小结
TCP 是一个可靠的(reliable)、面向连接的(connection-oriented)、基于字节流(byte-stream)、全双工(full-duplex)的协议。发送端在发送数据以后启动一个定时器,如果超时没有收到对端确认会进行重传,接收端利用序列号对收到的包进行排序、丢弃重复数据,TCP 还提供了流量控制、拥塞控制等机制保证了稳定性。
TCP 是一种字节流(byte-stream)协议,流的含义是没有固定的报文边界。
假设调用 2 次 write 函数往 socket 里依次写 500 字节、800 字节。write 函数只是把字节拷贝到内核缓冲区,最终会以多少条报文发送出去是不确定的,如下图所示
上面出现的情况取决于诸多因素:路径最大传输单元 MTU、发送窗口大小、拥塞窗口大小等。
当接收方从 TCP 套接字读数据时,它是没法得知对方每次写入的字节是多少的。接收端可能分2 次每次 650 字节读取,也有可能先分三次,一次 100 字节,一次 200 字节,一次 1000 字节进行读取。
IP 是一种无连接、不可靠的协议:它尽最大可能将数据报从发送者传输给接收者,但并不保证包到达的顺序会与它们被传输的顺序一致,也不保证包是否重复,甚至都不保证包是否会达到接收者。
TCP 要想在 IP 基础上构建可靠的传输层协议,必须有一个复杂的机制来保障可靠性。 主要有下面几个方面:
校验和(checksum) 每个 TCP 包首部中都有两字节用来表示校验和,防止在传输过程中有损坏。如果收到一个校验和有差错的报文,TCP 不会发送任何确认直接丢弃它,等待发送端重传。
包的序列号保证了接收数据的乱序和重复问题 假设我们往 TCP 套接字里写 3000 字节的数据导致 TCP发送了 3 个数据包,每个数据包大小为 1000 字节:第一个包序列号为[1~1001),第二个包序列号为 [1001~2001),第三个包序号为[2001~3001)
假如因为网络的原因导致第二个、第三个包先到接收端,第一个包最后才到,接收端也不会因为他们到达的顺序不一致把包弄错,TCP 会根据他们的序号进行重新的排列然后把结果传递给上层应用程序。
如果 TCP 接收到重复的数据,可能的原因是超时重传了两次但这个包并没有丢失,接收端会收到两次同样的数据,它能够根据包序号丢弃重复的数据。
超时重传 TCP 发送数据后会启动一个定时器,等待对端确认收到这个数据包。如果在指定的时间内没有收到 ACK 确认,就会重传数据包,然后等待更长时间,如果还没有收到就再重传,在多次重传仍然失败以后,TCP 会放弃这个包。
前段时间组内分享会的时候,学长学姐们从分层模型开始,介绍了一些计网的内容。所以我回来后自己了解了一下相关知识,本篇将从TCP协议的概述开始。如有错误或表述不妥的地方,欢迎指正。
面向连接的协议。
建立连接的过程是通过「三次握手」来完成的,顾名思义,通过三次数据交换建立一个连接。 通过三次握手协商好双方后续通信的起始序列号、窗口缩放大小等信息。
如下图所示
@unrealluver 思想我大概明白啦,谢谢学长!(就是担心向量相乘之后大部分得到的都是0...有时间的时候我来试试看
总而言之,我认为这些现成的分析工具只适用于两种情况:
但如果是想针对某一学者的所有论文信息分析出他/她的研究方向的话,我觉得VOSviewer可能就不太行了...但可能也和数据集大小有关,我选的那位学者我只拿到了90+论文的文献信息,所以分析结果看不出什么来。如果是那种paper上千的大牛,拿到其所有论文的文献信息的话,应该也会效果不错?
