【学习笔记】cs229机器学习笔记(一)
-
机器学习 Day 1
10/22 学习内容:
1) Markdown的基本操作
2 )开始学习cs229机器学习的网课- 监督学习
- 回归
- 连续量
- 每个样本都已知属性和标签 ->已给出“正确答案”
- 分类
- 预测一个离散量输出(0/1)
- 无监督学习
- 可利用聚类算法,对于数据集进行分析
- 无标签性
Octave->便于学习&开发
符号定义
- m=训练样本组数
- x:输入量、特征量(输入的)
- y:输出变量、目标变量
- (x,y)-> 一个训练样本
-> 第i个训练集样本
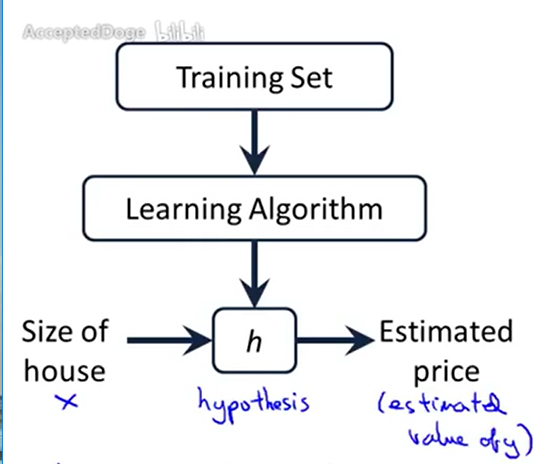
线性回归模型
代价函数

梯度下降算法

梯度下降的几何形式
下图为梯度下降的目的,找到J(θ)的最小值。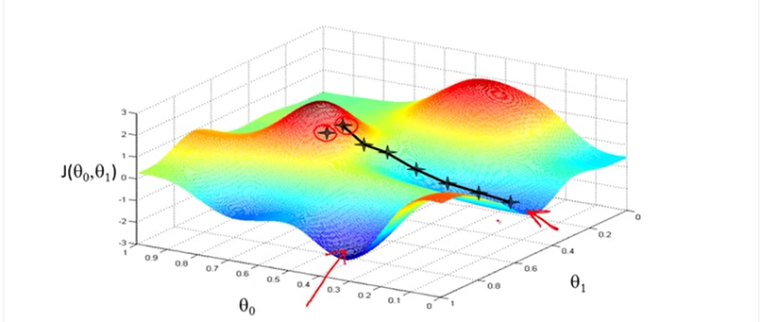
对参数向量θ中的每个分量θj,迭代减去速率因子即可,后边一项为J(θ)关于θj的偏导数

- 同时更新 θ0和θ1
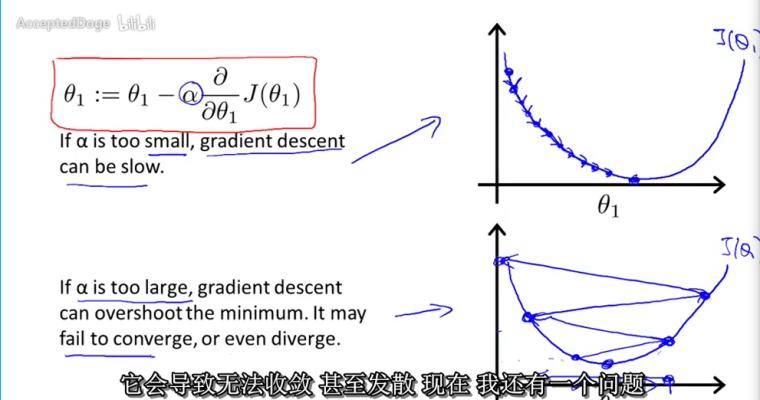
- α--学习速率,控制多大速率更新θj
- α很小时,需要很多步才能达到局部最低点
- α过大时,可能在迭代过程中不断发散,远离最低点
- 梯度——对点x0的导数反映了函数在点x0处的瞬时变化速率,或者叫在点x0处的斜度。推广到多维函数中,就有了梯度的概念,梯度是一个向量组合,反映了多维图形中变化速率最快的方向。
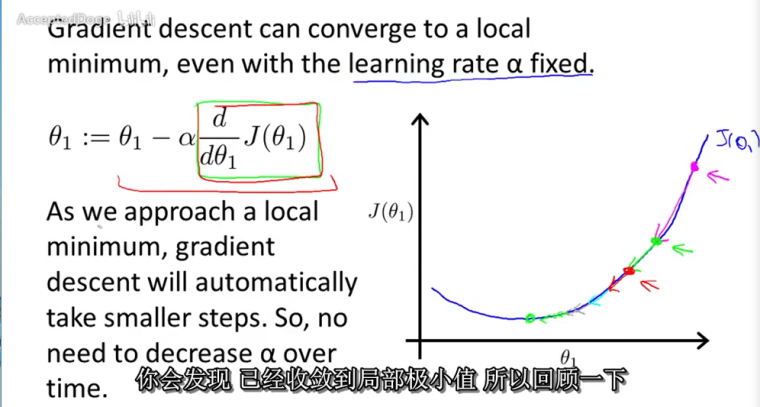
当只有一个θ参数时的代价函数收敛情况:
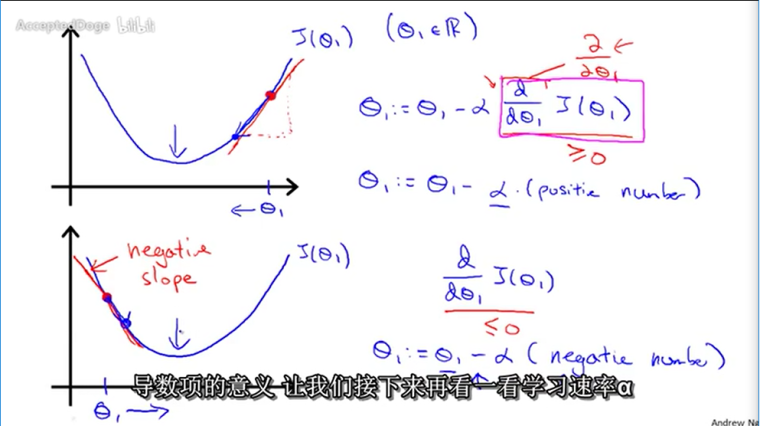
当θ收敛到局部最低点时,θ将不再改变
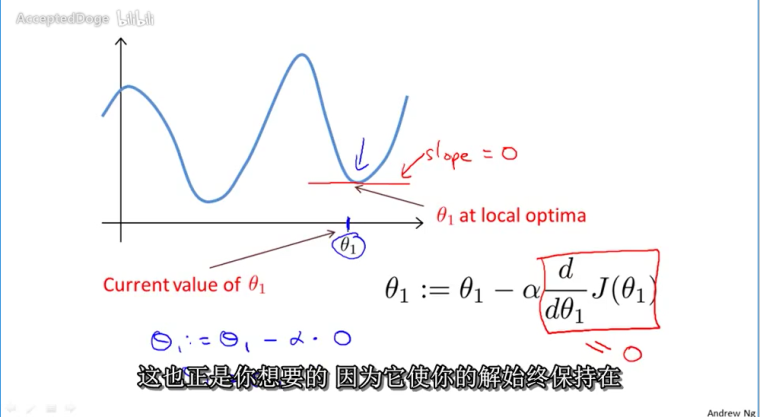
没有必要去减小α,因为导数项能够调整函数梯度下降的速度
线性假设下的梯度下降算法应用

