知识图谱专栏
-
知识图谱已经在工业应用上取得了不错的成绩,最开始由Google在2012提出运用在Google搜索上,后续百度、搜狗等公司陆续发布自己的知识图谱。在人工智能的发展历史上,知识图谱占据着非常重要的地位。深度学习作为近几年研究热点,在图像处理,自然语言处理上都取得了不错的成绩,但是深度学习缺乏推理、理解能力,而知识图谱的优势正好在于此,自然语言处理发展到自然语言理解,这个过程中知识图谱也会起到关键性的作用。下面主要分为以下12个方面,记录知识图谱相关知识:
- 知识表示与建模
- 基于符号的知识图谱表示方法
- 知识表示学习
- 实体识别与链接
- 实体关系学习
- 事件知识学习
- 知识推理
- 知识储存与查询
- 通用与领域知识图谱
- 语义集成
- 语义搜索
- 基于知识的问答系统
-
知识表示与建模
知识表示的定义:现实世界的可计算模型。
知识表示的特点以及用途:
- 客观事物的机器指示
- 本体约定和概念模型,定义用于描述客观事物和概念和类别体系
- 能提供给机器推理的模型和方法
- 具有高效的计算能力
- 是人可以理解的语言
现在知识表示大致可以分为离散的符号知识表示和连续的向量知识表示

基于符号的知识图谱表示方法
- RDF(Resource Description Framework)
- 在形式上表述为SPO三元组
- 形式化的方法包括:
- RDF/XML:使用XML格式来表示,缺点是冗长,不方便阅读
- N-Triples:多个三元组表示,如DBpedia
- Turtle:会在描述的时候加上前缀对RDF的IRI进行缩写
- RDFa: HTML5的扩展
- JSON-LD
- RDFS(Resource Description Framework Schema)
- 相对RDF增加了在概念、抽象层面的定义
- OWL(Web Ontology Language)
- 相对RDFS增加了数据属性以及对象属性
- OWL 2
- OWL2/EL:有大量相互链接的类和属性
- OWL2/QL:适合有大量实例的数据
- OWL2/RL:适合需要结合规则的推理引擎
基于向量的知识图谱表示学习方法
- 翻译模型
- 组合模型
- 神经网络模型Knowledge_Representation.png
-
实体识别与链接
传统统计模型方法
- 实体识别:形式化为从文本输入到特定目标结构的预测
- 最大熵分类
- SVM
- HMM
- 条件随机场
- 实体链接:计算实体提及和知识库当中实体的相似度
深度学习方法
- 实体识别:
- 基于NN-CRF架构进行序列标注
- 基于ngram判断目标是否是一个实体
- 实体链接
文本挖掘方法
- 代表性工作:DBPedia、TextRunner
-
实体关系学习
依靠人工构建的知识图谱:WordNet、HowNet、CYC
自动化生成知识图谱:Freebase、Yago、BDpedia
关系抽取的意义主要体现在为多种应用提供支持:
- 大规模知识图谱的自动化构建
- 对信息检索提供支持
- 对问答系统提供支持
- 自然语言理解相关技术
根据关系的类型关系抽取的方法可以分为:限定领域关系抽取、开放域关系抽取
根据关系抽取的方法分为:基于规则的关系抽取(预定义好关系)、基于机器学习的关系抽取
根据对监督知识的依赖程度分为:有监督关系抽取、无监督关系抽取、弱监督关系抽取
开放域关系抽取代表性工作:TextRunner、WOE、Kylin、Reverb、R2A2、OpenIE
基于规则的关系抽取缺点是召回率太低
无监督关系抽取:基于分布假设,核心是选取表示实体间的关系特征,然后再聚类。
有监督关系抽取:
- 通常将关系抽取看作是一个多分类的问题,可以分为给予特征向量的方法、基于核函数的方法、基于神经网络的方法
- 基于特征向量的方法:研究重点是如何提取具有区分性的特征
- 基于核函数的方法:将特征映射到高维空间计算隐式特征
- 基于神经网络的方法:需要体统自动的发现实体,需要大量的人工标注的语料
弱监督关系抽取:
- 使用半监督学习和主动学习等技术尽可能少的代价提升抽取效果
- 采用回标的思想, 基于现有知识库中的关系三元组,自动回标三元组中实体所在的文本作为训练数据
-
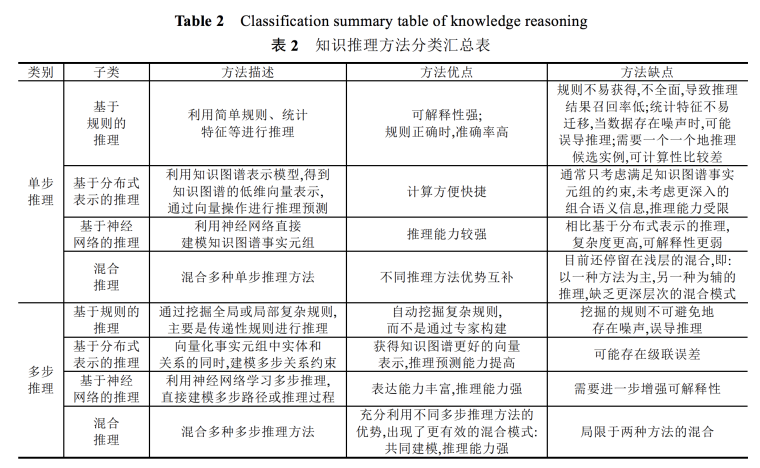
知识推理
知识推理主要用来解决知识图谱当中的两个问题:
- 知识图谱的不完备问题
- 知识图谱当中存在的错误
知识推理可以粗略的分为两种方式:
- 基于符号的推理,如基于经典逻辑(一阶谓词逻辑或命题逻辑)或经典逻辑变异(缺省逻辑)
- 基于本体的推理
- 基于规则的推理
- 基于统计的推理
知识推理的基本方法
- 基于传统规则的推理
- Spass-YAGO推理机:抽象化三元组到规则类,采用链式叠加计算关系的传递性
- TensorLog:每个实体关联一个ont-hot向量,进行矩阵运算
- 基于本体推理的方法
- 后面补充
- 基于转移的表示推理
- TransE模型:
- 思想:三元组当中:s向量+p向量 = o向量,有关信息更近、不相关的更远
- 缺点:无法处理多对一和一对多的关系、无法处理层级关系、只在单个图谱上做分析
- TransH模型:多学一个关系映射向量、将实体映射到关系指定的超平面再做运算,缓解多属性对应
- m-TransH模型
- TransR
- TransD
- TransM
- TransSparse
- TransA
- TransG
- KG2E
- 基于张量/矩阵分解的表示推理
- 基于空间分布的表示推理
- 基于神经网络的推理
- 混合规则与分布式表示的推理
- 混合神经网络和分布式表示的推理
- 基于全局结构的多步规则推理
- 引入局部结构的多步规则推理
- 基于分布式表示的多步推理
- 神经网络建模多步路径多步推理
- 神经网络模拟人脑的多步推理
- 混合PRA与分布式表示的多步推理
- 混合规则与分布式表示的多步推理
- 混合规则与神经网络的多步推理
知识图谱的表示
描述逻辑(description logic):针对概念描述的一系列逻辑语言
详细见知识表示与建模
基于符号的并行知识推理
重点解决以下两个问题:
- 单机环境下的多核、多处理器技术
- 多机环境下分布式技术
实体关系学习方法
- 基于表示学习的方法:将知识图谱中的实体与关系统一映射到低维连续向量空间,通过比较、匹配实体与关系的分布式表示得到潜在的实体间的关系。
- 基于图特征的方法
模式归纳方法
- 基于ILP的模式归纳方法
- 向下精化算子学习ACL
- 本体学习工具DL-Learner
- 基于关联规则挖掘的模式归纳方法
- 基于机器学习的模式归纳方法Knowledge_Inference.png
-
通用与领域知识图谱
通用知识图谱通常采用自底向上的构建方法,领域知识图谱通常采用自顶向下的构建方法,构建过程可以划分成六个部分:知识建模、知识获取、知识融合、知识存储、知识计算、知识应用。
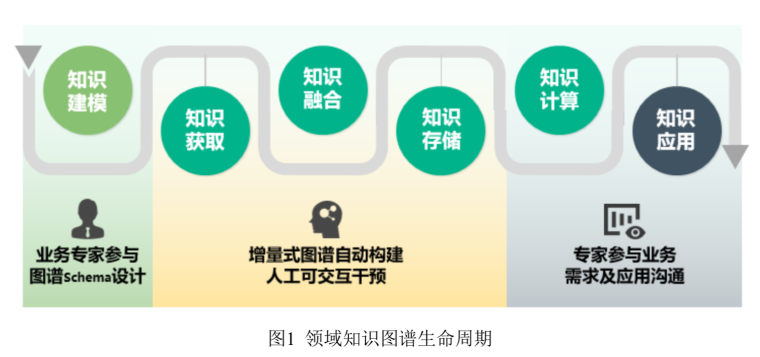
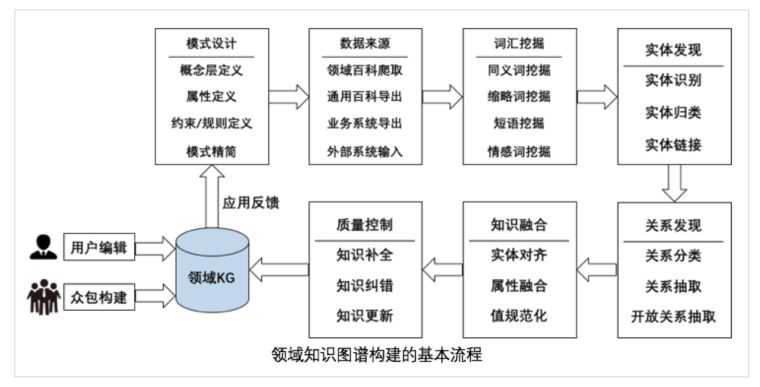
知识建模
- 自顶向下的知识建模: 首先定义数据模式,从最顶层开始构建,逐渐向下细化,有良好的分类再添加实体到对应的概念当中。
- 自底向上的知识建模:基于大量数据,首先对实体进行归纳组织,形成底层概念再逐层形成上层概念。
关键性问题:
- 如何描述知识体系以及知识点之间的关联关系
- 如何在冗余程度最低点的条件下满足应用和可视化展示
- 事件、时序等复杂知识表示,怎么进行描述,有什么优缺点
- 后续知识扩展的难度
自底向上的构建方法:
主要分为实体与概念学习、上下位关系学习、数据模式学习
-
实体与概念的抽取
针对半结构化的数据、如百科类的数据,通常使用文章标题作为实体的候选,将分类作为概念候选
-
实体对齐
-
数据模式的学习(概念属性学习)
自顶向下的构建方法:
主要工作在数据层面,可分为结构化数据的处理、半结构化的数据的处理、非结构化的数据处理