@ryougi 我上周看见收到了回复但一直没找出时间好好回...最近实验实在太多了QAQ不好意思
直接在web of science数据库里检索“地热”词条然后导出的数据
这样导出的数据在基于abstract和title的分析情况下,如果信息条数足够多,应该还是能看出一点效果来的。不过这种做法通常是用来分析某一领域今年来的研究热点:导出某一领域在某段时间内的高引或热点论文。这里有一个例子:基于文献计量的大数据研究现状分析 这样的情况下用VOSviewer等现成的分析工具是能得到不错的效果。
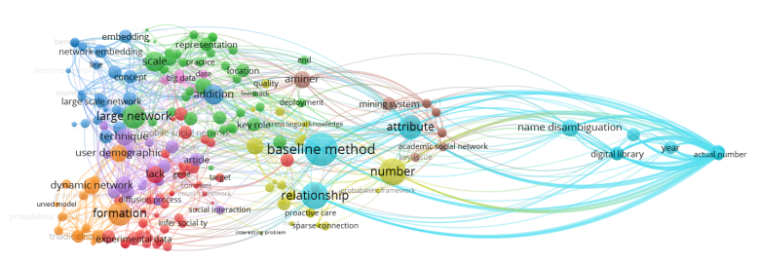
我后来自己实验的时候换了一种方法,从CNKI上导出了data mining、social network、natural language processing、semantic network、predictive model这五个研究方向下各100条文献信息进行分析,然后VOSviewer得到了一张这样的图:
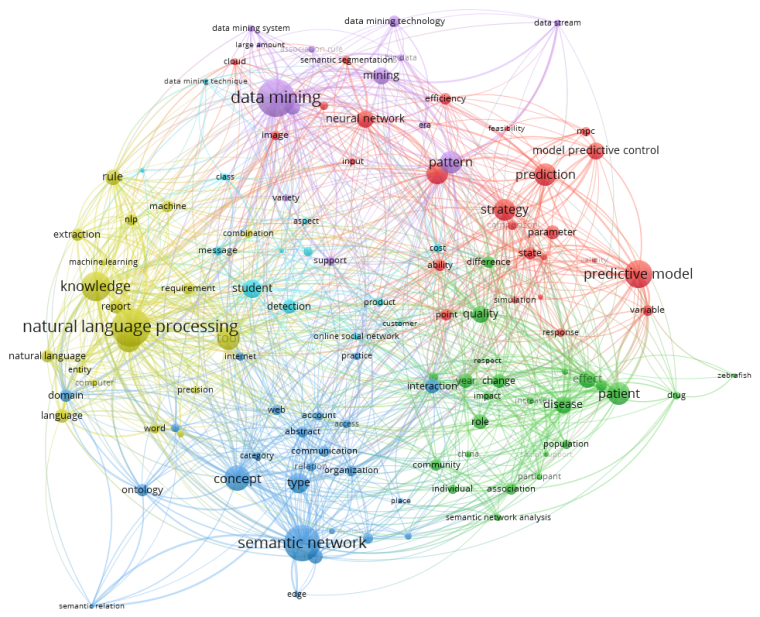
分析结果和我筛选数据时的选择基本吻合。
@chivas 在 Neo4j与Cypher语言学习笔记(一) 中说:
不过不是因为连线混论,而是VOSviewer根据聚类结果画出来的图看不出来研究领域...类似这种
请问学长最后对于获得研究方向的关系图有什么想法吗?
