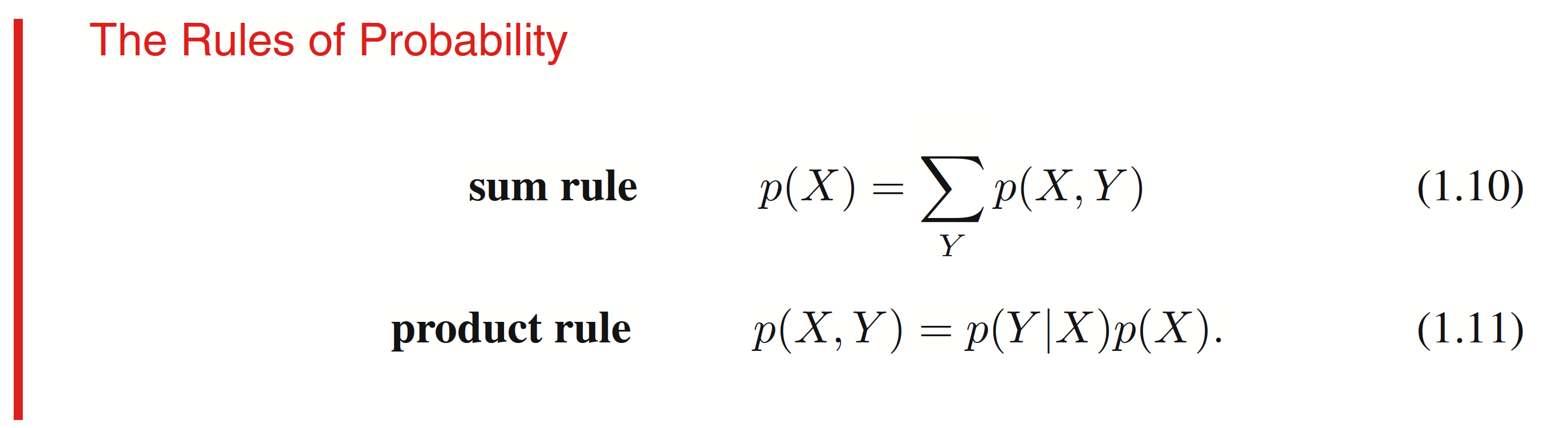1. Introduction
1.1 Example
Square Error
E ( W ) = 1 2 ∑ n = 1 N ( y ( x n , W ) − t n ) 2 E(W)=\frac12 \sum^N_{n=1}(y(x_n,W)-t_n)^2 E ( W ) = 2 1 n = 1 ∑ N ( y ( x n , W ) − t n ) 2
Root-Mean-Square Error
E R M S = 2 E ( W ) / N E_{RMS} = \sqrt {2E(W)/N} E R M S = 2 E ( W ) / N
这里,开方是为了使 error 与 target 有相同的scale,除以N是为了比较在不同大小数据集中的损失。实质上它与平方误差没什么差别。
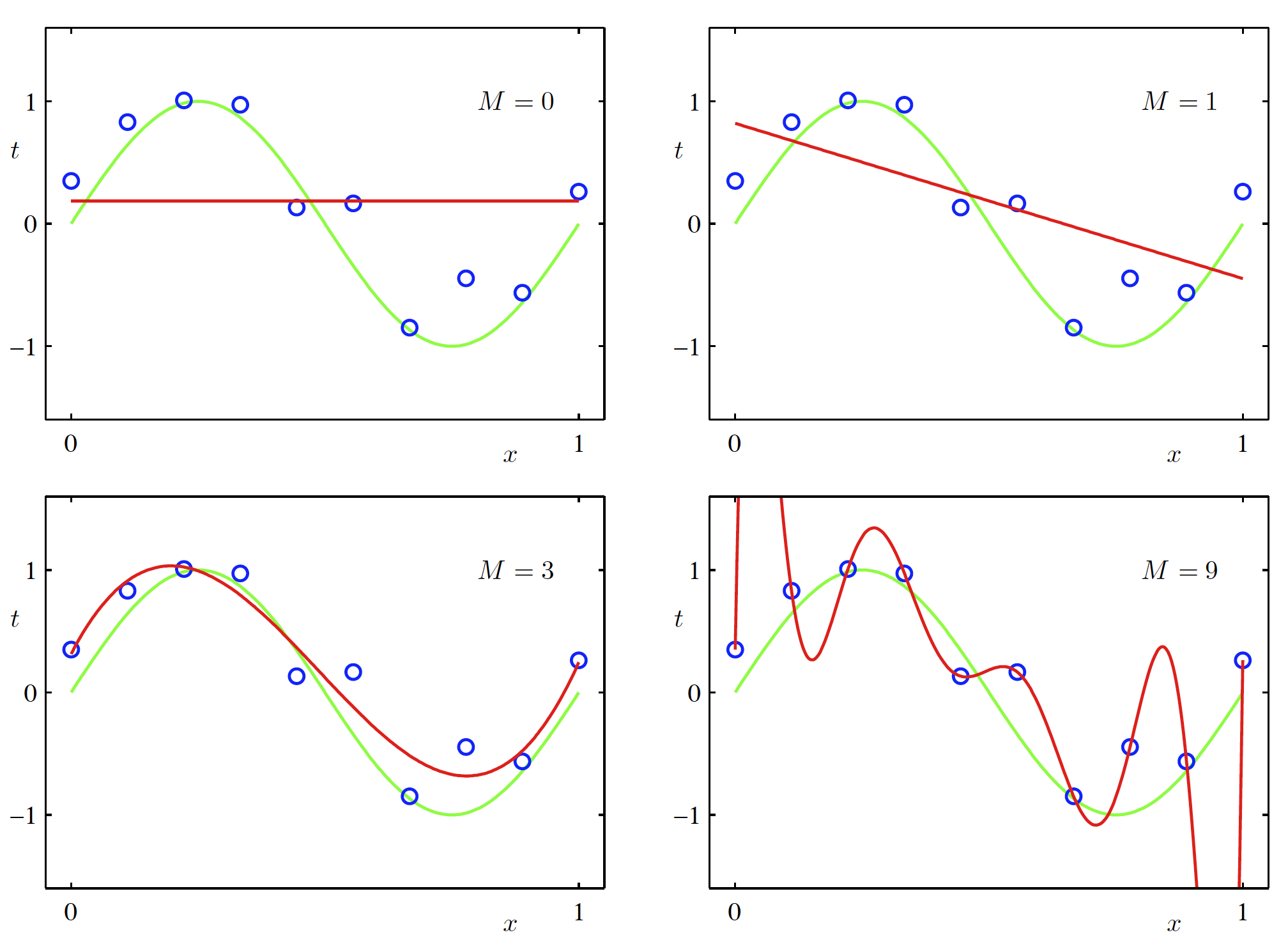
过拟合
如上图,不同阶数多项式拟合出的图像。在数据较少的情况下,方程越复杂,越容易过拟合。
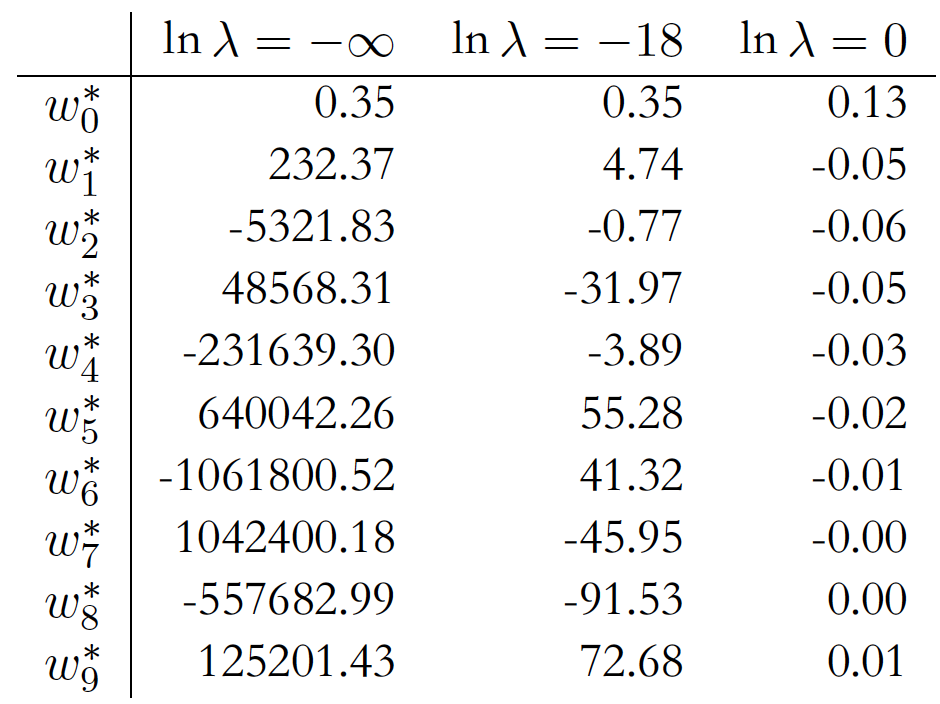
可以看出,过拟合情况下,高次项系数非常大。
因此,为了减缓过拟合,我们应该抑制方程系数的增大。
E ~ ( W ) = 1 2 ∑ n = 1 N ( y ( x n , W ) − t n ) 2 + ∑ i M ( w i ) 2 \tilde E(W) = \frac12 \sum^N_{n=1}(y(x_n,W)-t_n)^2 + \sum^M_i (w_i)^2 E ~ ( W ) = 2 1 n = 1 ∑ N ( y ( x n , W ) − t n ) 2 + i ∑ M ( w i ) 2
下表为不同 λ \lambda λ
1.2 概率论 (Probability Theory)
1.2.3 Bayes' theorem
p ( w ∣ D ) = P ( D ∣ w ) P ( w ) P ( D ) p(w|\mathcal{D}) = \frac{P(\mathcal{D}|w)P(w)}{P(D)} p ( w ∣ D ) = P ( D ) P ( D ∣ w ) P ( w )
p ( D ) = ∫ p ( D ∣ w ) p ( w ) d w p(\mathcal{D}) = \int p(\mathcal{D}\ |\ w)p(w)dw p ( D ) = ∫ p ( D ∣ w ) p ( w ) d w
Likelihood Function: p ( D ∣ w ) p(\mathcal{D}|w) p ( D ∣ w )
1.2.4 Gaussian Distribution
N ( x ∣ μ , σ 2 ) = 1 ( 2 π σ 2 ) 1 / 2 e x p ( − 1 2 σ 2 ( x − μ ) 2 ) \mathcal{N}(x|\mu , \sigma^2) = \frac{1}{(2\pi \sigma^2)^{1/2}}exp(-\frac{1}{2\sigma^2}(x - \mu)^2) N ( x ∣ μ , σ 2 ) = ( 2 π σ 2 ) 1 / 2 1 e x p ( − 2 σ 2 1 ( x − μ ) 2 )
Maximum Likelihood solution
