Memory Network系列2 - End-To-End Memory Networks
-
我的博客:Memory Network系列2 - End-To-End Memory Networks
References
- End-To-End Memory Networks , 31 Mar 2015
End-To-End Memory Networks
前一节中我们说到,Memory Networks虽然能够很好地处理长期依赖的问题,但由于其网络结构不是端到端的,导致训练时需要更多的标记,难以用于更多的任务中。于是Facebook紧接着在2015年提出了 End-To-End Memory Networks 解决了这一问题。
实现
与前一篇文章相同,模型的输入为离散的句子特征集合
,问题特征 ,输出为答案 。
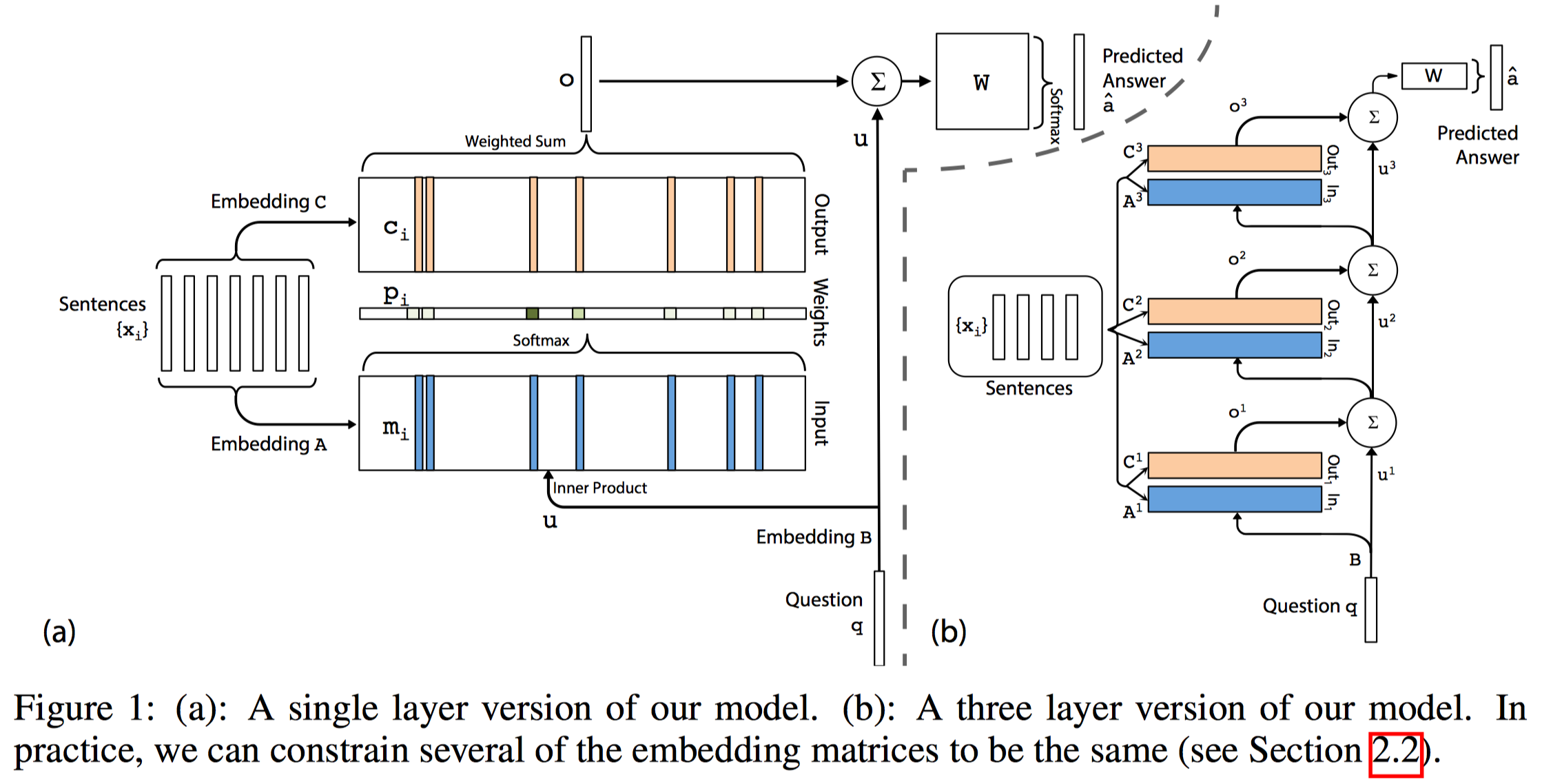
模型首先将所有的存储到一个固定大小的记忆中,再找到对 和 的一个连续表示,这一连续表示通过多个hop得到输出 。这样我们可以通过反向传播将损失经过多个memory传回输入。 Single Layer
我们先从单层记忆网络的端到端实现看起。
Input Memory Representation
对于input set
,我们首先将 经过embedding层得到维度为 的memory vector 。最简单的embedding实现方式是用一个大小为 的矩阵 表示embedding。 也通过同样的方式经过embedding得到其internal state ,接着,我们将 与 做内积再经过softmax得到输入 对于 的概率表示 : Output Memory Representation
首先,我们让每一个
都有一个与其对应的表示 (最简单的方式就是再用一个embedding),最终output的输出就是input得到的概率矩阵 与 的乘积(element-wise)的和: 这样,我们就可以将o处的梯度往回传到input了。
Generating the Final Prediction
这部分很简单,将记忆输出
与问题表示 相加再与一个权值矩阵 相乘,最后过softmax即可:
Multiple Layers
这部分要实现的目的与上一篇文章的top-k相同,具体实现也与上一篇文章类似,将前一层的输出与
一同作为下一层的输入。 - 第一层以后的输入
为前一层的输出与 的和:
- 每一层都有自己的embedding矩阵
得到 - 最终的输出为: