详解XLNET: Generalized Autoregressive Pretraining for Language Understanding论文笔记
-
公式完成版在我的博客
Title: XLNet: Generalized Autoregressive Pretraining for Language Understanding.
1. Introduction
1.1 AE && AR
无监督表征学习已经在自然语言处理领域取得了巨大的成功。在这种理念下,很多研究探索了不同的无监督预训练目标,其中,自回归(AR)语言建模和自编码(AE)成为两个最成功的预训练目标。
AR 语言建模旨在利用自回归模型估计文本语料库的概率分布。由于 AR 语言模型仅被训练用于编码单向语境(前向或后向),因而在深度双向语境建模中效果不佳。而下游语言理解任务通常需要双向语境信息。这导致 AR 语言建模无法实现有效预训练。
相反,基于 AE 的预训练模型不会进行明确的密度估计,而是从残缺的输入中重建原始数据。一个著名的例子就是 BERT。给出输入 token 序列,BERT 将一部分 token 替换为特殊符号 [MASK],随后训练模型从残缺版本恢复原始的 token。由于密度估计不是目标的一部分,BERT 允许使用双向语境进行重建。
但是,模型微调时的真实数据缺少 BERT 在预训练期间使用的 [MASK] 等人工符号,这导致预训练和微调之间存在差异。此外,由于输入中预测的 token 是被 mask 的,因此 BERT 无法像自回归语言建模那样使用乘积法则(product rule)对联合概率进行建模。
换言之,给定未 mask 的 token,BERT 假设预测的 token 之间彼此独立,这被过度简化为自然语言中普遍存在的高阶、长期依赖关系。
1.2 generalized autoregressive method
本文结合AR LM和AE LM,在Transformer-XL的基础上提出generalized autoregressive method,XLNet。
- 所有的分解序列作为一个集合,对所有采样序列,XLNet按照AR LM的计算方式求对数似然期望的极大值。通常,当前token的上文包含left和right的tokens:比如原始序列为1-2-3-4,分解序列中采样一个为2-4-1-3,那么如果当前token为3,XLNet的方式就可以看到所有的信息【当然这也是理想情况】,而AR LM只能看到1和2。
- 引入Transformer-XL的segment recurrence mechanism和relative encoding scheme。
- 引入Masked Two-Stream Self-Attention解决PLM出现的目标预测歧义【the ambiguity in target prediction】问题。举个例子,比如分解序列中采样一个为2-4-6-1-3-5的序列,假设要预测**位置[1]**的token,按照经典的Transformer来计算next-token的概率分布,位置[1]的token的概率就是通过[2,4,6]位置上的tokens来计算。但是如果以这种方式去预测next-token,这对[3,5]的预测就会产生影响,因为如果[1]的预测出现错误会把错误传给后面。对后面每一个token的预测,需要建立在之前token都已知的条件下。因此本文计算了两个self-attention计算方式,一个mask当前词,attention值记为
;一个已知当前词,attention值记为 。最后假设self-attention一共有M层,用第M层、t时刻的 ,去预测词 。
2. Proposed Method
2.1 Background
首先,我们先温习一下传统的AR模型和BERT。给定文本序列
,语言模型(AR)的目标是调整参数使得训练数据上的似然函数最大: 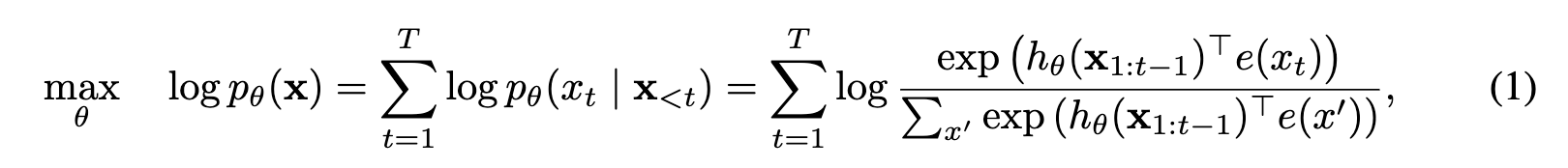
记号