μ M L = 1 N ∑ n = 1 N x n \mu_{ML}=\frac1N\sum^N_{n=1} x_n μ M L = N 1 ∑ n = 1 N x n σ M L 2 = 1 N ∑ n = 1 N ( x n − μ M L ) 2 \sigma^2_{ML} = \frac1N \sum^N_{n=1}(x_n - \mu_{ML})^2 σ M L 2 = N 1 ∑ n = 1 N ( x n − μ M L ) 2
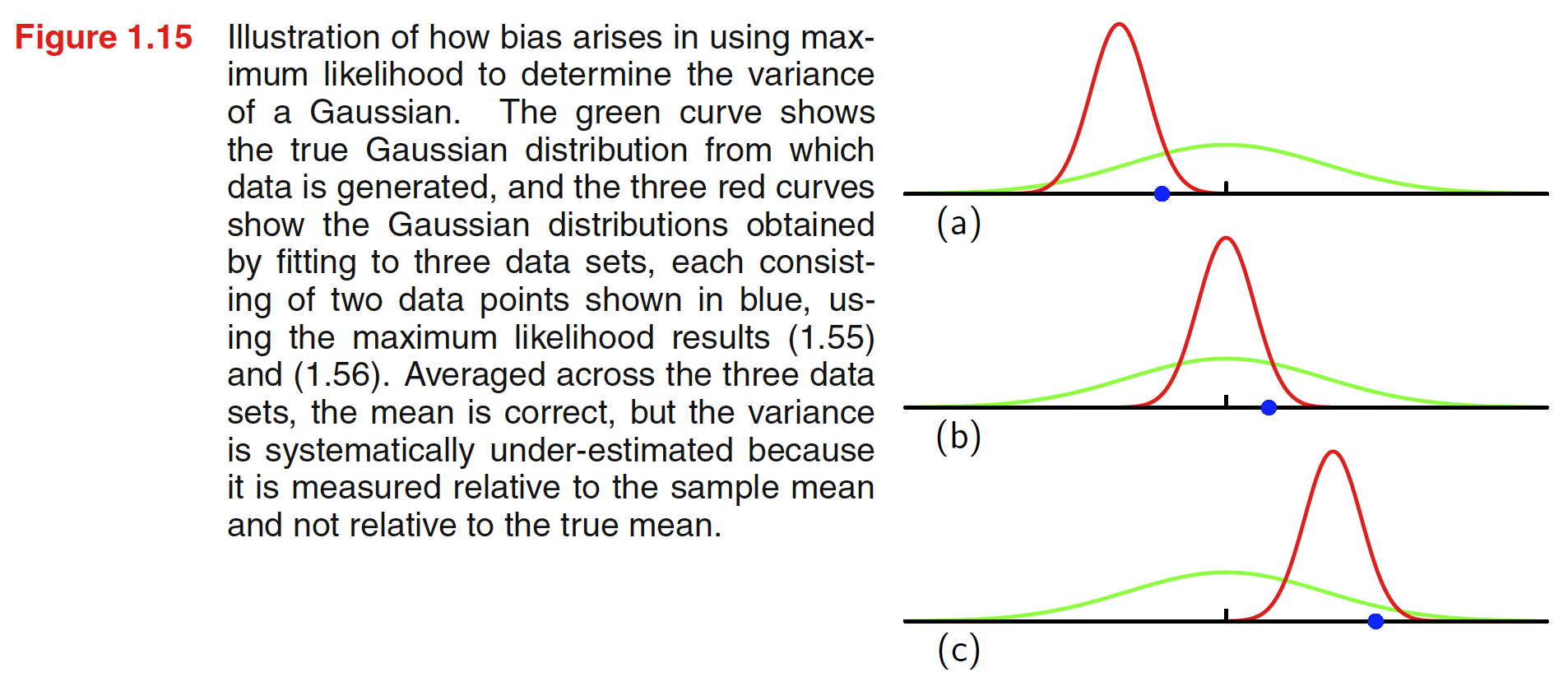
最大似然估计的方差偏移问题
计算最大似然解的期望:
E ( μ M L ) = μ E(\mu_{ML}) = \mu E ( μ M L ) = μ E ( σ M L 2 ) = ( N − 1 N ) σ 2 E(\sigma^2_{ML}) = (\frac{N-1}{N})\sigma^2 E ( σ M L 2 ) = ( N N − 1 ) σ 2
由上公式,我们可以将 σ M L 2 \sigma^2_{ML} σ M L 2 N N − 1 \frac{N}{N-1} N − 1 N σ 2 \sigma^2 σ 2
σ ~ 2 = N N − 1 σ M L 2 = 1 N − 1 ∑ n = 1 N ( x n − μ M L ) 2 \tilde \sigma^2 = \frac{N}{N-1}\sigma^2_{ML} = \frac1{N-1} \sum^N_{n=1}(x_n - \mu_{ML})^2 σ ~ 2 = N − 1 N σ M L 2 = N − 1 1 n = 1 ∑ N ( x n − μ M L ) 2
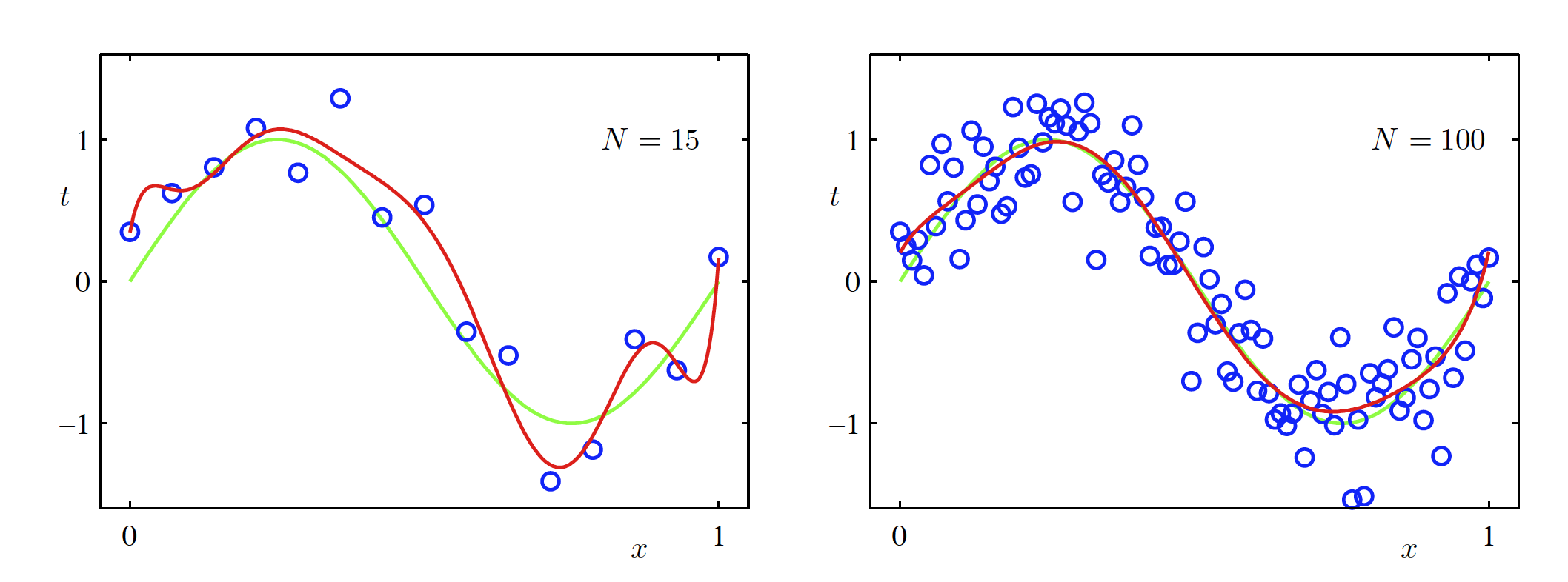
通过上式可以看出,当样本量较小时,使用极大似然估计得到的方差偏移很大,均值无偏移,当样本量趋于无穷大时,极大似然方差的误差可以忽略。这样的偏移是前面多项式过拟合问题的核心,在机器学习中,带有更多参数的复杂模型更会加重这一现象,在本书的后面会详细阐释。
1.2.5 通过高斯分布重新考察曲线的过拟合问题
多项式曲线的拟合是通过误差最小化实现的,我们这里从概率的角度理解过拟合和正则化。
曲线拟合问题的目标是根据给定 X = x 1 , x 2 , . . . , x n X = { x_1, x_2, ..., x_n } X = x 1 , x 2 , . . . , x n T = t 1 , t 2 , . . . , t n T = { t_1, t_2, ..., t_n} T = t 1 , t 2 , . . . , t n x x x t t t
假设,X , T X, T X , T y ( x , W ) y(x, W) y ( x , W )
y ( x , W ) = ∑ j = 0 M w j x j ( 1 . 1 ) y(x, W) = \sum^M_{j=0}w_jx^j\ \ \ \ (1.1) y ( x , W ) = j = 0 ∑ M w j x j ( 1 . 1 )
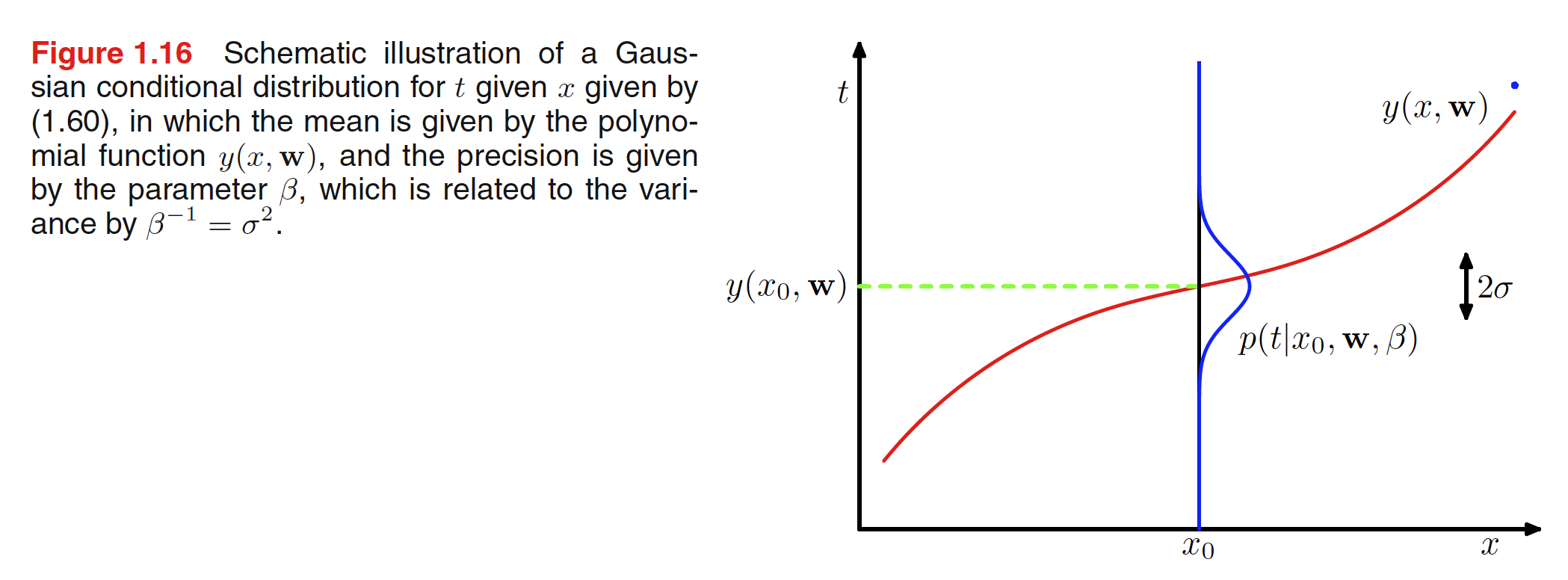
p ( t ∣ x , W , β ) = N ( t ∣ y ( x , W ) , β − 1 ) ( 1 . 6 0 ) p(t\ |\ x,W,\beta)= \mathcal{N}(t\ |\ y(x,W),\beta^{-1})\ \ \ \ \ \ \ (1.60) p ( t ∣ x , W , β ) = N ( t ∣ y ( x , W ) , β − 1 ) ( 1 . 6 0 )
为了与后续章节统一,这里定义了精度参数 β \beta β
由公式1.60我们可以得到最大似然方程如下:
我们首先确定 W W W W W W W W W 1 2 \frac12 2 1 1 β \frac1\beta β 1
E ( W ) = 1 2 ∑ n = 1 N ( y ( x n , W ) − t n ) 2 ( 1 . 2 ) E(W)=\frac12 \sum^N_{n=1}(y(x_n,W)-t_n)^2\ \ \ \ (1.2) E ( W ) = 2 1 n = 1 ∑ N ( y ( x n , W ) − t n ) 2 ( 1 . 2 )
因此,我们之前使用的平方误差函数其实是使用高斯噪声函数下,最大化似然函数的一个自然结果。
在得到了 W M L W_{ML} W M L β \beta β
1 β M L = 1 N ∑ n = 1 N [ y ( x n , W M L ) − t n ] 2 \frac1{\beta_{ML}} = \frac1N\sum_{n=1}^N[y(x_n, W_{ML})- t_n]^2 β M L 1 = N 1 n = 1 ∑ N [ y ( x n , W M L ) − t n ] 2
把上面的两个最大似然参数代入1.60中,我们可以得到t的概率分布的预测分布:
p ( t , W M L , β M L ) = N ( t ∣ y ( x , W M L ) , β M L − 1 ) p(t, W_{ML}, \beta_{ML}) = \mathcal{N}(t\ |\ y(x,W_{ML}),\beta^{-1}_{ML}) p ( t , W M L , β M L ) = N ( t ∣ y ( x , W M L ) , β M L − 1 )
根据贝叶斯定理,我们想要得到在 x , t x, t x , t W W W p ( W ∣ x , t ) p(W\ |\ x, t) p ( W ∣ x , t ) W W W W W W
p ( W ∣ α ) = N ( W ∣ 0 , α − 1 I ) = ( α 2 π ) M + 1 2 e x p ( − α 2 W T W ) p(W\ |\ \alpha) = \mathcal{N}(W\ |\ 0, \alpha^{-1}I)=(\frac{\alpha}{2\pi})^{\frac{M+1}2}exp(-\frac\alpha2W^TW) p ( W ∣ α ) = N ( W ∣ 0 , α − 1 I ) = ( 2 π α ) 2 M + 1 e x p ( − 2 α W T W )
这里 α \alpha α
因此,由贝叶斯定理,我们有:
p ( W ∣ X , T , α , β ) ∝ p ( T ∣ X , W , β ) p ( W ∣ α ) p(W\ |\ X,T,\alpha,\beta)\propto p(T\ |\ X, W, \beta) p(W\ |\ \alpha) p ( W ∣ X , T , α , β ) ∝ p ( T ∣ X , W , β ) p ( W ∣ α )
通过寻找最可能的 W W W W W W
β 2 ∑ n = 1 N [ y ( x n , W ) − t n ] 2 + α 2 W T W \frac\beta2 \sum_{n=1}^N[y(x_n,W)-t_n]^2 + \frac\alpha2 W^TW 2 β n = 1 ∑ N [ y ( x n , W ) − t n ] 2 + 2 α W T W
从这里我们可以看出,最大化后验概率等价于最小化正则化的平方和误差函数,正则化参数为 λ = α β \lambda = \frac\alpha\beta λ = β α
E ~ ( W ) = 1 2 ∑ n = 1 N ( y ( x n , W ) − t n ) 2 + λ 2 W T W ( 1 . 4 ) \tilde E(W) = \frac12 \sum^N_{n=1}(y(x_n,W)-t_n)^2 + \frac\lambda2W^TW\ \ \ \ (1.4) E ~ ( W ) = 2 1 n = 1 ∑ N ( y ( x n , W ) − t n ) 2 + 2 λ W T W ( 1 . 4 )
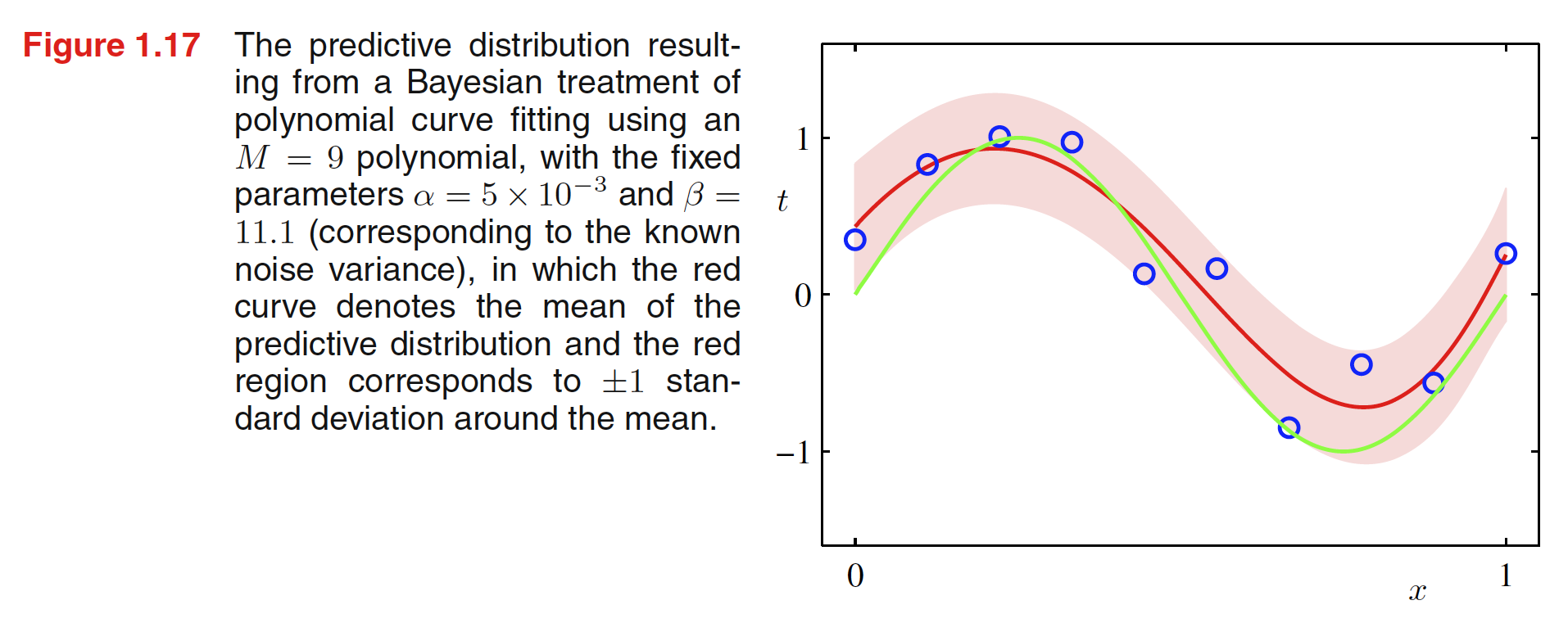
1.2.6 贝叶斯曲线拟合 (Bayesian Curve fitting)
虽然在上一节已经使用了先验分布来得到后验概率分布,但对于 W W W W W W 这种积分是贝叶斯方法的核心 。
在曲线拟合问题中,我们知道 X , T X, T X , T t t t t t t p ( t ∣ x , X , T ) p(t\ |\ x, X, T) p ( t ∣ x , X , T )
p ( t ∣ x , X , T ) = ∫ p ( t ∣ x , W ) p ( W ∣ X , T ) d W p(t\ |\ x, X, T) = \int p(t\ |\ x, W)p(W | X, T)dW p ( t ∣ x , X , T ) = ∫ p ( t ∣ x , W ) p ( W ∣ X , T ) d W
这里与上一节的不同之处在于,W W W X , T X, T X , T
我们可以从公式1.69中看到,t t t X X X β − 1 \beta^{-1} β − 1 W W W
Exercises
1.1
y ( x , W ) = ∑ j = 0 M w j x j ( 1 . 1 ) y(x, W) = \sum^M_{j=0}w_jx^j\ \ \ \ (1.1) y ( x , W ) = j = 0 ∑ M w j x j ( 1 . 1 )
E ( W ) = 1 2 ∑ n = 1 N ( y ( x n , W ) − t n ) 2 ( 1 . 2 ) E(W)=\frac12 \sum^N_{n=1}(y(x_n,W)-t_n)^2\ \ \ \ (1.2) E ( W ) = 2 1 n = 1 ∑ N ( y ( x n , W ) − t n ) 2 ( 1 . 2 )
将(1.1)代入(1.2)得
E ( W ) = 1 2 ∑ n = 1 N ( ∑ j = 0 M w j x n j − t n ) 2 E(W)=\frac12 \sum^N_{n=1}(\sum^M_{j=0}w_j x_n^j - t_n)^2 E ( W ) = 2 1 n = 1 ∑ N ( j = 0 ∑ M w j x n j − t n ) 2
对 w i w_i w i
∂ E ( W ) ∂ w i = ∑ n = 1 N ( ∑ j = 0 M w j x n j − t n ) x n i = 0 \frac{\partial E(W)}{\partial w_i} = \sum^N_{n=1}(\sum^M_{j=0}w_jx_n^j - t_n) x_n^i = 0 ∂ w i ∂ E ( W ) = n = 1 ∑ N ( j = 0 ∑ M w j x n j − t n ) x n i = 0
∑ n = 1 N ( ∑ j = 0 M w j x n j ) ( x n ) i = ∑ n = 1 N t n ( x n ) i \sum^N_{n=1}(\sum^M_{j=0}w_j x_n^j) (x_n)^i= \sum^N_{n=1}t_n(x_n)^i n = 1 ∑ N ( j = 0 ∑ M w j x n j ) ( x n ) i = n = 1 ∑ N t n ( x n ) i
1.2
E ~ ( W ) = 1 2 ∑ n = 1 N ( y ( x n , W ) − t n ) 2 + λ 2 ∑ i M ( w i ) 2 ( 1 . 4 ) \tilde E(W) = \frac12 \sum^N_{n=1}(y(x_n,W)-t_n)^2 + \frac\lambda2 \sum^M_i (w_i)^2\ \ \ \ (1.4) E ~ ( W ) = 2 1 n = 1 ∑ N ( y ( x n , W ) − t n ) 2 + 2 λ i ∑ M ( w i ) 2 ( 1 . 4 )
同样将 (1.1) 代入 (1.2) 得
E ~ ( W ) = 1 2 ∑ n = 1 N ( ∑ j = 0 M w j x n j − t n ) 2 + ∑ i M ( w i ) 2 \tilde E(W)=\frac12 \sum^N_{n=1}(\sum^M_{j=0}w_j x_n^j - t_n)^2 + \sum^M_i (w_i)^2 E ~ ( W ) = 2 1 n = 1 ∑ N ( j = 0 ∑ M w j x n j − t n ) 2 + i ∑ M ( w i ) 2
对 w i w_i w i
∂ E ~ ( W ) ∂ w i = ∑ n = 1 N ( ∑ j = 0 M w j x n j − t n ) x n i + λ w i = 0 \frac{\partial \tilde E(W)}{\partial w_i} = \sum^N_{n=1}(\sum^M_{j=0}w_jx_n^j - t_n) x_n^i + \lambda w_i = 0 ∂ w i ∂ E ~ ( W ) = n = 1 ∑ N ( j = 0 ∑ M w j x n j − t n ) x n i + λ w i = 0
∑ j = 0 M ( ∑ n = 1 N x n ( j + i ) + λ w i M w j ) w j = ∑ n = 1 N t n ( x n ) i \sum^M_{j=0}(\sum^N_{n=1}x_n^{(j+i)} + \frac{\lambda w_i}{Mw_j})w_j= \sum^N_{n=1}t_n(x_n)^i j = 0 ∑ M ( n = 1 ∑ N x n ( j + i ) + M w j λ w i ) w j = n = 1 ∑ N t n ( x n ) i
∑ j = 0 M ( A i j + λ w i M w j ) w j = T i \sum^M_{j=0}(A_{ij}+\frac{\lambda w_i}{Mw_j})w_j=T_i j = 0 ∑ M ( A i j + M w j λ w i ) w j = T i
1.3
p ( a ) = p ( r , a ) + p ( b , a ) + p ( g , a ) = 0 . 3 4 p(a)=p(r, a) + p(b, a) + p(g, a) = 0.34 p ( a ) = p ( r , a ) + p ( b , a ) + p ( g , a ) = 0 . 3 4
