《Tag Disentangled Generative Adversarial Networks for Object Image Re-rendering》IJCAI2017最佳学生论文
-
《Tag Disentangled Generative Adversarial Networks for Object Image Re-rendering》
最近在研究多视角数据增强的方法,读到了这一篇,感觉思想很重要
这篇文章是IJCAI2017的最佳学生论文,简称TD-GAN,用于从单个输入图像中提取可分解的特征,并通过调整所学特征来重新渲染图像。
附上链接:https://www.ijcai.org/proceedings/2017/0404.pdf
目前我复现了一部分,还没写完,https://github.com/lizekang/TD-GANAbstract
本文提出了一种全新的神经网络框架,标签分解生成对抗网络(Tag Disentangled Generative Adversarial Networks, TDGAN),用于进行目标图像的再次渲染(Re-rendering)。给定目标图像作为输入,该网络(TDGAN)即可根据指定要求修改图像内容,并生成符合描述的图像。例如,改变输入图像的观察角度,光照条件,人脸表情等等。和以往工作不同,通过利用图像与其标签的对应关系,即标签是图像分解表征(disentangled representations, DR)的Embedding,我们训练分解网络以提取输入图像的分解表征(DR)。生成网络根据这些表征以及新的标签重新渲染图像。
Network Architecture
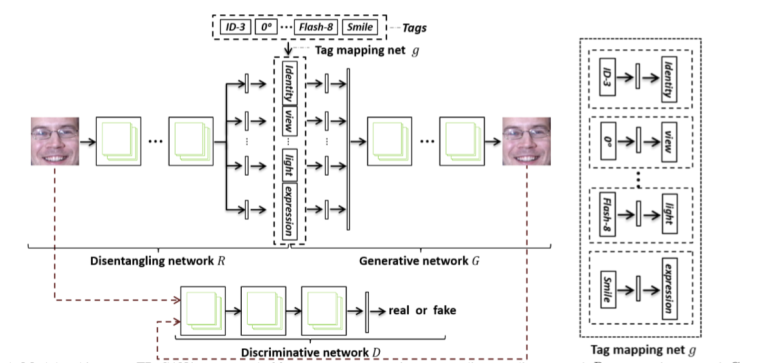
文章中使用了四个网络,a disentangling network, a generative network, a tag mapping net, and a discriminative network。- Disentangling Network
用来分解图片特征的网络,将图片的表征分解成几个独立的domain,比如光照,表情,viewpoint等。 - Tag Mapping Net
用来将不同Domain的标签mapping到Disentangling Network分解出来的对应domain上,之后就可以使用Tag Mapping Net生成的特征来替换掉Disentangling Network产生的特征了。 - Generative Network
生成器,根据重组后的特征生成图像 - Discriminative Network
辨别器,辨别生成的图像真/假
看完网络结构感觉这篇文章其实思路很简单,就是替换feature罢了,但是我觉得真正困难的地方是这样一个比较复杂的网络该怎么去训练。果不其然,作者用大篇幅介绍了如何训练以及参数设置,可以说是很良心了。
网络训练策略
直接上公式了,对应着图看着公式基本能明白是干什么的(带*的代表冻结该网络)
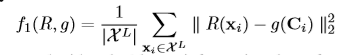
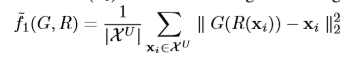
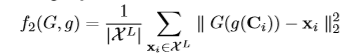
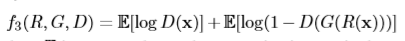
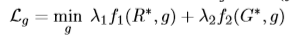
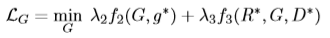
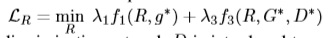
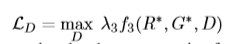
网络参数设置


惊艳的实验结果
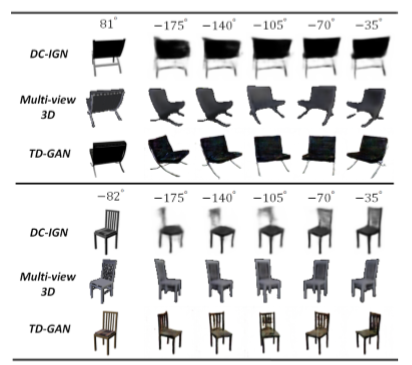

- Disentangling Network
-
转自:http://www.sohu.com/a/257772655_473283
多视角学习:面向决策策略的“盲人摸象”大家都知道盲人摸象的故事,实际上我们做决策的时候,跟盲人是一样的,因为我们所获取到的信息也是不完整的。那么我们在做觉得时候,也就是根据已有的信息作出的最优策略。因此,对于同样的事情,每一个人所作出的决定可能也不相同。