Reference
[Guarino,1995] Guarino N. Formal ontology, conceptual analysis and knowledge
representation[J]. International journal of human-computer studies, 1995, 43(5-6):
625-640.[Raisig et al,2009] Raisig S, Welke T, Hagendorf H, et al. Insights into knowledge
representation: The influence of amodal and perceptual variables on event
knowledge retrieval from memory[J]. Cognitive science, 2009, 33(7): 1252-1266.知识获取
如何从不同来源的信息当中提取出需要的知识,按照数据性质来分,可以分为结构化数据(数据库当中的数据)、半结构化数据(维基百科等)、非结构化数据(日常文本)。
- 结构化数据:重点关注数据关系的映射
- 半结构数据:如何解析
- 非结构化的数据:如何保证知识获取的准确性以及覆盖率
知识融合
将不同来源的知识进行对齐、合并。主要可以分为数据模式层面以及数据层面。
- 数据模式层面:概念层面,包括概念的上下位关系,概念的属性等。如“电脑”可以看作是一个概念,“CPU”、“硬盘”等可看作是下位关系,电脑重量、性能等可以看作是其属性。
- 数据层面:实体层面的融合。特定的某一台电脑就可以看作是一个实体,这个实习相应的一些属性等等进行融合,包括实体消歧,冲突检测等等。实体可以看作对本体的继承。
需要思考的问题:
- 如何进行高效的融合
- 如何对新增的知识进行及时的融合
- 多语言融合的问题
知识储存
针对特定的知识图谱设计出底层储存方式。大致可以分为单一储存和混合储存两种方式。
- 单一储存方式:通过三元组、属性表或垂直分割等方式进行知识储存
- 混合储存:利用多种单一储存方式混合
知识计算
知识的计算是知识图谱作为应用输出的关键部分。主要包含两种能力的输出:图挖掘计算、知识推理
- 图挖掘计算:实现对图谱的挖掘与探索。(主要针对图谱自身)
- 知识推理:主要用于知识发现、知识冲突、异常检测。又可以分为基于本体的推理以及基于规则的推理
知识应用
语义搜索、智能问答、可视化决策等都是其应用场景。
需要思考的一些问题:
- 如何基于数据特定,针对业务作出相应的调优工作。
- 如何做到精确的语义解析
- 如何提升大规模图计算的算法效率
-
