为啥貌似要经常改这个。重开又要重新搞!
continue 发布的帖子
-
Visualizing and Understanding Convolutional Networks 论文笔记发布在 AI方向
概述
神经网络的可视化是一个解释黑盒模型的重要手段。之前有很多方案,比如查看feature maps、遮挡区域、噪声生成等方式。Visualizing and Understanding Convolutional Networks算是一种比较高端的思路,通过反卷积的手段获取可视化结果。之所以翻译这篇论文,首先是因为自己励志做一个高产的up主,另外在最近研究GAN的时候,发现DCGAN的生成器和该论文有异曲同工之妙,加之之前博客对这篇论文简介的不够透彻,故自给自足翻论文看了。
还是先坑后填。5.13之前会填的。

-
深度学习—你的数据够多么?发布在 AI方向
引用
谷歌研究文章:http://www.anyv.net/index.php/article-1427413
百度研究院文章:http://www.sohu.com/a/209748313_114877数据够多么?
这里两家巨佬的一致性结论,明确一下深度学习萌新们对于数据量的一个观点,这也是我之前一直考虑的事情:网络喂入的数据量大了之后会不会导致网络分不出来,或者到了无法解析的瓶颈。下面来解决大家这个疑惑!
数据量不同阶段
通常使用的模型一样时,喂不同数量级的数据可以性能呈现3个阶段(下图横坐标取了对数)。
- 第一阶段:数据很少,网络学习不出东西。
- 第二阶段:数据多了,随着数据指数增长,性能线性提升。
- 第三阶段:饱和了,数据大到一定程度,上帝都分不清楚了,当前模型理论无法超越的底线。
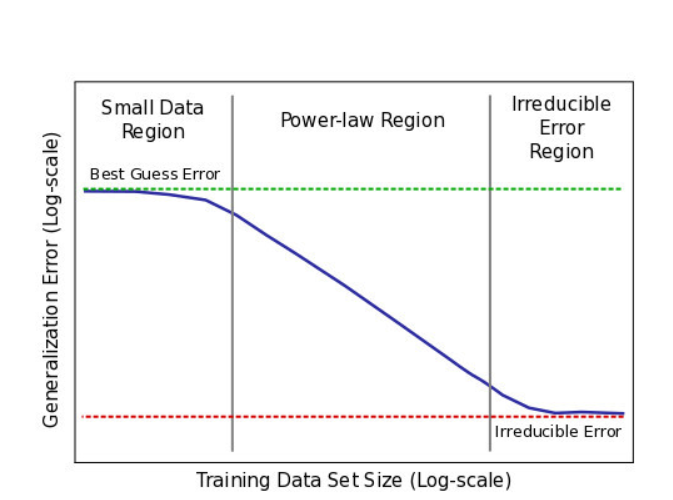
然而~,google在3亿张图片上进行了测试,发现这个数量级,仍然保持了这个规律,有点像摩尔定律哦~,说明对于很多深度学习问题来说,数据量永远不要担心太多。下图训练集中存在20%的噪声,但是大数据量还是掩盖了噪声的干扰(这一点没有去原文论证)。其次,随着数据的增大,网络的容量增大是必要的,不然无法满足其所需的复杂度。
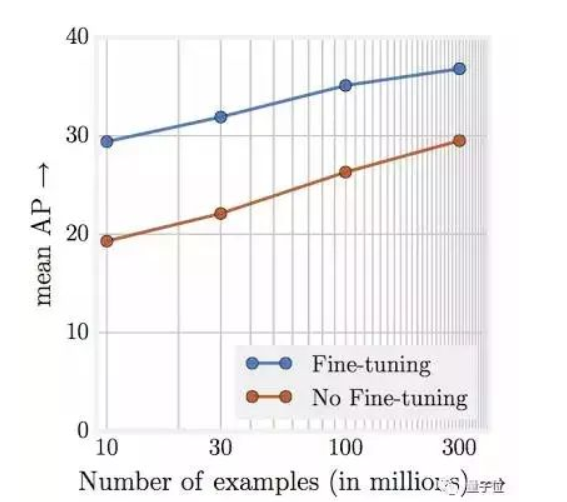
一点结论
- 数据不怕多,目前的问题,数据越多越好
- 数据不怕噪声(一定程度内),数据噪声可以被数据量部分掩盖
- 数据越大,网络需要越大,这里的大不光是参数变多,同时也对应着更深的网络。(有人研究,相同复杂度的情况下,深层网络会比浅层宽网络更容易训练哦)
-
Pytorch使用tensorboard发布在 AI方向
Tensorboard神奇一键应用于Pytorch
pip install tensorboardX
from tensorboardX import SummaryWriter writer = SummaryWriter('Summary/') # in training loop writer.add_scalar('Train/Loss', loss, num_iteration)好,已经可以愉快的玩耍了,至于图片啥的,函数都Ok的,其他图后续有需求再去找吧。
-
神经网络激活函数解析发布在 AI方向
概述
最近各种调试网络,激活函数作为神经网络的一个重要部分,肯定是需要考虑在内的。虽然之前的网络架构里面借鉴了别人无脑用ReLU的思路,但是还是想自己尝试下,激活函数之间的差异,并且这里对激活函数的含义和要求做一个简短的解析。
关于异或