梯度下降算法的分类
- 批量梯度下降算法(Batch Gradient Descent)
- 在整个训练集上计算的,如果数据集比较大,可能会面临内存不足问题,
- 其收敛速度一般比较慢
-
随机梯度下降算法(Stochastic GradientDescent)
- 针对训练集中的一个训练样本计算的,又称为在线学习,即得到了一个样本,就可以执行一次参数更新。
- 收敛速度会快一些,但是有可能出现目标函数值震荡现象,因为高频率的参数更新导致了高方差。
-
小批量梯度下降算法(Mini-batch Gradient Descent)
- 选取训练集中一个小批量样本计算,这样可以保证训练过程更稳定,而且采用批量训练方法也可以利用矩阵计算的优势。这是目前最常用的梯度下降算法。
梯度下降算法仍然存在的问题:
可以做到局部收敛目前无法保证全局收敛还将是一个持续性的数学难题。
此处参考:一文看懂常用的梯度下降算法。
矩阵的维数=number of rows*number of columns
e.g 4*2 的矩阵矩阵与向量相乘
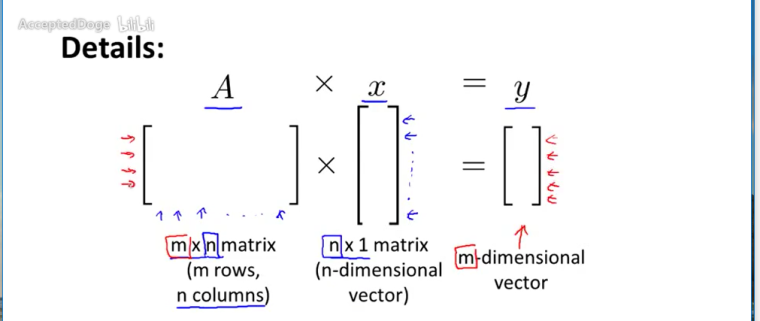
-
建议把这个系列的学习笔记放到团队博客AI方向下, 可以参考hunto的cs231的帖子
-
”学习率没有必要改变“ 不适用于所有情况,当数据量过大的时候, 能够自适应的改变学习率能够让模型更快的收敛; 或者当数据不均衡的时候, 自适应的优化器也是能够让模型学习走向更好的方向. 可以去看看不同类型的优化器adam、Momentum等等, 引入了一些新的思想可以看看


-
加油!(其实我是为了凑第100条发帖的)
-
写作业不要用octave/matlab,可以去github上找一份用python的作业。
-
@haizi 谢谢学长指教!
查了一下有关Momentum的优化器:通过引入Momentum可以让那些因学习率太大而来回摆动的参数,梯度能前后抵消,从而阻止发散。
(直观上的看到的梯度下降收敛路径真的perfect )
)
-
@hunto Thanks♪(・ω・)ノ
-
@zkhust 嗯嗯!