Visual Question Answering with Memory-Augmented Networks
引用论文
Hierarchical Question-Image Co-Attention for Visual Question Answering
在一般的VQA问题中,我们使用梯度下降来更新模型,使用低频截断来减少答案分类数,这样会造成模型对低频答案得到的分数较低,难以得到正确答案。这篇文章介绍了一种新的Memory-Augmented方法来解决这一问题。
模型结构
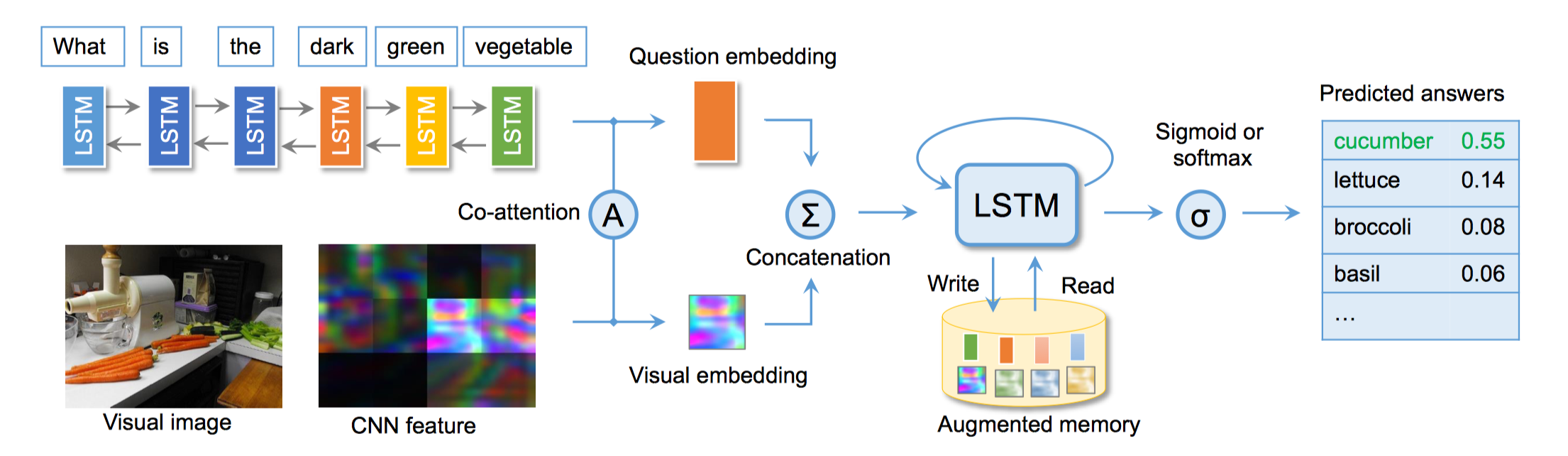
模型主要有三大块
1. 问题及图像特征提取
这里使用了双向LSTM提取问题特征,而对于图像特征,这里是将图片输入CNN网络中,从它的一层池化层中输出,(如VGG-16从pool5层输出,得到矩阵为14 X 14 X 512),再reshape得到(196 X 512)的矩阵,这里的196就是CNN feature中的分区(region)数。
{v1,...,vN},N=196
2. Sequential Co-Attention 协同注意力
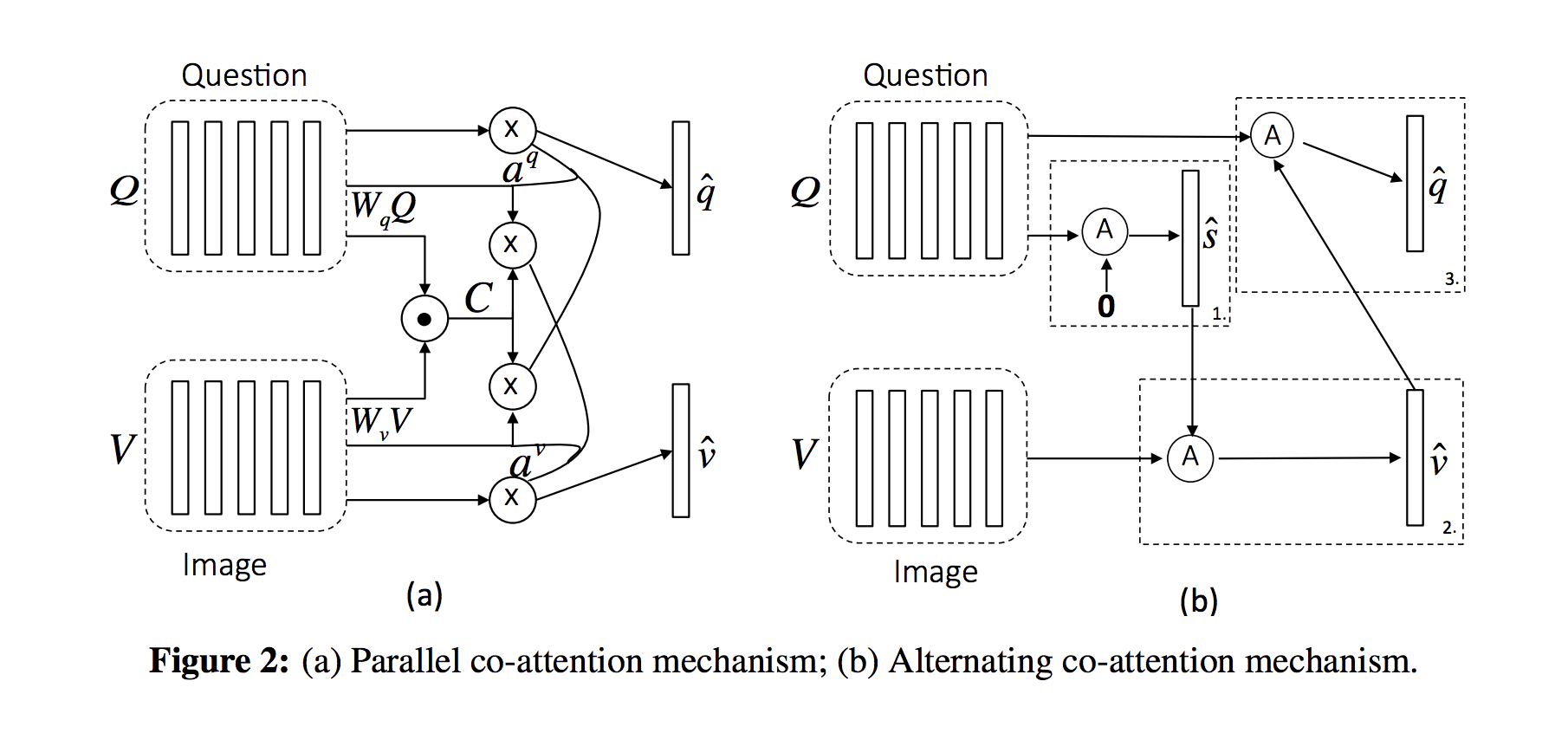
这里用的是Parallel模型,主要是为了做attention提取出question与image的相关的特征。
First, compute a base vector m_0:
m0=v0⊙q0
where v0=tanh(N1n∑Vn)
q0=T1t∑qt
Visual attention:
hn=tanh(Wvvn)⊙tanh(Wmm0)
αn=softmax(Whhn)
v∗=tanh(n=1∑Nαnvn)
where W_v, W_m, W_h denote hidden states.
Question attention:
ht=tanh(Wqqt)⊙tanh(Wmm0)
αt=softmax(Whht)
q∗=t=1∑Tαtqt
3. Memory Augmented Network
这里用到了一个LSTM作为memory controller
ht=LSTM(xt,ht−1)
将h_t与memory中的所有记忆单元计算余弦相似度,再过softmax得到概率,再与M_t相乘得到记忆向量r_t,将h_t与r_t concatenate到一起输入到分类网络中。
D(ht,Mt(i))=∣∣ht∣∣ ∣∣Mt(i)∣∣ht⋅Mt(i)
wtr(i)=softmax(D(ht,Mt(i)))
rt=i∑wtr(i)Mi
Memory 的更新
f(x)=1 if x is True else 0
wtw=σ(α)wt−1r+(1−σ(α)f(wt−1u≤m(wt−1u,n)))
Mti=Mt−1(i)+wtw(i)ht