$x<t$表示t时刻之前的所有x,也就是 $$x_{1:t−1}$$。 $$h_θ(x_{1:t−1})$$是RNN或者Transformer。 是词x的embedding。 而BERT是去噪(denoising)自编码的方法。对于序列
,BERT会随机挑选15%的Token变成[MASK]得到带噪声版本的 。假设被Mask部分的原始值为 ,那么BERT希望尽量根据上下文恢复(猜测)出原始值了,也就是 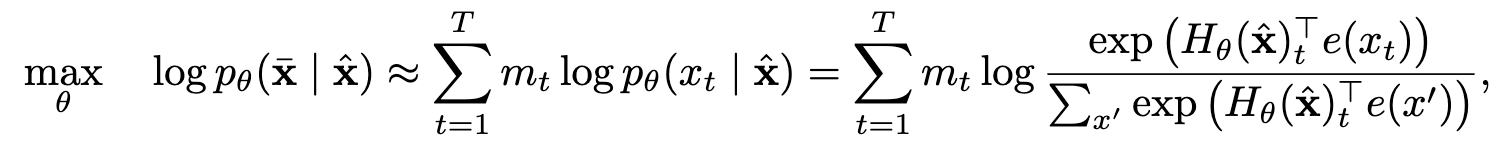
上面的公式中,
表示t时刻是一个Mask, 是一个Transformer,它把长度为T的序列 映射为隐状态的向量序列 。 这两个模型的优缺点分别为:
-
独立假设:注意等式 (2) 的约等号 ≈,它的意思是假设在给定的条件下被 Mask 的词是独立的(没有关系的),这个显然并不成立,比如”New York is a city”,假设我们 Mask 住”New”和”York”两个词,那么给定”is a city”的条件下”New”和”York”并不独立,因为”New York”是一个实体,看到”New”则后面出现”York”的概率要比看到”Old”后面出现”York”概率要大得多。而公式 (1) 没有这样的独立性假设,它是严格的等号。
-
输入噪声:BERT 的在预训练时会出现特殊的 [MASK],但是它在下游的 fine-tuning 中不会出现,这就是出现了不匹配。而语言模型不会有这个问题。
-
双向上下文:语言模型只能参考一个方向的上下文,而 BERT 可以参考双向整个句子的上下文,因此这一点 BERT 更好一些。
ELMo和GPT最大的问题就是传统的语言模型是单向的——我们是根据之前的历史来预测当前词。但是我们不能利用后面的信息。比如句子”The animal didn’t cross the street because it was too tired”。我们在编码it的语义的时候需要同时利用前后的信息,因为在这个句子中,it可能指代animal也可能指代street。根据tired,我们推断它指代的是animal,因为street是不能tired。但是如果把tired改成wide,那么it就是指代street了。传统的语言模型,不管是RNN还是Transformer,它都只能利用单方向的信息。比如前向的RNN,在编码it的时候它看到了animal和street,但是它还没有看到tired,因此它不能确定it到底指代什么。如果是后向的RNN,在编码的时候它看到了tired,但是它还根本没看到animal,因此它也不能知道指代的是animal。Transformer的Self-Attention理论上是可以同时attend to到这两个词的,但是根据前面的介绍,由于我们需要用Transformer来学习语言模型,因此必须用Mask来让它看不到未来的信息,所以它也不能解决这个问题的。注意:即使ELMo训练了双向的两个RNN,但是一个RNN只能看一个方向,因此也是无法”同时”利用前后两个方向的信息的。也许有的读者会问,我的RNN有很多层,比如第一层的正向RNN在编码it的时候编码了animal和street的语义,反向RNN编码了tired的语义,然后第二层的RNN就能同时看到这两个语义,然后判断出it指代animal。理论上是有这种可能,但是实际上很难。举个反例,理论上一个三层(一个隐层)的全连接网络能够拟合任何函数,那我们还需要更多层词的全连接网络或者CNN、RNN干什么呢?如果数据不是足够足够多,如果不对网络结构做任何约束,那么它有很多中拟合的方法,其中很多是过拟合的。但是通过对网络结构的约束,比如CNN的局部特效,RNN的时序特效,多层网络的层次结构,对它进行了很多约束,从而使得它能够更好的收敛到最佳的参数。我们研究不同的网络结构(包括resnet、dropout、batchnorm等等)都是为了对网络增加额外的(先验的)约束。
2.2 Objective: Permutation Language Modeling
从上面的比较可以得出,AR 语言建模和 BERT 拥有其自身独特的优势。我们自然要问,是否存在一种预训练目标函数可以取二者之长,同时又克服二者的缺点呢?
作者借鉴了无序 NADE 中的想法,提出了一种序列语言建模目标,它不仅可以保留 AR 模型的优点,同时也允许模型捕获双向语境。具体来说,一个长度为 T 的序列 x 拥有 T! 种不同的排序方式,可以执行有效的自回归因式分解。从直觉上来看,如果模型参数在所有因式分解顺序中共享,那么预计模型将学习从两边的所有位置上收集信息。
为了提供一个完整的概览图,研究者展示了一个在给定相同输入序列 x(但因式分解顺序不同)时预测 token
的示例,如下图所示:比如图的左上,对应的分解方式是3→2→4→1,因此预测 是不能attend to任何其它词,只能根据之前的隐状态mem来预测。而对于左下, 可以attend to其它3个词。 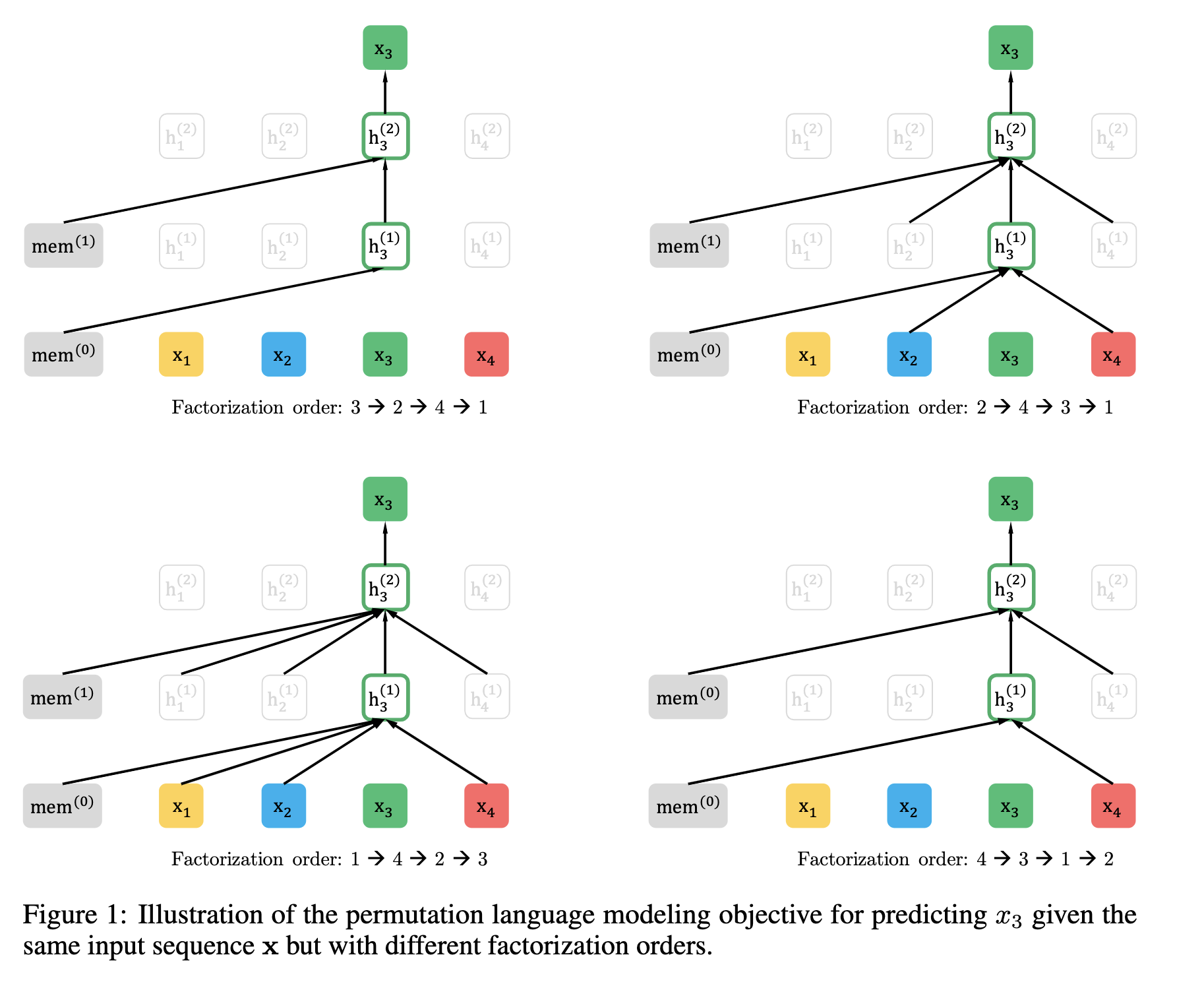
给定长度为T的序列x,总共有T!种排列方法,也就对应T!种链式分解方法。比如假设
,那么总共用3!=6种分解方法: 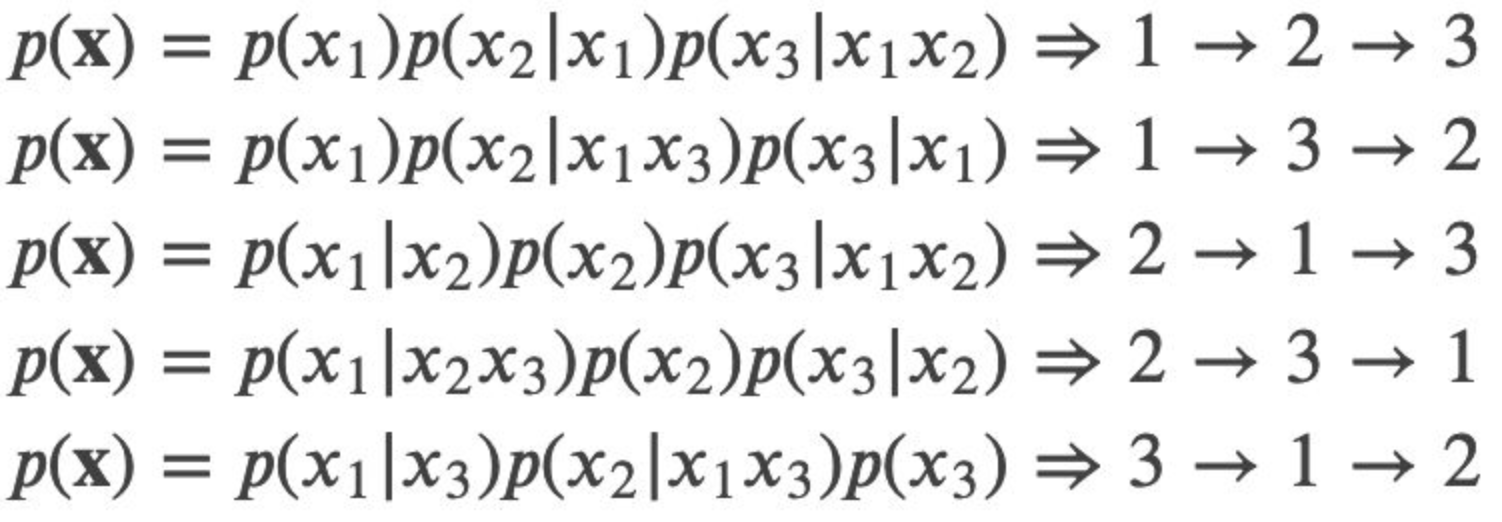
如果我们的语言模型遍历T!种分解方法,并且这个模型的参数是共享的,那么这个模型应该就能(必须)学习到各种上下文。普通的从左到右或者从右往左的语言模型只能学习一种方向的依赖关系,比如先”猜”一个词,然后根据第一个词”猜”第二个词,根据前两个词”猜”第三个词,……。而排列语言模型会学习各种顺序的猜测方法,比如上面的最后一个式子对应的顺序3→1→2,它是先”猜”第三个词,然后根据第三个词猜测第一个词,最后根据第一个和第三个词猜测第二个词。
因此我们可以遍历T!种路径,然后学习语言模型的参数,但是这个计算量非常大。因此实际我们只能随机的采样T!里的部分排列,为了用数学语言描述,我们引入几个记号。
表示长度为T的序列的所有排列组成的集合,则 是一种排列方法。我们用 表示排列的第t个元素,而 $$\mathbf{z}_{<t}$$表示z的第1到第t-1个元素。(论文里设定:统共T种,如何采样的并没有说,只是说大概率上下文会出现在被预测词的前面) PLM的目标是调整模型参数使得下面的似然概率最大:
$$
\max {\theta} \quad \mathbb{E}{\mathbf{z} \sim \mathcal{Z}{T}}\left[\sum{t=1}^{T} \log p_{\theta}\left(x_{z_{t}} | \mathbf{x}{\mathbf{z}{<t}}\right)\right]
$$
这样pretrain和finetune阶段就一样了,输入都是原始序列,通过attention mask实现随机产生的排列。例如排列是2-4-3-1,那么在预测X3的时候就只有2、4作为先验,并且2、4的位置信息是通过来体现的,这样也保留了排列的时序信息。 注意:上面的模型只会遍历概率的分解顺序,并不会改变原始词的顺序。实现是通过Attention的Mask来对应不同的分解方法。比如
,我们可以在用Transformer编码 时候让它可以Attend to ,而把 Mask掉;编码 的时候把 都Mask掉。 2.3 Architecture: Two-Stream Self-Attention for Target-Aware Representations
虽然PLM具有所需的属性,但是使用简单的标准Transformer的参数设定可能无法工作。可以看到,给定排列 z,我们需要使用标准正态分布计算
$$p_{\theta}\left(X_{z_{t}} | \mathbf{x}{\mathbf{z}<t}\right)$$,如果使用普通的Transformer,计算公式为:
$$ {\theta}\left(X_{z_{t}} | \mathbf{x}{\mathbf{z}<t}\right)=\frac{\exp \left(e(x)^{\top} h{\theta}\left(\mathbf{x}{\mathbf{z}<t}\right)\right)}{\sum{x^{\prime}} \exp \left(e\left(x^{\prime}\right)^{\top} h_{\theta}\left(\mathbf{x}{\mathbf{z}<t}\right)\right)}
p
$$
此时模型并不知道要预测的到底是哪个位置的词(知道位置信息会有更好的效果),为了解决这个问题,我们把预测的位置放到模型里:
$$ {\theta}\left(X_{z_{t}}=x | \mathbf{x}{z{<t}}\right)=\frac{\exp \left(e(x)^{\top} g_{\theta}\left(\mathbf{x}{\mathbf{z}{<t}}, z_{t}\right)\right)}{\sum_{x^{\prime}} \exp \left(e\left(x^{\prime}\right)^{\top} g_{\theta}\left(\mathbf{x}{\mathbf{z}{<t}}, z_{t}\right)\right)}
p
$$
上式中$$g_{\theta}(\mathbf{x}{\mathbf{z}{<t}}, z_{t})$$表示这是一个新的模型 g,并且它的参数除了之前的词 $$\mathbf{x}{\mathbf{z}{<t}}$$,还有要预测的词的位置 。 Two-Stream Self-Attention
表示
$$g_{\theta}(\mathbf{x}{\mathbf{z}{<t}}, z_{t})$$时,有很多可选的模型,我们这里通过位置 来从 context $$\mathbf{x}_{\mathbf{z}<t}$$里通过 Attention 机制提取需要的信息来预测这个位置的词。那么它需要满足如下两点要求: - 为了预测
, $$g_{\theta}(\mathbf{x}{\mathbf{z}{<t}}, z_{t})$$只能使用位置信息 而不能使用 。这是显然的:你预测一个词当然不能知道要预测的是什么词。 - 为了预测
$$𝑧_t$$之后的词, $$g_{\theta}(\mathbf{x}{\mathbf{z}{<t}}, z_{t})$$必须编码了 的信息(语义)。
但是上面两点要求对于普通的 Transformer 来说是矛盾的无法满足的。为了解决这个问题,论文引入了两个 Stream,也就是两个隐状态:
- 内容隐状态
$$h_{\theta}\left(\mathbf{x}{\mathbf{z}<t}\right)$$,简写为 ,它就会标准的 Transformer 一样,既编码上下文(context)也编码 的内容。 - 查询隐状态
$$g_{\theta}(\mathbf{x}{\mathbf{z}{<t}}, z_{t})$$,简写为 ,它只编码上下文和要预测的位置 ,但是不包含 。
计算流程:
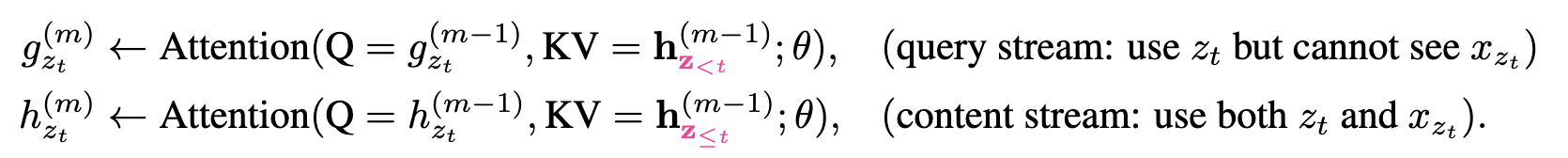
其中
,分别是随即初始化的query向量和content向量 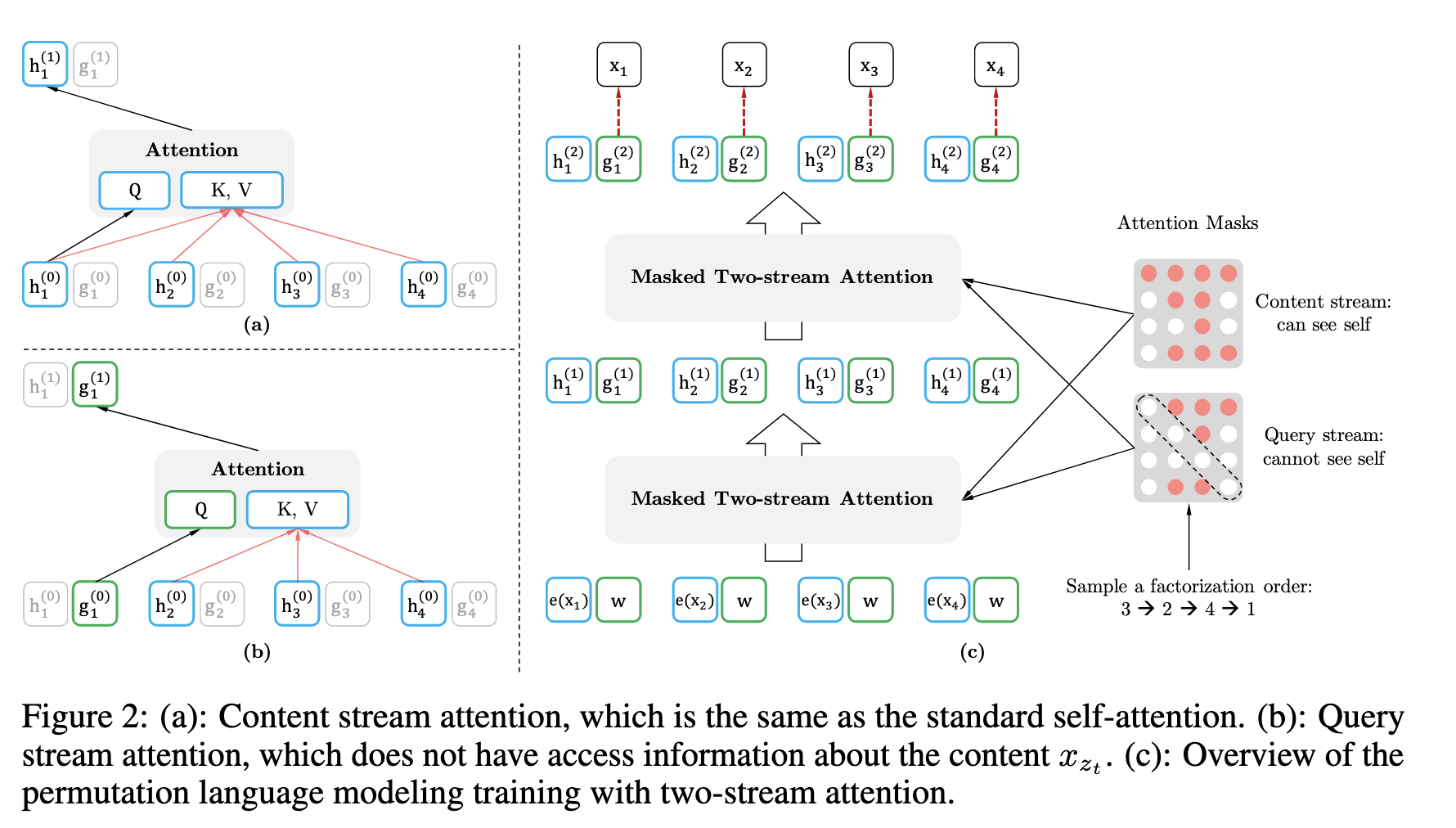
(a)代表context stream self-attention,以[1,t]时刻的词作为K、V,t时刻的词作为Q计算当前词的信息,把排列之后的原始序列信息用h记忆起来。
(b)代表query stream self-attention,mask掉当前词,以[1,t-1]时刻的词作为K、V,t时刻的词作为Q预测当前词,得到概率分布。
(c)代表通过多层的masked two-stream attention,最后用t时刻的
来预测 。 引入位置向量之后,最终在预训练的时候也没有每一个token都预测,作者设置了一个超参数K,其中c是分割点,𝑧≤𝑐 和 𝑧>𝑐,分别叫做 non-target 序列和 target 序列,
,设定只预测序列最后1/K=的词[c+1, |z|]: 
2.4 Incorporating Ideas from Transformer-XL
由于我们的目标函数符合AR框架,我们纳入了最先进的AR语言模型Transformer-XL进入我们的预培训框架,并以它命名我们的方法。我们集成了转换XL中的两个重要技术,即相对位置编码方案(relative positional encodingscheme)和分段递归机制(segment recurrence mechanism)。我们应用相对位置编码的基础上如前所述的原始序列,这很简单。现在我们讨论如何积分将递归机制引入到提出的置换设置中,使模型能够重用隐藏前一节的状态。