p ( g ∣ o ) = p ( o ∣ g ) p ( g ) p ( o ) = p ( o ∣ g ) p ( g ) p ( r , o ) + p ( b , o ) + p ( g , o ) = 0 . 5 p(g|o) = \frac{p(o|g)p(g)}{p(o)} = \frac{p(o|g)p(g)}{p(r,o) + p(b, o) + p(g, o)} = 0.5 p ( g ∣ o ) = p ( o ) p ( o ∣ g ) p ( g ) = p ( r , o ) + p ( b , o ) + p ( g , o ) p ( o ∣ g ) p ( g ) = 0 . 5
1.5 方差公式推导
v a r [ f ( x ) ] = E [ ( f ( x ) − E [ f ( x ) ] ) 2 ] = E [ f ( x ) 2 − 2 f ( x ) E [ f ( x ) ] + E [ f ( x ) ] 2 ] = E [ f ( x ) 2 ] − 2 E [ f ( x ) ] 2 + E [ f ( x ) ] 2 = E [ f ( x ) 2 ] − E [ f ( x ) ] 2 var[f(x)] = E[(f(x) - E[f(x)])^2] \ = E[f(x)^2 - 2f(x)E[f(x)] + E[f(x)]^2] \ = E[f(x)^2] - 2E[f(x)]^2 + E[f(x)]^2 \ = E[f(x)^2] - E[f(x)]^2 v a r [ f ( x ) ] = E [ ( f ( x ) − E [ f ( x ) ] ) 2 ] = E [ f ( x ) 2 − 2 f ( x ) E [ f ( x ) ] + E [ f ( x ) ] 2 ] = E [ f ( x ) 2 ] − 2 E [ f ( x ) ] 2 + E [ f ( x ) ] 2 = E [ f ( x ) 2 ] − E [ f ( x ) ] 2
1.6 两独立事件的协方差为0证明
c o v [ x , y ] = E x , y [ x , y ] − E [ x ] E [ y ] = ∑ x ∑ y p ( x , y ) x y − E [ x ] E [ y ] = ∑ x ∑ y p ( x ) p ( y ) x y − E [ x ] E [ y ] = E [ x ] E [ y ] − E [ x ] E [ y ] = 0 cov[x, y] = E_{x,y}[x,y] - E[x]E[y] \ =\sum_x\sum_yp(x,y)xy - E[x]E[y] \ = \sum_x\sum_yp(x)p(y)xy - E[x]E[y] \ = E[x]E[y] - E[x]E[y] \ = 0 c o v [ x , y ] = E x , y [ x , y ] − E [ x ] E [ y ] = x ∑ y ∑ p ( x , y ) x y − E [ x ] E [ y ] = x ∑ y ∑ p ( x ) p ( y ) x y − E [ x ] E [ y ] = E [ x ] E [ y ] − E [ x ] E [ y ] = 0
1.7 高斯分布归一性证明
I 2 = ∫ − ∞ ∞ ∫ − ∞ ∞ e x p ( − 1 2 σ 2 ( x 2 + y 2 ) ) d x d y I^2 = \int_{-\infty}^\infty\int_{-\infty}^\infty exp(-\frac{1}{2\sigma^2}(x^2+y^2))dxdy I 2 = ∫ − ∞ ∞ ∫ − ∞ ∞ e x p ( − 2 σ 2 1 ( x 2 + y 2 ) ) d x d y
极坐标变换,得