用VOSviewer分析abstract和title才会看出一点效果来...这张图就是的,因为abstract中才看得出上下文,能计算词出现的频率和关联度
@ryougi 在 Neo4j与Cypher语言学习笔记(一) 中说:
@chivas
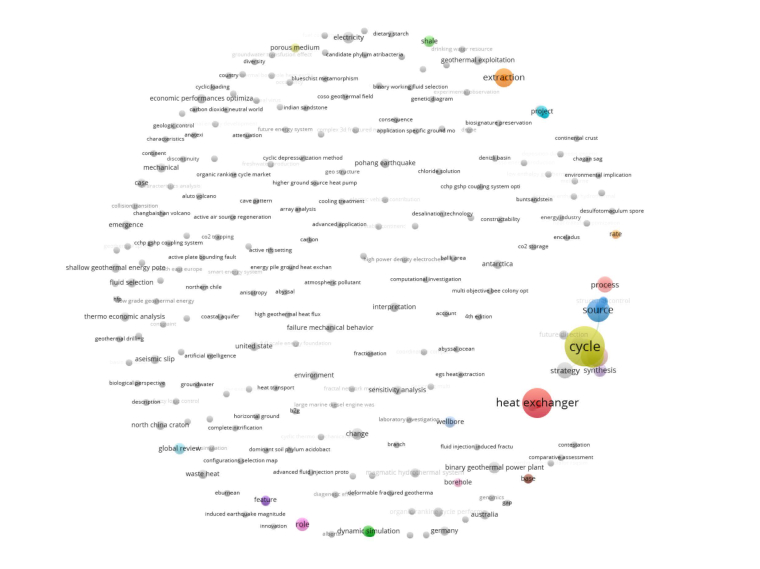
这个是我用VOSviewer绘制的关于“地热”的相关研究方向的图,我是直接在web of science数据库里检索“地热”词条然后导出的数据,然后直接丢到VOSviewer里面了。我记得配置里面好像有一项是过滤最小的关联子图,我好像是把那一项设置成1了结果所有的都显示出来了......但是如果我把那个设到最大,就只会显示图中右边这一个部分的子图,而且词条之间隔得很远,有什么好的解决方案吗(还是说我的使用方法不太对)
你选的是based on text data还是bibliographic data啊?从图上看好像是bibliographic中的keyword...如果是这样的话很正常,因为VOSviewer是基于共现的,也就是说看一句话里几个词同时出现的频率和距离情况...而如果你选的是基于keyword分析的话,最后的结果当然大部分是一个个孤立且频次为1的词
目前数据处理大致可以分成两大类:在线事务处理OLTP(On-Line transaction processing)、在线分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
- Online transaction processing shortly known as OLTP supports transaction-oriented applications in a 3-tier architecture. OLTP administers day to day transaction of an organization.
- The primary objective is data processing and not data analysis.
在线事务处理,表示事务性非常高的系统。
OLTP管理组织的日常事务(“事务”是导致数据创建、更新、删除或检索的事件)。典型的OLTP系统应用有自动取款机、购物中心、电子商务系统、在线预定火车和航班等。
例如以大型商店为例,某人购买15种产品,然后去柜台付款。现在是OLTP系统将负责将要发生的事务,让我们计算一下可能发生的事务数量:
- Online Analytical Processing, a category of software tools which provide analysis of data for business decisions. OLAP systems allow users to analyze database information from multiple database systems at one time.
- The primary objective is data analysis and not data processing.
在线分析处理系统,有时也叫
DSS决策支持系统 ,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。OLAP系统允许用户同时分析来自多个数据库的数据,因此,在将它们存储到数据仓库之前,必须执行ETL处理(Extraction-Transformation-Loading)。把数据预处理成数据立方(Cube),并把有可能的汇总都预先算出来(即预聚合处理),然后在用户选择多维度汇总时,在预先的计算出来的数据基础上很快地计算出用户想要的结果,从而可以更好更快地支持极大数据量的及时分析。
(在了解了DB和DM的区别后再看OLTP和OLAP的区别就会觉得很清晰...但是我是先看的OLTP和OLAP再转过头看DB和DM,弄反了)
| OLTP | OLAP | |
|---|---|---|
| 目的 | 专为实时业务运营而设计 | 用于按类别和属性分析、预测业务 |
| 方法 | 使用传统的DBMS | 使用数据仓库 |
| 询问 | 从数据库中插入,更新和删除信息 | 主要是选择操作 |
| 表 | 规范化的 | 没有规范化的 |
| 数据源 | OLTP及其事务 | 不同的OLTP数据库 |
| 数据完整性 | 必须维护数据的完整性 | 数据不会经常修改,故不存在问题 |
| 响应时间 | 毫秒 | 秒 |
| 数据质量 | 数据库中的数据始终是详细和有组织的 | 数据可能是无组织的 |
| 数据库特点 | 快速响应时间,低数据冗余并已标准化 | 集成不同的数据源以构建统一的数据仓库 |
| 操作 | 允许读/写操作 | 只读,很少写 |
| 查询类型 | 查询是标准化且简单的 | 涉及聚合的复杂查询 |
| 备份 | 完整的数据备份与增量备份相结合 | 仅需要不时备份,对时间要求不严格 |
| 用户 | 操作人员,如业务员、数据库专业人员 | 决策人员,如经理、CEO |
| 性能指标 | 交易吞吐量 | 查询吞吐量 |
| 用户数 | 允许成千上万的用户 | 仅允许数百个用户 |
| 处理 | 为日常使用的数据提供快速的结果 | 确保对查询的响应更快 |
推荐阅读:OLAP基础入门
在学习数据库的时候发现自己对很多概念都不太了解,比如
DB、DW、DBMS、OLAP、OLTP分别指什么;将图数据库系统(例如Neo4j、Dgraph等)和图计算系统(例如Spark下的Graphx)混为一谈等等。充分暴露了我基础知识十分匮乏这一事实,陷入“递归式”学习······虽然这只是一些概念,简单了解后直接学习相关数据库操作是完全没有问题的,但秉承着“看都看了不如透彻一点”以及“万一以后面试问到了呢”的想法,我还是整理记录一下。如果有不妥的地方欢迎指正。
Database is a systematic collection of data. A database contains information organized in columns, rows, and tables that is periodically indexed to make accessing relevant information more accessible.