在不失一般性的前提下,假设我们有两个从长句子s中取出的segment
和 , 和 是序列[1,…,T]和[T+1,…,2T]的一种排列,基于 首先处理第一个segment,然后对每一层layer m缓存获得的表示内容 ,对于下一个segment,有如下更新: 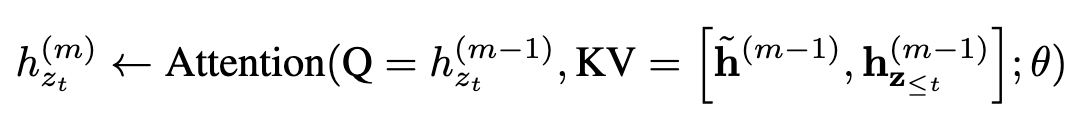
2.5 Modeling Multiple Segments
许多下游的任务会有多余一个输入序列,比如问答的输入是问题和包含答案的段落。下面我们讨论怎么在自回归框架下怎么预训练两个segment。和BERT一样,我们选择两个句子,它们有50%的概率是连续的句子(前后语义相关),有50%的概率是不连续(无关)的句子。我们把这两个句子拼接后当成一个句子来学习排列语言模型。输入和BERT是类似的:[A, SEP, B, SEP, CLS],这里SEP和CLS是特殊的两个Token,而A和B代表两个Segment。而BERT稍微不同,这里把CLS放到了最后。原因是因为对于BERT来说,Self-Attention唯一能够感知位置是因为我们把位置信息编码到输入向量了,Self-Attention的计算本身不考虑位置信息。而前面我们讨论过,为了减少计算量,这里的排列语言模型通常只预测最后1/K个Token。我们希望CLS编码所有两个Segment的语义,因此希望它是被预测的对象,因此放到最后肯定是会被预测的。
但是和BERT不同,我们并没有增加一个预测下一个句子的Task,原因是通过实验分析这个Task加进去后并不是总有帮助。【注:其实很多做法都是某些作者的经验,后面很多作者一看某个模型好,那么所有的Follow,其实也不见得就一定好。有的时候可能只是对某个数据集有效果,或者效果好是其它因素带来的,一篇文章修改了5个因素,其实可能只是某一两个因素是真正带来提高的地方,其它3个因素可能并不有用甚至还是有少量副作用。】
2.6 比较与分析
与BERT
XLNet和BERT都是预测一个句子的部分词,但是背后的原因是不同的。BERT使用的是Mask语言模型,因此只能预测部分词(总不能把所有词都Mask了然后预测?)。而XLNet预测部分词是出于性能考虑,而BERT是随机的选择一些词来预测。
除此之外,它们最大的区别其实就是BERT是约等号,也就是条件独立的假设——那些被MASK的词在给定非MASK的词的条件下是独立的。但是我们前面分析过,这个假设并不(总是)成立。下面我们通过一个例子来说明(其实前面已经说过了,理解的读者跳过本节即可)。
假设输入是[New, York, is, a, city],并且假设恰巧XLNet和BERT都选择使用[is, a, city]来预测New和York。同时我们假设XLNet的排列顺序为[is, a, city, New, York]。那么它们优化的目标函数分别为:
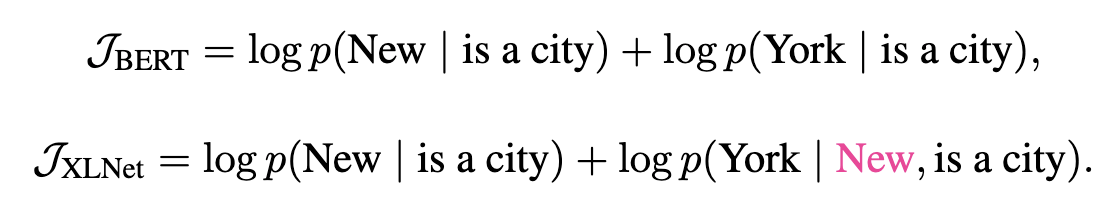
我们可以发现,XLNet可以在预测York的使用利用New的信息,因此它能学到”New York”经常出现在一起而且它们出现在一起的语义和单独出现是完全不同的。
摘自知乎:
与Bert的预训练过程的异同问题
尽管看上去,XLNet在预训练机制引入的Permutation Language Model这种新的预训练目标,和Bert采用Mask标记这种方式,有很大不同。其实你深入思考一下,会发现,两者本质是类似的。区别主要在于:Bert是直接在输入端显示地通过引入Mask标记,在输入侧隐藏掉一部分单词,让这些单词在预测的时候不发挥作用,要求利用上下文中其它单词去预测某个被Mask掉的单词;而XLNet则抛弃掉输入侧的Mask标记,通过Attention Mask机制,在Transformer内部随机Mask掉一部分单词(这个被Mask掉的单词比例跟当前单词在句子中的位置有关系,位置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),让这些被Mask掉的单词在预测某个单词的时候不发生作用。所以,本质上两者并没什么太大的不同,只是Mask的位置,Bert更表面化一些,XLNet则把这个过程隐藏在了Transformer内部而已。这样,就可以抛掉表面的[Mask]标记,解决它所说的预训练里带有[Mask]标记导致的和Fine-tuning过程不一致的问题。至于说XLNet说的,Bert里面被Mask掉单词的相互独立问题,也就是说,在预测某个被Mask单词的时候,其它被Mask单词不起作用,这个问题,你深入思考一下,其实是不重要的,因为XLNet在内部Attention Mask的时候,也会Mask掉一定比例的上下文单词,只要有一部分被Mask掉的单词,其实就面临这个问题。而如果训练数据足够大,其实不靠当前这个例子,靠其它例子,也能弥补被Mask单词直接的相互关系问题,因为总有其它例子能够学会这些单词的相互依赖关系。
我相信,通过改造Bert的预训练过程,其实是可以模拟XLNet的Permutation Language Model过程的:Bert目前的做法是,给定输入句子X,随机Mask掉15%的单词,然后要求利用剩下的85%的单词去预测任意一个被Mask掉的单词,被Mask掉的单词在这个过程中相互之间没有发挥作用。如果我们把Bert的预训练过程改造成:对于输入句子,随机选择其中任意一个单词Ti,只把这个单词改成Mask标记,假设Ti在句子中是第i个单词,那么此时随机选择X中的任意i个单词,只用这i个单词去预测被Mask掉的单词。当然,这个过程理论上也可以在Transformer内采用attention mask来实现。如果是这样,其实Bert的预训练模式就和XLNet是基本等价的了。
