HRNet: Deep High-Resolution Representation Learning for Visual Recognition(IEEE T-PAMI 2020)
-
动机与挑战
相较其他网络
- high-to-low resolution convolutions:逐层减小特征图的spatial size,如下图(a)
- 对于实例分割、目标检测、姿态估计等position-sensitive tasks,需要再从低分辨率表征中恢复出高分辨率表征,如下图(b)

Fig. 1. The structure of recovering high resolution from low resolution. (a) A low-resolution representation learning subnetwork (such as VGGNet [126], ResNet [54]), which is formed by connecting high-to-low convolutions in series. (b) A high-resolution representation recovering subnetwork, which is formed by connecting low-to-high convolutions in series.
-
HRNet
- 全过程中保持高分辨率表征,而不用从低分辨率表征中恢复高分辨率表征
- 并行多分辨率卷积
- 多分辨率融合:用低分辨率表征去boost高分辨率表征
- 更强的语义、更精准的空间信息

-
网络结构
HRNet 的网络创新包括如下 3 点:
- 多分辨率卷积 Parallel Multi-Resolution Convolutions
- 多分辨率融合 Repeated Multi-Resolution Fusions
- Representation Head
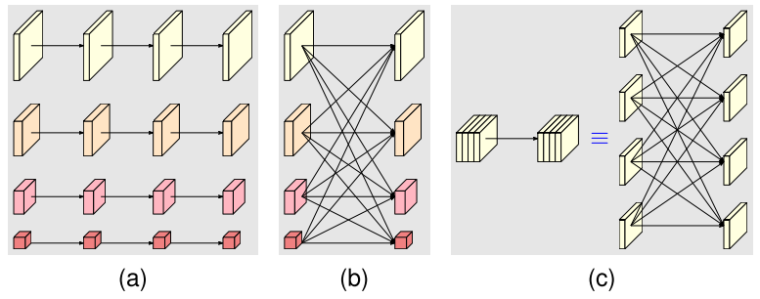
Fig. 5. (a) Multi-resolution parallel convolution, (b) multi-resolution fusion. (c) A normal convolution (left) is equivalent to fully-connected multi-branch convolutions (right).
-
2. Repeated Multi-Resolution Fusions
在 HRNet 不同尺度特征的前向传播中,多分辨率融合起到了不断用小尺度语义信息和大尺度特征提取的相互提升作用。
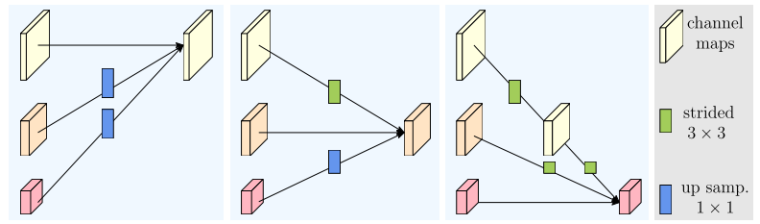
Fig. 3. Illustrating how the fusion module aggregates the information for high, medium and low resolutions from left to right, respectively. Right legend: strided 3 × 3 = stride-2 3 × 3 convolution, up samp. 1 × 1 = bilinear upsampling followed by a 1 × 1 convolution.
同时这一模块的实现也较为简单。如上图所示,通过对相对小尺度特征进行上采样、和对相对大尺度特征进行 3x3 卷积,使得各自特征维度匹配。
-
3. Representation Head
为应对计算机视觉的不同任务,HRNet 使用了不同的 representation head 进行输出,分别对应 HRNetV1、HRNetV2、HRNetV2p。
在实验中,HRNetV1 用于姿态估计任务;而 HRNetV2 和 HRNetV2p 分别用于语义分割、目标检测和实力分割。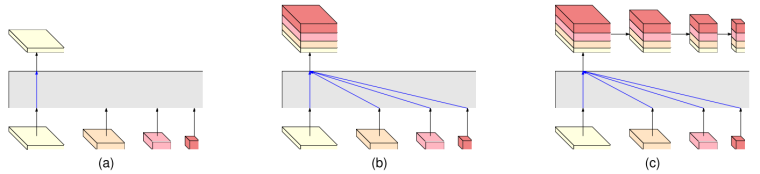
Fig. 4. (a) HRNetV1: only output the representation from the high-resolution convolution stream. (b) HRNetV2: Concatenate the (upsampled) representations that are from all the resolutions (the subsequent 1 × 1 convolution is not shown for clarity). (c) HRNetV2p: form a feature pyramid from the representation by HRNetV2. The four-resolution representations at the bottom in each sub-figure are outputted from the network in Figure 2, and the gray box indicates how the output representation is obtained from the input four-resolution representations.
-
4. 具体实现
HRNet 根据不同尺度特征引入的顺序将网络分为了多个 stage。在最初的版本中,1st stage 包括 4 个由 bottleneck + conv3x3 构成的 Residual Unit;而在2nd、3rd、4th stage 中则都由 4 个 Conv3x3 + BN + RELU 构成的 Modularized Block 构成。
-
实验
姿态估计
**HRNetV1:**只输出高分辨率表征。在COCO上达到SOTA
语义分割
**HRNetV2:**输出所有分辨率结合的表征。在PASCAL-Context、Cityscapes、LIP上达到SOTA
目标检测和实例分割
**HRNetV2p:**在小目标上获得巨大提升