多视角学习对于现今的智能系统非常重要,这是因为智能系统中都安装了大量的传感器,比如,现在的无人车安装了激光雷达、毫米波雷达、摄像机、IMU等等。每个传感器都只能够感知环境中的部分信息,那么我们就需要把不同的传感的信息融合起来,帮助我们做最后的决策。
假设存在一个oracle space,那么每个传感器就可以被建模成对oracle space的一个线性或者非线形投影。如果我们有大量的传感器,那么我们就能够获取大量的投影信息。我们可以证明,如果说我们有足够多的不同的投影信息,我们就能够以非常高的概率去重构这个oracle space。有了这个oracle space,我们就可以有效的做决策了。
请大家看一下最左边的这张图像。你第一眼看到了什么?大多说人一定会说是船。然后你还会注意到船上有人。对不对?这个现象提示我们,这样的顺序信息对于我们进行多标签学习会非常有帮助。通过增强学习,我们可以有效的学习这个顺序,来提升增强学习的效率。
我们今天所面临的学习问题可能是这样的一个情况:训练数据和测试数据来自不同的传感器或者信息域。这就是domain generalization要解决的问题。因为训练数据和测试数据来自不同的域,我们就需要找寻一些特征:这些特征在训练数据上和测试数据上,对于完成我们的规定任务来说都是有效的。
人可以很轻松的做到这一点:我儿子3岁的时候,我给他看过长颈鹿的卡通画片。当我带他去动物园的时候,他可能很轻松的认出真正的长颈鹿。可是在这之前,他从来没有见过实际场景中的长颈鹿。我们当然希望计算机也具备类似的能力。这里我们利用GAN网络(对抗生成网络)能够有效地学习这样的不变特征。
我们提出了一个端到端的条件对抗域自适应深度学习模型来学习域不变的特征,该模型同时衡量分布P(Y)和条件概率分布P(X|Y)的不变性。该网络框架包括了四个部分。第一部分AlexNet用来学习域不变的特征。第二部分是图像分类网络,用来保证学习的特征具有良好的类别区分性。
特征的域不变性质利用类别先验归一化域分类网络和类别条件域分类网络保证。其中类别先验归一化域分类网络用来匹配不同域的类别先验归一化分布,该网络的主要目的是消除不同域之间的变化。其次,类别条件域分类网络用来保证对于每一类的分布匹配。这样就能够保证不同域的联合概率分布是匹配的。在不同标准数据集上得到的实验结果证明了我们方法的有效性,并且要比现有方法有显著的提高。
最近大家开始关注学习的可解释性。我们用GAN网络可以学到特征来生成我们需要的数据。可是这些特征的含义是什么?我们并不清楚。
通过模仿人类理解世界的方式,我们希望计算机能够从这个复杂的世界中学习到抽象的概念,并根据这些概念创造新的东西。因此,我们需要计算机能够从真实世界图像中提取到可分解的特征,例如照片中人物的身份,拍摄角度,光照条件等等。这个就是tag disentanglement。有了可分解的特征,我们也能很好的解释我们学习到的特征到底是什么物理含义。
我们提出了一个新的框架(TD-GAN),用于从单个输入图像中提取可分解的特征,并通过调整所学特征来重新渲染图像。从某种程度上说,TD-GAN提供了一个可以理解现实世界中图像的深度学习框架。
网络所学习到的可分解的特征,实际上对应于图像中所描述主体的不同属性。与人类理解世界的方式相似,学习可分解的特征有助于机器解释并重构现实世界的图像。因此,TD-GAN能够根据用户指定的信息合成高质量的输出图像。
TD-GAN可应用于(1)数据增强,即通过合成新的图像以用于其他深度学习算法的训练与测试,(2)生成给定对象连续姿态的图像,以用于三维模型重建,以及(3)通过解析,概括来增强现有创作,并创造充满想象力的新绘画。
-
我们目前做的多视角图片数据增强和TD-GAN又有一些不同。TD-GAN仅仅是在chairs这个dataset上产生了很好的效果,不过,试想,当一个物体较为复杂的时候,不可能根据一张图片生成这么完美的图像,那我们怎样产生多视角图像呢?
这恰恰是我们正在研究的内容,我们在探究一种让网络学会融合各视角的图像,如何使网络将各视角的图像组合起来,在“大脑”中构思出这个物体的“3d模型”。这其实是多视角学习,多模态学习很关键的一步。