知识储存与查询
常用的储存方式是RDF,这是一个被用来设计提供一种描述信息的通用方法,如图是一个RDF表示Aristotle的相关信息,包含其相关属性,以及他与其他实体的关系。
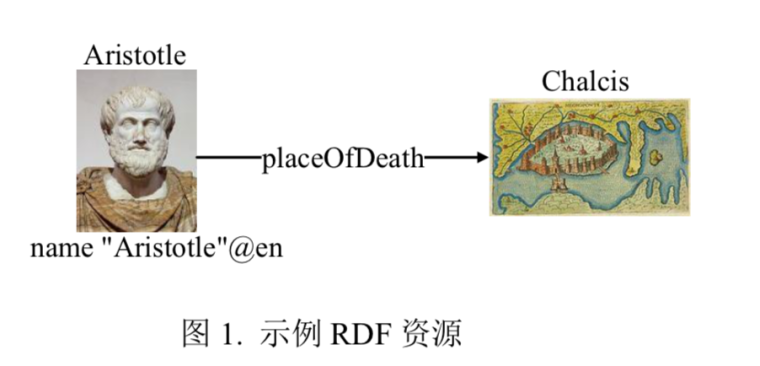
不管是属性,还是关系,都可以通过一系列的三元组信息去表示,图示为相关三元组表示信息
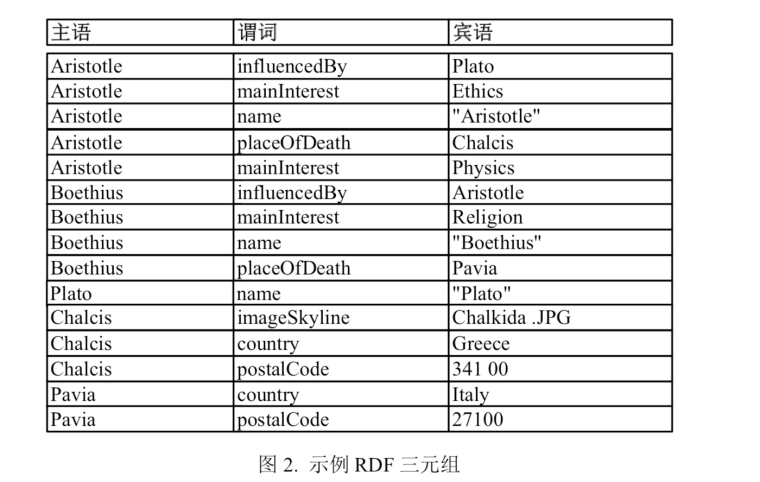
针对这些数据,具体的存储方式可以分为以下几种:
- 三列表储存
- 使用一些关系数据库用来维护一张巨大的三元组表,将SPARQL查询转换成SQL查询
- 这种方法的通用性比较好,但是查询的性能很差
- 水平储存
- 将知识图谱当中的每个RDF表示为数据库当中的一行,表的列包括RDF当中的所有属性
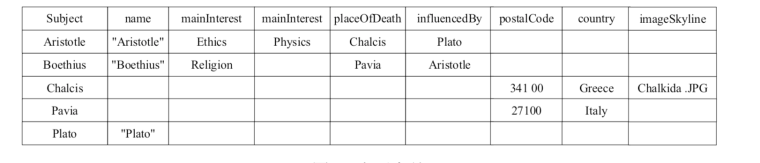
- 这种方法设计简单,容易回答面向面向某个主体的属性查询
- 表非常稀疏造成性能损失,不方便储存一个属性多个值问题,在数据变化的时候会带来很大的变化成本问题
- 属性表储存
- 在维护单张大的三元组表的基础上,通过聚类的方式将相似的三元组聚类,将每个聚类的三元组统一到一张属性表中进行管理,也可以通过分类的方法维护属性表
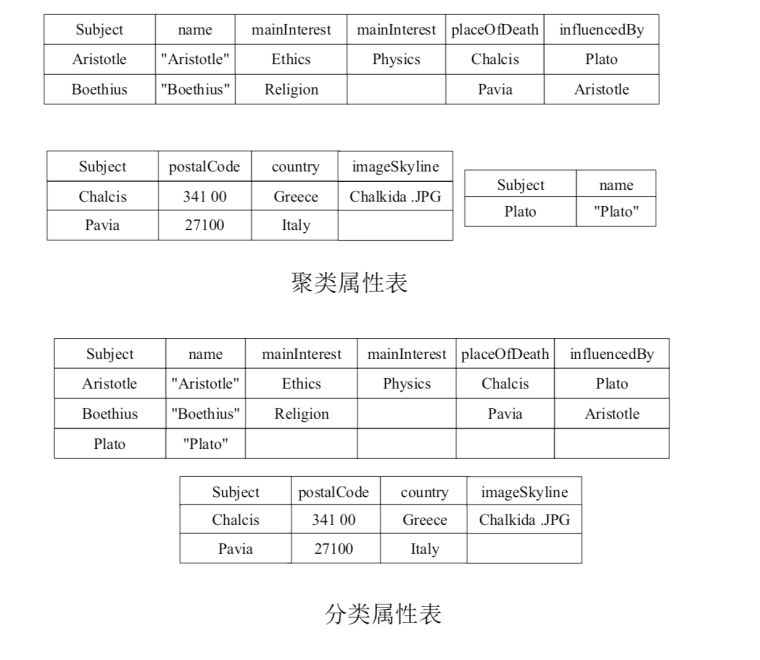
- 全索引
- 将三元组在主体、属性、客体之间各种排列下能够形成的各种形态枚举构建出来,然后构建相关索引
- 可能会浪费很多储存空间;复杂的查询需要大量的表连接操作;随着数据量的增大,表的规模不断扩大,性能严重下降
- 图模型的储存查询
- SPARQL的查询可以看作是在数据图上搜索相关的子图
Neo4j图数据库
CQL代表Cypher查询语言,Neo4j使用CQL作为查询语言
常用的Neo4j CQL命令有:
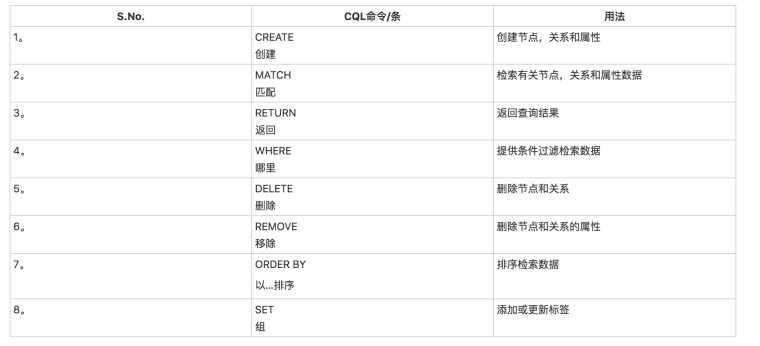
常用的Neo4j CQL函数:

Neo4j支持的数据类型:
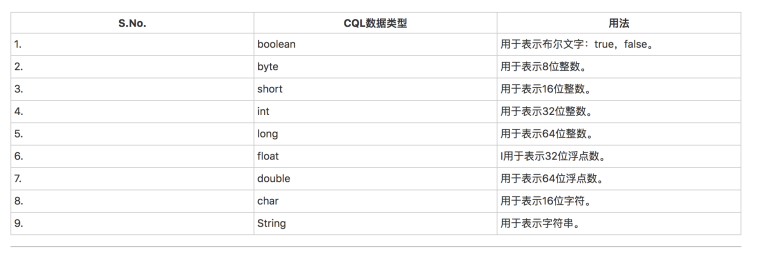
Neo4j 支持的布尔运算符:

Neo4j支持的比较运算符:

Neo4j支持的字符串函数:

Neo4j支持的聚合函数:

Neo4j支持的关系函数:

- CREAT命令
- 用来创建没有属性的节点,没有任何的关系与属性 ,命令语法为CREATE (<node-name>:<label-name>)
- <node-name>:要创建的节点名称
- <label-name>:节点标签名称