I 2 = ∫ 0 2 π ∫ 0 ∞ e x p ( − r 2 2 σ 2 ) d r d θ = 2 π ∫ 0 ∞ e x p ( − r 2 2 σ 2 ) d r I^2 = \int_0^{2\pi}\int_0^\infty exp(-\frac{r^2}{2\sigma^2})drd\theta \ = 2\pi \int_0^\infty exp(-\frac{r^2}{2\sigma^2})dr I 2 = ∫ 0 2 π ∫ 0 ∞ e x p ( − 2 σ 2 r 2 ) d r d θ = 2 π ∫ 0 ∞ e x p ( − 2 σ 2 r 2 ) d r
令 u = r 2 u = r^2 u = r 2
I 2 = 2 π ∫ 0 ∞ e x p ( − u 2 σ 2 ) 1 2 d u = 2 π σ 2 I^2 = 2\pi \int_0^\infty exp(-\frac{u}{2\sigma^2})\frac12du \ = 2\pi\sigma^2 I 2 = 2 π ∫ 0 ∞ e x p ( − 2 σ 2 u ) 2 1 d u = 2 π σ 2
因此,有
∫ − ∞ ∞ N ( x ∣ u , σ 2 ) = ∫ − ∞ ∞ 1 ( 2 π σ 2 ) 1 2 e x p ( − 1 2 σ 2 ( x − u ) ) d x \int_{-\infty}^\infty \mathcal{N}(x | u, \sigma^2) = \int_{-\infty}^\infty \frac{1}{(2\pi\sigma^2)^{\frac12}}exp(-\frac{1}{2\sigma^2}(x-u))dx ∫ − ∞ ∞ N ( x ∣ u , σ 2 ) = ∫ − ∞ ∞ ( 2 π σ 2 ) 2 1 1 e x p ( − 2 σ 2 1 ( x − u ) ) d x
令 v = x − u v = x - u v = x − u
∫ − ∞ ∞ N ( x ∣ u , σ 2 ) = 1 ( 2 π σ 2 ) 1 2 ∫ − ∞ ∞ e x p ( − 1 2 σ 2 v ) d v = 1 \int_{-\infty}^\infty \mathcal{N}(x | u, \sigma^2) = \frac{1}{(2\pi\sigma^2)^{\frac12}} \int_{-\infty}^\infty exp(-\frac{1}{2\sigma^2}v)dv = 1 ∫ − ∞ ∞ N ( x ∣ u , σ 2 ) = ( 2 π σ 2 ) 2 1 1 ∫ − ∞ ∞ e x p ( − 2 σ 2 1 v ) d v = 1
1.8 高斯分布的期望与方差推导
E [ x ] = ∫ − ∞ ∞ N ( x ∣ μ , σ 2 ) = ∫ − ∞ ∞ 1 ( 2 π σ 2 ) 1 2 e x p ( − 1 2 σ 2 ( x − μ ) 2 ) x d x E[x] = \int_{-\infty}^\infty \mathcal{N}(x | \mu, \sigma^2) = \int_{-\infty}^\infty \frac{1}{(2\pi\sigma^2)^\frac12}exp(-\frac{1}{2\sigma^2}(x-\mu)^2)xdx E [ x ] = ∫ − ∞ ∞ N ( x ∣ μ , σ 2 ) = ∫ − ∞ ∞ ( 2 π σ 2 ) 2 1 1 e x p ( − 2 σ 2 1 ( x − μ ) 2 ) x d x
令 y = x − μ y = x-\mu y = x − μ