或者换个角度思考,假设仍然利用Bert目前的Mask机制,但是把Mask掉15%这个条件极端化,改成,每次一个句子只Mask掉一个单词,利用剩下的单词来预测被Mask掉的单词。那么,这个过程其实跟XLNet的PLM也是比较相像的,区别主要在于每次预测被Mask掉的单词的时候,利用的上下文更多一些(XLNet在实现的时候,为了提升效率,其实也是选择每个句子最后末尾的1/K单词被预测,假设K=7,意味着一个句子X,只有末尾的1/7的单词会被预测,这意味着什么呢?意味着至少保留了6/7的Context单词去预测某个单词,对于最末尾的单词,意味着保留了所有的句子中X的其它单词,这其实和上面提到的Bert只保留一个被Mask单词是一样的)。或者我们站在Bert预训练的角度来考虑XLNet,如果XLNet改成对于句子X,只需要预测句子中最后一个单词,而不是最后的1/K(就是假设K特别大的情况),那么其实和Bert每个输入句子只Mask掉一个单词,两者基本是等价的。
当然,XLNet这种改造,维持了表面看上去的自回归语言模型的从左向右的模式,这个Bert做不到,这个有明显的好处,就是对于生成类的任务,能够在维持表面从左向右的生成过程前提下,模型里隐含了上下文的信息。所以看上去,XLNet貌似应该对于生成类型的NLP任务,会比Bert有明显优势。另外,因为XLNet还引入了Transformer XL的机制,所以对于长文档输入类型的NLP任务,也会比Bert有明显优势。
Conclusion
自词向量到如今以 XLNet 为代表的预训练语言模型,他们的主要区别在于对语境的不同粒度的建模:
XLNet 的成功来自于三点:
- 分布式语义假设的有效性,即我们确实可以从语料的统计规律中习得常识及语言的结构。
- 对语境更加精细的建模:从"单向"语境到"双向"语境,从"短程"依赖到"长程"依赖,XLNet 是目前对语境建模最精细的模型。
- 在模型容量足够大时,数据量的对数和性能提升在一定范围内接近正比。XLNet 使用的预训练数据量可能是公开模型里面最大的。
可以预见的是资源丰富的大厂可以闭着眼睛继续顺着第三点往前走,或许还能造出些大新闻出来,这也是深度学习给的承诺。这些大新闻的存在也渐渐堵住调参式的工作的未来,迫使研究者去思考更加底层,更加深刻的问题。
参考链接:
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/94416878
https://zhuanlan.zhihu.com/p/70220951
https://zhuanlan.zhihu.com/p/70257427
https://www.zhihu.com/search?type=content&q=XLNET