- 用来创建具有属性的节点,命令语法为CREATE (<node-name>:<label-name>{<Property1-name>:<Property1-Value>…….})
- 从单个标签到关系,命令语法CREATE (<node1-name>:<label1-name>-[(<relationship-name>:<relationship-label-name>)]->(<node2-name>:<label2-name>))
- MATCH命令
- 用来从数据库中获取节点、属性、关系的数据,命令语法MATCH (<node-name>:<label-name>)
- RETURN命令
- 检索节点的某些属性、所有属性、关联关系的某些属性,命令语法RETURN <node-name>.<property-name>,…….<node-name>.<propertyn-name>
- WHERE子句
- 用来过滤MATCH查询结果
- WHERE <condition>
- WHERE <condition> <boolean-operator> <condition>
- <condition>语法:<property-name> <comparison-operator> <value>
- <property-name>: 节点或关系的属性名
- <comparison-operator>: 比较运算符
- DELETE删除
- 删除节点和关联关系,命令:DELETE <node-name-list>
- REMOVE删除
- 删除标签和属性,命令:REMOVE <property-name-list>
- SET子句
- 向现有的节点或关系添加新属性,命令:SET <property-name-list>
- ORDER BY子句
- 对返回结果进行排序,命令:ORDER BY <property-name-list> [DESC]
- UNION
- UNION子句:将两组结果中的公共行合并返回到一组结果当中,不从两个节点返回重复行
- UNION ALL子句:结合并返回两个结果所有行成一个单一的结果集,还返回由两个节点的重复行
- LIMIT
- 用来限制返回的行数,修剪查询结果底部的结果,命令: LIMIT <number>
- SKIP
- 用来限制返回的行数,修剪查询结果顶部的结果,命令:SKIP <number>
- MERGE合并
- 用来创建节点,关系,属性
- MERGE (<node-name>:<label-name> {<Property-name>:<Property-Value>})
- 完成了创建节点,查询所有相关配置节点信息并返回