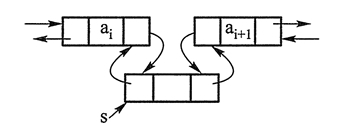
list 是顺序容器的一种。list 是一个双向链表。使用 list 需要包含头文件 list。双向链表的每个元素中都有一个指针指向后一个元素,也有一个指针指向前一个元素。

在 list 容器中,在已经定位到要增删元素的位置的情况下,增删元素能在常数时间内完成。
1、初始化
#include <list> list<T>(); //一个空的列表 list<T>(int Size); //设置列表个数 list<T>(int Size,T value); //设置列表个数和初值 list<T>(l.begin(),l.end()); //复制另一个列表2、增:
push_front(T value); //头部加入 push_back(T value); //尾部加入 //迭代器 list<T>::iterator it; insert(list<T>::iterator it,T value);//在迭代器指向的元素前面插入 insert(list<T>::iterator it,int n ,T value);//在迭代器指向的元素前面插入n个value insert(list<T>::iterator it,l.begin(),l.end());//在迭代器指向的元素前面插入另一个list的内容3、删:
pop_front();//删除第一个元素 pop_back(); //删除最后一个元素 clear(); //清空 //迭代器 list<T>::iterator it; iterator erase(iterator it):删除向量中迭代器指向元素 iterator erase(iterator first,iterator last):删除向量中[first,last)中元素4、查:
T front(); //返回第一个元素 T back(); //返回最后一个元素 find(l.begin(), l.end(), key) != l.end()//根据value查找值,如果找不到会返回l.end()的值 //遍历 for (auto &i : v){i;} //迭代器 list<T>::iterator it; *it; //直接访问迭代器指向的元素 ++it; //双向迭代器特点 iterator begin(); //返回向量头指针,指向第一个元素 iterator end(); //返回向量尾指针,指向向量最后一个元素的下一个位置 //遍历 for (ist<int>::iterator it = l.begin(); it != l.end(); ++it) {tempNum = *it;} //反向遍历 for (list<int>::reverse_iterator j = l.rbegin(); j != l.rend(); ++j) {tempNum = *it;}5、改:
assign(int n,T x) //将容器全部内容改为n个x swap(list<T>); //交换两个同类型向量的数据 //迭代器 list<T>::iterator it; *it = (T)value; assign(l.begin(),l.end()) //容器中[first,last)中元素设置成当前向量元素6、其他方法:
empty(); //是否为空 size(); //返回元素个数 resize(int n); //将容器的元素个数改为只容纳n个,超过的将删除 resize(int n,T val); //将容器的元素个数改为只容纳n个,超过的将删除,不够的以val的值来补全 max_size(); //返回最大可允许的list元素数量值(768614336404564650)
-
五、stack(基于deque)[不支持迭代器]
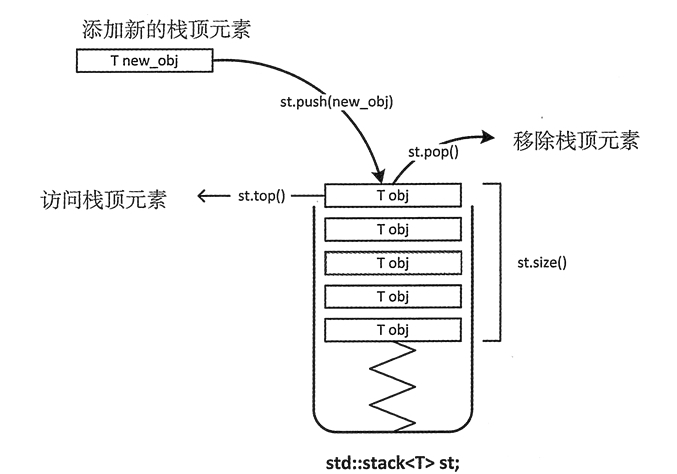
stack<T>容器适配器中的数据是以 LIFO 的方式组织的。只能访问 stack 顶部的元素;只有在移除 stack 顶部的元素后,才能访问下方的元素。
1、初始化
#include <stack> stack<T>(); //一个空的栈 stack<T>(stack<T> s); //复制2、增:
push(T value); //加入栈顶的元素3、删:
pop(); //删除栈顶的元素4、查:
top(); //返回栈顶的元素5、改:
swap(stack<T>); //交换两个同类型向量的数据6、其他方法:
empty(); //是否为空 size(); //返回元素个数
-
六、queue(基于deque)[不支持迭代器]
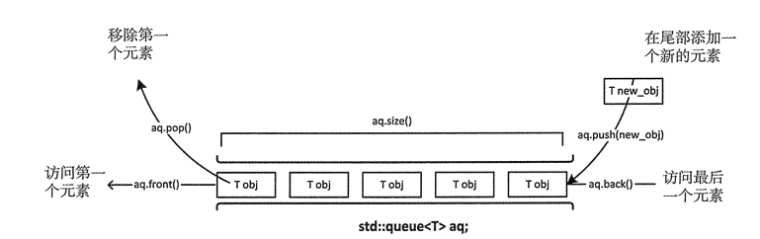
只能访问 queue<T> 容器适配器的第一个和最后一个元素。只能在容器的末尾添加新元素,只能从头部移除元素