这里盗了NG课程的图,我们首先来思考一个问题,给两个变量x1,x2,是否存在f(x1,x2) = x1 xor x2。xor就是这里所说的异或,真值表如下。对于线性函数,我们无法做到满足上述公式。那么答案肯定要借助非线性公式了,神经网络中,我们通过多层感知机,并在层与层之前加入非线性激活函数,通过这种非线性叠加的方式来模拟复杂函数。
XOR truth table
Input Output
A B
0 0 0
0 1 1
1 0 1
1 1 0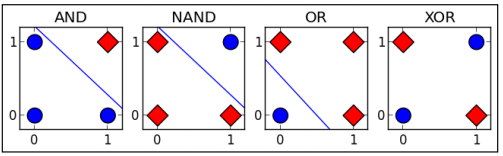
下图可以看到,非线性的函数很轻松可以完成xor操作啦。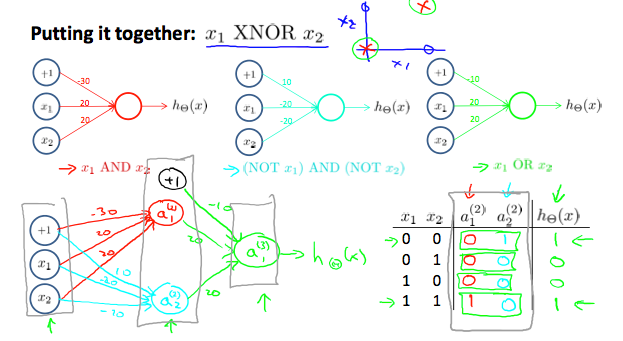
是否这样可以模拟任何函数呐?
我想答案应该是否定的!
论文解答:
This paper rigorously establishes that standard multilayer feedforward networks with as few as one hidden layer using using arbitrary squashing functions are capable of approximating any Borel measurable function from one finite dimensional space to another to any desired degree of accuracy, provided sufficiently many hidden units are available.
人话解释:上述做法可以拟合任意的博雷尔可测(Borel measurable)函数,至于啥是Borel可测,我就不知道了,反正就是可以模拟大多数我们需要的函数。
知乎链接:https://www.zhihu.com/question/58304333/answer/311054863激活函数要求
上述说明,已经明白了,激活函数的意义就在于让网络具备更强的拟合能力,如果没有非线性层,多层的网络也会退化成线性函数。同时,我们的网络利用反向传播的方式进行计算,我们激活函数也需要结合这一特性。
常见激活函数相关话题:
- 梯度消散
- 梯度爆炸
- 节点死了(ReLU)
我们先来看看反向传播,这里随便贴了一张图
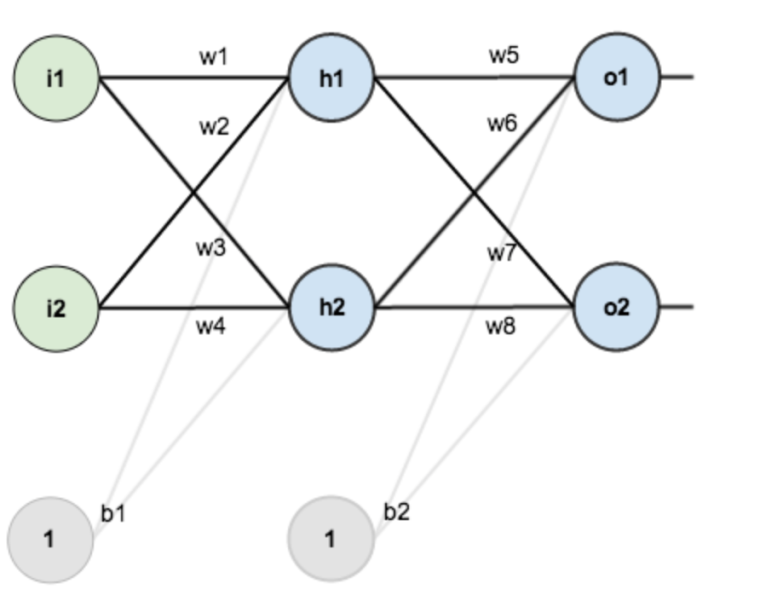
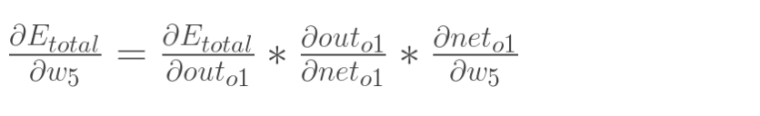
我们使用链式法则可以看到,梯度的计算合激活函数的输出,激活函数的梯度都有着密切的关系,那么多层网络中这些因子会乘起来,如果这个值大于1,或者始终小于1,那么梯度就会传播过程中累计超出控制范围,变成梯度爆炸或者梯度消失。这里我们就要求激活函数的值域和导数域有一定的范围。激活函数特性总结:(https://www.zhihu.com/question/67366051)
- 非线性:即导数不是常数。这个条件前面很多答主都提到了,是多层神经网络的基础,保证多层网络不退化成单层线性网络。这也是激活函数的意义所在,这里ReLU虽然是常数,但是分段了,也具有非线性特征。
- 几乎处处可微:可微性保证了在优化中梯度的可计算性。传统的激活函数如sigmoid等满足处处可微。对于分段线性函数比如ReLU,只满足几乎处处可微(即仅在有限个点处不可微)。对于SGD算法来说,由于几乎不可能收敛到梯度接近零的位置,有限的不可微点对于优化结果不会有很大影响[1]。