Many enterprises and organizations create and manage databases using a database management system (DBMS). Organizations most often use databases for online transaction processing (OLTP).
Database software needs to provide easy access to information and fast querying so that transactions can be carried out efficiently. Databases are often referred to as operational systems, meaning they are used to process day-to-day transactions in an organization.
Most databases use a normalized data structure. Data normalization means reorganizing data so that it contains no redundant data, and all related data items are stored together, with related data separated into multiple tables. Normalizing data ensures the database takes up minimal disk space while response times are maximized.
关键词:规范化的数据结构 无冗余数据 能方便地访问信息 提供快速查询 用于处理日常事务
关系:使用DBMS(数据库管理系统)创建和管理DB(数据库),用DB进行OLTP(在线事务处理)
通俗说法:DB保留的是数据信息的最新状态,且只有这一个状态,无法看到历史状态。
A data warehouse is a system that pulls together data from many different sources within an organization for reporting and analysis. The reports created from complex queries within a data warehouse are used to make business decisions.
The primary focus of a data warehouse is to provide a correlation between data from existing systems. Data warehouses are used for online analytical processing (OLAP), which uses complex queries to analyze rather than process transactions.
The more normalized your data is, the more complex the queries needed to read the data because a single query combines data from many tables. The data in a data warehouse does not need to be organized for quick transactions. Therefore, data warehouses normally use a denormalized data structure. A denormalized data structure uses fewer tables because it groups data and doesn’t exclude data redundancies. Denormalization offers better performance when reading data for analytical purposes.
关键词:非规范化的数据结构(星型、雪花型) 不排除冗余数据 集合不同来源的数据 进行分析 支持复杂查询
关系:用DW进行OLAP(在线分析处理)
通俗说法:保存的是DB中的不同时间点的状态。对同一个数据信息,保留不同时间点的状态,就便于做统计分析。
数据仓库的架构由三层组成。架构的底层是加载和存储数据的数据库服务器。中间层包括用于访问和分析数据的分析引擎。顶层是通过报告、分析和数据挖掘工具呈现结果的前端客户端。
将数据整理成描述数据布局和类型(例如整数、数据字段或字符串)的 Schema。提取的数据将存储在 Schema 描述的各种表中。查询工具使用 Schema 来确定要访问和分析哪些数据表。
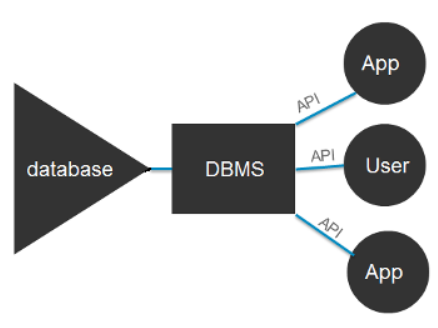
Database Management System is a collection of programs which enables its users to create, read, update and delete data in a database. The DBMS essentially serves as an interface between the database and end users or application programs, ensuring that data is consistently organized and remains easily accessible.