对于任何需要用 FIFO 准则处理的序列来说,使用 queue 容器适配器都是好的选择
1、初始化
#include <queue> queue<T>(); //一个空的队列 queue<T>(queue<T> q); //复制2、增:
push(T value); //尾部加入元素3、删:
pop(); //删除第一个元素4、查:
front(); //返回第一个元素 back(); //返回最后的元素5、改:
swap(queue<T>); //交换两个同类型向量的数据6、其他方法:
empty(); //是否为空 size(); //返回元素个数
-
七、priority_queue(基于vector)[不支持迭代器]
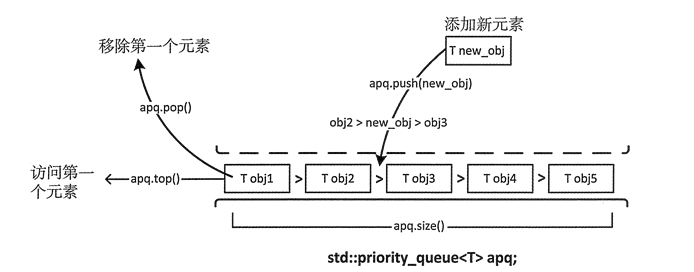
priority_queue 容器适配器定义了一个元素有序排列的队列。默认队列头部的元素优先级最高。因为它是一个队列,所以只能访问第一个元素,这也意味着优先级最高的元素总是第一个被处理。但是如何定义“优先级”完全取决于我们自己。
1、初始化
#include <queue> priority_queue<T, Container, Functional>(); //T 就是数据类型,Container 就是容器类型(Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。STL里面默认用的是vector),Functional 就是比较的方式。 priority_queue<T, Container, Functional>(priority_queue<T, Container, Functional> pq);//复制 //升序队列,小顶堆 priority_queue <T,vector<T>,greater<T>> q; //降序队列,大顶堆 priority_queue <T,vector<T>,less<T>> q; //greater和less是std实现的两个仿函数(就是使一个类的使用看上去像一个函数。其实现就是类中实现一个operator(),这个类就有了类似函数的行为,就是一个仿函数类了)需要#include <functional>2、增:
push(T value); //加入元素(并排序)3、删:
pop(); //删除第一个元素4、查:
top(); //返回第一个元素5、改:
swap(priority_queue<T>); //交换两个同类型向量的数据6、其他方法:
empty(); //是否为空 size(); //返回元素个数
-
八、map(基于红黑树)[双向迭代器]
map是STL的一个关联容器,它提供一对一的hash。第一个可以称为关键字(key),每个关键字只能在map中出现一次;第二个可能称为该关键字的值(value);
map內部的实现自建一颗红黑树,这颗树具有对数据自动排序的功能。在map内部所有的数据都是有序的

1、初始化
#include <map> map<T1,T2>(); //一个空的map map<T1, T2>(m.begin(),m.end()); //复制另一个map map<T1, T2> m = { {T1 value1, T2 value2},{T1 value1, T2 value2},...,}//直接初始化2、增:
//使用pair插入 注意map中有这个关键字时,insert操作是不能在插入数据的 insert(make_pair<T1, T2>(T1 value1,T2 value2); insert(pair<T1, T2>(T1 value1,T2 value2); //使用value_type插入 注意map中有这个关键字时,insert操作是不能在插入数据的 insert(map<T1, T2>::value_type (T1 value1, T2 value2)); //用"array"方式插入,可以直接覆盖 m[T1 value1] = T2 value2;3、删:
erase(T1 value); //如果刪除了會返回1,否則返回0 clear(); //清空 //迭代器 map<T1,T2>::iterator it; iterator erase(iterator it):删除向量中迭代器指向元素 iterator erase(iterator first,iterator last):删除向量中[first,last)中元素4、查:
find(key) != m.end(); //根据value查找值,如果找不到会返回l.end()的值 at(T1 value1); //返回的是参数键对应的对象。如果这个键不存在,就会拋出 out_of_range 异常 //遍历 for (auto &i : v){i.first;i.second} //迭代器 map<T1,T2>::iterator it; it->first; //访问key it->second; //访问value ++it; //双向迭代器特点 iterator begin(); //返回向量头指针,指向第一个元素 iterator end(); //返回向量尾指针,指向向量最后一个元素的下一个位置 //遍历 for (map<T1,T2>::iterator it = m.begin(); it != m.end(); ++it) {key = it->first;value = it->second;} //反向遍历 for (map<T1,T2>::reverse_iterator j = m.rbegin(); j != m.rend(); ++j) {key = it->first;value = it->second;}5、改:
swap(map<T1,T2>) //交换两个同类型向量的数据 //使用array方式直接修改 m[T1 value1] = T2 value2; //迭代器 map<T1,T2>::iterator it; it->second = T2 alue;6、其他方法:
empty(); //是否为空 count(T1 value1); //返回指定元素出现的次数 size(); //返回元素个数 max_size(); //返回最大可允许的map元素数量值(256204778801521550)
-
九、multimap(基于红黑树)[双向迭代器]
multimap容器:与map容器类似,区别只在于multimap容器可以保存键值相同的元素。
1、初始化
#include <map> multimap<T1,T2>(); //一个空的multimap multimap<T1, T2>(m.begin(),m.end()); //复制另一个multimap multimap<T1, T2> m = { {T1 value1, T2 value2},{T1 value1, T2 value2},...,}//直接初始化2、增:
//multimap 容器的成员函数 insert() 可以插入一个或多个元素,而且插入总是成功。 //使用pair插入 insert(make_pair<T1, T2>(T1 value1,T2 value2); insert(pair<T1, T2>(T1 value1,T2 value2); //使用value_type插入 insert(multimap<T1, T2>::value_type (T1 value1, T2 value2));3、删:
erase(T1 value); //如果刪除了會返回1,否則返回0 clear(); //清空 //迭代器 multimap<T1,T2>::iterator it; iterator erase(iterator it):删除向量中迭代器指向元素 iterator erase(iterator first,iterator last):删除向量中[first,last)中元素4、查:
find(key) != m.end(); //根据value查找值,如果找不到会返回l.end()的值 //遍历 for (auto &i : v){i.first;i.second} //迭代器 multimap<T1,T2>::iterator it; it->first; //访问key it->second; //访问value ++it; //双向迭代器特点 iterator begin(); //返回向量头指针,指向第一个元素 iterator end(); //返回向量尾指针,指向向量最后一个元素的下一个位置 //遍历 for (multimap<T1,T2>::iterator it = m.begin(); it != m.end(); ++it) {key = it->first;value = it->second;} //反向遍历 for (multimap<T1,T2>::reverse_iterator j = m.rbegin(); j != m.rend(); ++j) {key = it->first;value = it->second;}5、改:
swap(map<T1,T2>) //交换两个同类型向量的数据 //迭代器 multimap<T1,T2>::iterator it; it->second = T2 alue;6、其他方法:
empty(); //是否为空 count(T1 value1); //返回指定元素出现的次数 size(); //返回元素个数 max_size(); //返回最大可允许的map元素数量值(256204778801521550)
-
十、unordered_map(基于hash表)[正向迭代器]
