TOC
- 什么是 / 为什么是 “强化学习”?
- 线性二次调节器(LQR)
- 了解世界
- 独当一面
什么是 / 为什么是 “强化学习”?
What? And why?
maximize r
问题解释:假设你在玩 地球OL,如何成为人生赢家?
- 我们受现实制约:s∈S
- 而且时常我们无法得知事情的真相:o⊂s or o∼s
- 我们能做的事情有限:a∈A
- 我们心里对自己有数:s,a,s′⇒τ,br
- 我们能与环境互动! s,a⇒π,ps′
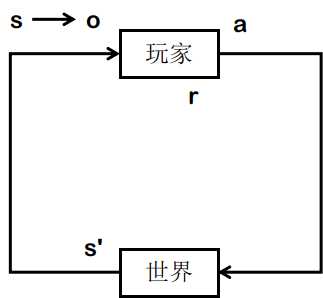
- 类似于人类的学习机制
- “如果好吃你就多吃点”:if r⋆↑, then ↑p(s∣r≈r⋆)
- 一种可能的达成 GAI 的途径
线性二次调节器
Linear Quadratic Regulator
- 最优设计算法
- 世界模型:xt+1=f(xt,ut)=Ft[xt ut]+ft
允许包含高阶项 x˙,x¨,⋯
- 评判标准:c(xt,ut)=21[xt ut]TCt[xt ut]+[xt ut]Tct
- 目标:minτ∑c
- 注意对 x 递归带入 f

- iterative LQR:如果不能线性,就用泰勒展开
了解世界
Learn about the world
Version 1.0
- 采集数据 D=(x,u,x′)i
- 从数据 D 学习世界模型 f←minf∑i∥f(xi,ui)−x′∥2
Version 1.0 出了什么问题?
想想巴甫洛夫的狗...
- D0,:=(ring bell and food,⋯)
- fD0=(bell=food)
- πD0=(if bell, then go to front door for food)
被训练集教坏的模型!
- D 并不能代表 S,因为 xD⊂S
Version 2.0 - DAgger
Data Aggregation
- 初始化 π0
- 跑 π0 采集数据 D
- 从 D 学习 f
- 更新 π 为 πi
- 跑 πi 采集数据 Di
- [DAgger] D:=D∪Di
- 回到步骤 3,直至收敛
独当一面
Be the master of yourself
Markov Decision Process
π(s):=argamaxs′∑Pa(s,s′)(Ra(s,s′)+γV(s′))
V(s):=s′∑Pπ(s)(Rπ(s)(s,s′)+γV(s′))
from WikiPedia
评价方法
- 策略表现:η(π)=E[∑tγtrt]
- 状态评分:Vπ(s)=E[∑tγtrt∣s0=s]
- 状态-动作评分:Qπ(s,a)=E[∑tγtrt∣s0=s,a0=a]
γ 为衰减因子
策略梯度
Prolicy Gradient
maximize E[R∣πθ]
基本思路
- 让好的轨迹更容易发生
- 让好的动作更容易发生
- 改善不好的动作
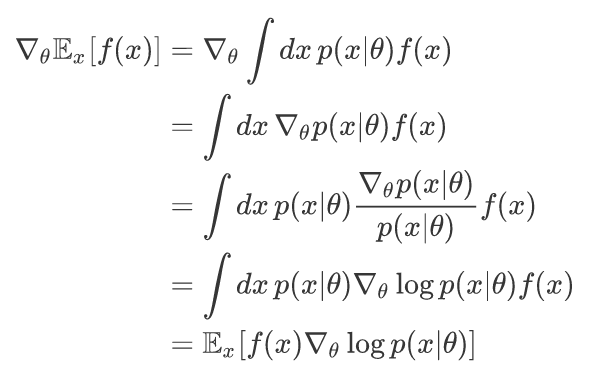
将 f(x) 替换为我们需要的任务目标
g^:=∇θEτ[R(τ)]=Eτ[∇θlogp(τ∣θ)R(τ)]
- f→R
- x→τ:=(s0,a0,r0,s1,a1,r1,⋯,sT−1,aT−1,rT−1,sT)
g^:=∇θEτ[R(τ)]=Eτ[∇θlogp(τ∣θ)R(τ)]
现在研究 p(τ∣θ)
- 在当前策略 πθ 下,当前关注的轨迹 τ 发生的概率
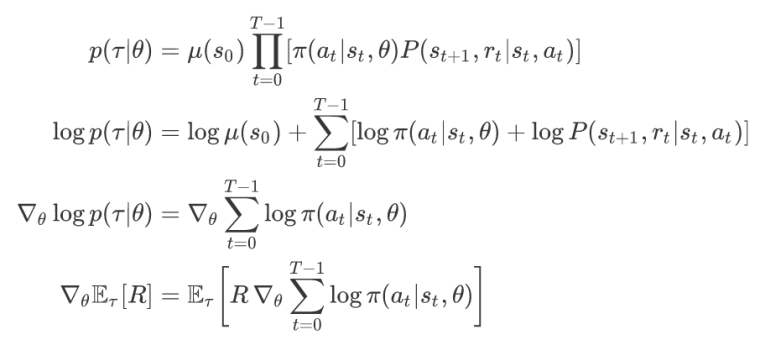
g^:=∇θEτ[R(τ)]=Eτ[R(τ)t∑∇θlogπθ(at∣st)]
现在需要定义 R(τ) 了
-
Q函数 / 状态-动作评分
Qπ,γ(s,a)=Eπ[r0+γr1+γ2r2+⋯∣s0=s,a0=a]
-
状态评分
Vπ,γ(s)=Ea∼π[Qπ,γ(s,a)]
-
进步评分
-
在状态 s 时采取动作 a=π(s) 所能产生的评分提升
Aπ,γ(s,a)=Qπ,γ(s,a)−Vπ,γ(s)
取其中一种形式
得到
g^=∇θEτ[R]≈Eτ[t=0∑T−1∇θlogπθ(at∣st)(t′=t∑T−1γt′−trt′−b(st))]
其中
- b(st)≈E[rt+γrt+1+γ2rt+2+⋯+γT−1−trT−1]
构建算法流程
- 初始化策略网络参数 θ,评价基准 b
- (训练循环)
- 在环境 p 中跑当前策略 π 得到轨迹数据 τ
- 离散:at∼M(πθ(st),pa)
- 连续:at∼N(πθ(st),σ)
- 对轨迹 τ 中每一步 t 计算
- 环境评分 Rt=∑t′=tT−1γt′−trt′
- 策略进步评价 A^t=Rt−b(st)
- 更新评价基准 b←argminb∑t∈τ∥Rt−b(st)∥2
- 使用计算的策略梯度 g^ 更新策略网络参数 θ
- 离散:losst:=xent(at,πθ(st))⋅A^t
- 连续:losst:=−logπθ(at∣st)⋅A^t