E [ x ] = ∫ − ∞ ∞ 1 ( 2 π σ 2 ) 1 2 e x p ( − 1 2 σ 2 y 2 ) ( y + μ ) d y E[x] = \int_{-\infty}^\infty \frac{1}{(2\pi\sigma^2)^\frac12}exp(-\frac{1}{2\sigma^2}y^2)(y+\mu)dy E [ x ] = ∫ − ∞ ∞ ( 2 π σ 2 ) 2 1 1 e x p ( − 2 σ 2 1 y 2 ) ( y + μ ) d y
由 y = x − μ y = x - \mu y = x − μ
E [ x ] = μ ∫ − ∞ ∞ N ( x ∣ u , σ 2 ) d x = μ E[x] = \mu \int_{-\infty}^\infty \mathcal{N}(x | u, \sigma^2) dx = \mu E [ x ] = μ ∫ − ∞ ∞ N ( x ∣ u , σ 2 ) d x = μ
1.9 高斯分布的众数(即概率最大值)推导
d N ( x ∣ μ , σ 2 ) d x = − N ( x ∣ μ , σ 2 ) x − μ σ 2 \frac{d\mathcal{N}(x | \mu, \sigma^2)}{dx} = - \mathcal{N}(x | \mu, \sigma^2) \frac{x-\mu}{\sigma^2} d x d N ( x ∣ μ , σ 2 ) = − N ( x ∣ μ , σ 2 ) σ 2 x − μ
当 x = μ x = \mu x = μ
1.10 独立变量相加的期望方差证明
由 x , z x, z x , z x + z x + z x + z p ( x ) p ( z ) p(x)p(z) p ( x ) p ( z )
E [ x + z ] = ∫ ( x + z ) p ( x ) p ( z ) d x d z = ∫ x p ( x ) d x + ∫ z p ( z ) d z = E [ x ] + E [ z ] E[x + z] = \int (x+z)p(x)p(z)dxdz = \int xp(x)dx + \int zp(z)dz = E[x] + E[z] E [ x + z ] = ∫ ( x + z ) p ( x ) p ( z ) d x d z = ∫ x p ( x ) d x + ∫ z p ( z ) d z = E [ x ] + E [ z ]
v a r [ x + z ] = E [ ( x + z ) 2 ] − E [ x + z ] 2 = E [ x 2 + z 2 + 2 x z ] − ( E [ x ] + E [ z ] ) 2 = E [ x 2 ] − E [ x ] 2 + E [ z 2 ] − E [ z ] 2 = v a r [ x ] + v a r [ z ] var[x+z] = E[(x+z)^2] - E[x+z]^2 \ = E[x^2 + z^2 + 2xz] - (E[x] + E[z])^2 \ = E[x^2] - E[x]^2 + E[z^2] - E[z]^2 \ = var[x] + var[z] v a r [ x + z ] = E [ ( x + z ) 2 ] − E [ x + z ] 2 = E [ x 2 + z 2 + 2 x z ] − ( E [ x ] + E [ z ] ) 2 = E [ x 2 ] − E [ x ] 2 + E [ z 2 ] − E [ z ] 2 = v a r [ x ] + v a r [ z ]
1.11