unordered_map 包含的是有唯一键的键/值对元素。容器中的元素不是有序的。元素的位置由键的哈希值确定,因而必须有一个适用于键类型的哈希函数。如果用类对象作为键,需要为它定义一个实现了哈希函数的函数对象。如果键是STL 提供的类型,通过特例化 hash<T>,容器可以生成这种键对应的哈希函数

1、初始化
#include <unordered_map > unordered_map <T1,T2>(); //一个空的map unordered_map <T1, T2>(m.begin(),m.end()); //复制另一个map unordered_map <T1, T2> m = { {T1 value1, T2 value2},{T1 value1, T2 value2},...,}//直接初始化2、增:
//使用pair插入 注意map中有这个关键字时,insert操作是不能在插入数据的 insert(make_pair<T1, T2>(T1 value1,T2 value2); insert(pair<T1, T2>(T1 value1,T2 value2); //使用value_type插入 注意map中有这个关键字时,insert操作是不能在插入数据的 insert(unordered_map<T1, T2>::value_type (T1 value1, T2 value2)); //用"array"方式插入,可以直接覆盖 m[T1 value1] = T2 value2;3、删:
erase(T1 value); //如果刪除了會返回1,否則返回0 clear(); //清空 //迭代器 unordered_map<T1,T2>::iterator it; iterator erase(iterator it):删除向量中迭代器指向元素 iterator erase(iterator first,iterator last):删除向量中[first,last)中元素4、查:
find(key) != m.end(); //根据value查找值,如果找不到会返回l.end()的值 at(T1 value1); //返回的是参数键对应的对象。如果这个键不存在,就会拋出 out_of_range 异常 //遍历 for (auto &i : v){i.first;i.second} //迭代器 unordered_map<T1,T2>::iterator it; it->first; //访问key it->second; //访问value ++it; //双向迭代器特点 iterator begin(); //返回向量头指针,指向第一个元素 iterator end(); //返回向量尾指针,指向向量最后一个元素的下一个位置 //遍历 for (unordered_map<T1,T2>::iterator it = m.begin(); it != m.end(); ++it) {key = it->first;value = it->second;}5、改:
swap(unordered_map<T1,T2>) //交换两个同类型向量的数据 //使用array方式直接修改 m[T1 value1] = T2 value2; //迭代器 unordered_map<T1,T2>::iterator it; it->second = T2 alue;6、其他方法:
empty(); //是否为空 count(T1 value1); //返回指定元素出现的次数 size(); //返回元素个数 max_size(); //返回最大可允许的map元素数量值(256204778801521550)
-
十一、set(基于红黑树)[双向迭代器]
set为集合。除了没有单独的键,set 容器和 map 容器很相似。
1、初始化
#include <set> set<T>(); //一个空的map set<T>(s.begin(),s.end()); //复制另一个map set<T> s = { T value,T value,...,}//直接初始化2、增:
//无法重复插入 insert(T value); //插入元素 emplace(T value); //插入元素,会返回一个 pair<iterator,bool> 对象3、删:
erase(T value); //如果刪除了會返回1,否則返回0 clear(); //清空 //迭代器 set<T>::iterator it; iterator erase(iterator it):删除向量中迭代器指向元素 iterator erase(iterator first,iterator last):删除向量中[first,last)中元素4、查:
find(key) != s.end(); //根据value查找值,如果找不到会返回l.end()的值 //遍历 for (auto &i : s){i} //迭代器 set<T>::iterator it; *it //直接访问迭代器指向的元素 ++it; //双向迭代器特点 iterator begin(); //返回向量头指针,指向第一个元素 iterator end(); //返回向量尾指针,指向向量最后一个元素的下一个位置 //遍历 for (set<T>::iterator it = s.begin(); it != s.end(); ++it) {temp = *it;} //反向遍历 for (set<T>::reverse_iterator j = s.rbegin(); j != s.rend(); ++j) {temp = *it;}5、改:
swap(set<T>) //交换两个同类型向量的数据6、其他方法:
empty(); //是否为空 count(T value); //返回指定元素出现的次数 size(); //返回元素个数 max_size(); //返回最大可允许的set元素数量值
-
十二、multiset(基于红黑树)[双向迭代器]
multiset容器:与set容器类似,区别只在于multiset容器可以保存相同的元素。
1、初始化
#include <set> multiset<T>(); //一个空的map multiset<T>(s.begin(),s.end()); //复制另一个map multiset<T> s = { T value,T value,...,}//直接初始化2、增:
//总是能够成功 insert(T value); //插入元素 emplace(T value); //插入元素,会返回一个 pair<iterator,bool> 对象3、删:
erase(T value); //如果刪除了會返回1,否則返回0 clear(); //清空 //迭代器 multiset<T>::iterator it; iterator erase(iterator it):删除向量中迭代器指向元素 iterator erase(iterator first,iterator last):删除向量中[first,last)中元素4、查:
find(key) != s.end(); //根据value查找值,如果找不到会返回l.end()的值 //遍历 for (auto &i : s){i} //迭代器 set<T>::iterator it; *it //直接访问迭代器指向的元素 ++it; //双向迭代器特点 iterator begin(); //返回向量头指针,指向第一个元素 iterator end(); //返回向量尾指针,指向向量最后一个元素的下一个位置 //遍历 for (multiset<T>::iterator it = s.begin(); it != s.end(); ++it) {temp = *it;} //反向遍历 for (multiset<T>::reverse_iterator j = s.rbegin(); j != s.rend(); ++j) {temp = *it;}5、改:
swap(multiset<T>) //交换两个同类型向量的数据6、其他方法:
empty(); //是否为空 count(T value); //返回指定元素出现的次数 size(); //返回元素个数 max_size(); //返回最大可允许的multiset元素数量值
-
十三、unordered_set(基于hash表)[正向迭代器]
占位
(其实可以直接参考unordered_map和set的方法直接用)
-
十四、string
占位
有点懒得整理了:http://c.biancheng.net/view/400.html
-
参考资料
大多数都从这里整理的:C++笔记 http://c.biancheng.net/skill/cpp/
等什么时候想起来再把后两个补了(摸了)
-
(为什么会有人把目录放最后
一、迭代器(针对容器的一种指针)
二、VECTOR(简单数组)[随机访问迭代器]
三、DEQUE(分段数组)[随机访问迭代器]
四、LIST(双向链表)[双向迭代器]
五、STACK(基于DEQUE)[不支持迭代器]
六、QUEUE(基于DEQUE)[不支持迭代器]
七、PRIORITY_QUEUE(基于VECTOR)[不支持迭代器]
八、MAP(基于红黑树)[双向迭代器]
九、MULTIMAP(基于红黑树)[双向迭代器]
十、UNORDERED_MAP(基于HASH表)[正向迭代器]
十一、SET(基于红黑树)[双向迭代器]
十二、MULTISET(基于红黑树)[双向迭代器]
十三、UNORDERED_SET(基于HASH表)[正向迭代器]
十四、STRING