关键词:对数据库写读改删 数据库与终端用户/应用之间的接口
DW和DB都是关系数据系统,但它们的构建目的不同。DW用于存储大量历史数据,并支持对所有数据进行快速、复杂的查询,通常使用在线分析处理(OLAP)。 DB用于存储当前事务(指导致数据创建、更新、删除或检索的事件),并允许对正在进行的业务中的事务进行快速访问,即在线事务处理(OLTP)。
ETL/Extraction-Transformation-Loading用于完成DB到DW的数据转存,这一块涉及到的内容较多我还没看...之后会补充上来。
@unrealluver 在 问题描述:根据学者的论文信息分析其研究方向及变化时间线 中说:
- 不妨试试最简单的思路呢:
- 先对title和abstract用TF-IDF进行关键词抽取,
- 之后在和keywords合成one-hot向量,
- 最后余弦算距离.
嗷我试试看...但是有两个问题我不太清楚XD,可以请学长大概说一下吗?
@ryougi 在 Neo4j与Cypher语言学习笔记(一) 中说:
@chivas
VOSviewer和citespace的原理和用法还挺像的,但是citespace好像只针对特定的几个数据库(web of science等),这个是我同学当时用citespace导出的效果图,因为词条比较少所以连线还是比较清晰的。
但是这个图的问题也是和你说的一样的看不出来研究领域什么的,首先是出现的词条类别就比较混乱,有的是研究领域,有的是专业名词,还有的是动词等等杂七乱八的;其次就是连线本身只是表明节点之间有关,没有具体的关系内容。我觉得有可能是citespace本身不能检索出这层信息,所以我打算自己用Neo4j整理一下这张图的词条,先对节点分类然后自己补充一些关系,再用Neo4j的浏览器把关系图导出来,但是我现在不是很清楚有哪些内容是我能够完善的以及词条之间到底怎么划分关系,所以我这边的图还没画完。
那可能是直接用citespace对的这些数据库接口然后在线分析的,不知道这样做提供的数据项有哪些...我是收集了一位学者的94篇论文pdf,然后进行元数据提取,能得到论文的title、author、kewywords、abstract、jounral、year等等信息,然后将RIS文件导入。而且其实我可以对VOSviewer最后筛选出来的关键词进行手动选择,如果是动词等等乱七八糟的我是可以划掉的,最后的可视化就不会出现这些词...但是我不可能对每一个学者都手动去操作QAQ
@ryougi 在 Neo4j与Cypher语言学习笔记(一) 中说:
@ryougi
简单来说就是我怀疑这些个可视化工具并不能实现图中节点的归类的效果,或者是原来的数据库里面没有包含这部分信息,所以我现在想自己整理一个小的数据库然后用Neo4j的可视化工具导出一张图。
这个其实是和它们背后选用的算法有关...像VOSviewer的话就是对abstract做词共现分析,简单说就是如果这两个词总是同时出现,就认为它们关系紧密...然后根据关系远近聚类,关系近的就划分为同一类
目前有一个比较简单的想法是,venue.raw这一数据项可能用于对学者的研究领域进行初步分类。因为中国计算机学会推荐的国际学术期刊本身是按领域划分的,且有A类、B类等。如IEEE Transactions on Dependable and Secure Computing就是网络与信息安全方向的A类期刊;ACM Transactions on Graphics被划分为计算机图形学与多媒体方向的A类期刊;AAAI Conference on Artificial Intelligence是人工智能方向的A类学术会议······在获得了这样一份会议/期刊分类列表后,通过对该学者的每篇论文的venue.raw属性查找其所属于的领域方向,就能得到一个大概的分类。