- 计算简单:正如题主所说,非线性函数有很多。极端的说,一个多层神经网络也可以作为一个非线性函数,类似于Network In Network[2]中把它当做卷积操作的做法。但激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。这也是ReLU之流比其它使用Exp等操作的激活函数更受欢迎的其中一个原因。
- 非饱和性(saturation):饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。最经典的例子是Sigmoid,它的导数在x为比较大的正值和比较小的负值时都会接近于0。更极端的例子是阶跃函数,由于它在几乎所有位置的梯度都为0,因此处处饱和,无法作为激活函数。ReLU在x>0时导数恒为1,因此对于再大的正值也不会饱和。但同时对于x<0,其梯度恒为0,这时候它也会出现饱和的现象(在这种情况下通常称为dying ReLU)。Leaky ReLU[3]和PReLU[4]的提出正是为了解决这一问题。
- 单调性(monotonic):即导数符号不变。这个性质大部分激活函数都有,除了诸如sin、cos等。个人理解,单调性使得在激活函数处的梯度方向不会经常改变,从而让训练更容易收敛。
- 输出范围有限:有限的输出范围使得网络对于一些比较大的输入也会比较稳定,这也是为什么早期的激活函数都以此类函数为主,如Sigmoid、TanH。但这导致了前面提到的梯度消失问题,而且强行让每一层的输出限制到固定范围会限制其表达能力。因此现在这类函数仅用于某些需要特定输出范围的场合,比如概率输出(此时loss函数中的log操作能够抵消其梯度消失的影响[1])、LSTM里的gate函数。
- 接近恒等变换(identity):即约等于x。这样的好处是使得输出的幅值不会随着深度的增加而发生显著的增加,从而使网络更为稳定,同时梯度也能够更容易地回传。这个与非线性是有点矛盾的,因此激活函数基本只是部分满足这个条件,比如TanH只在原点附近有线性区(在原点为0且在原点的导数为1),而ReLU只在x>0时为线性。这个性质也让初始化参数范围的推导更为简单[5][4]。额外提一句,这种恒等变换的性质也被其他一些网络结构设计所借鉴,比如CNN中的ResNet[6]和RNN中的LSTM。
- 参数少:大部分激活函数都是没有参数的。像PReLU带单个参数会略微增加网络的大小。还有一个例外是Maxout[7],尽管本身没有参数,但在同样输出通道数下k路Maxout需要的输入通道数是其它函数的k倍,这意味着神经元数目也需要变为k倍;但如果不考虑维持输出通道数的情况下,该激活函数又能将参数个数减少为原来的k倍。
- 归一化(normalization):这个是最近才出来的概念,对应的激活函数是SELU[8],主要思想是使样本分布自动归一化到零均值、单位方差的分布,从而稳定训练。在这之前,这种归一化的思想也被用于网络结构的设计,比如Batch Normalization[9]。
如何看待ReLU的非线性
ReLU作为一种常见的激活函数,真的是再简单不过了,其优点简单,导数为1等吧,缺点在于学习率过大,或者梯度过大容易造成节点死亡。但是这里很多同学可能不太理解,为什么ReLU可以作为激活函数,这明明就很线性啊~
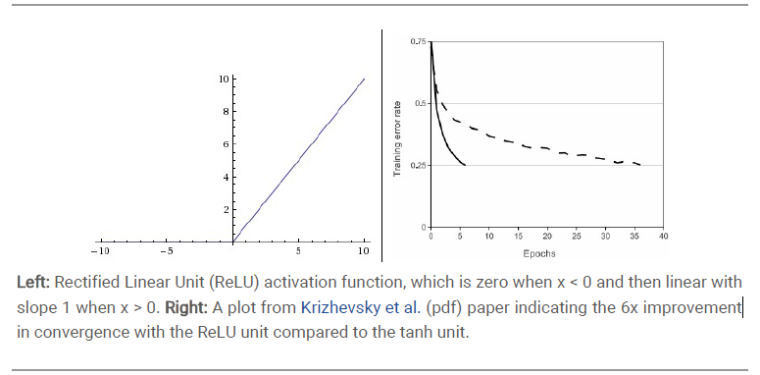
首先扯一扯生物学的角度,人脑的信号是很稀疏的,类比神经网络,我们网络1w个节点,可能就是1k个在起作用,那么我们干脆让ReLU把那些用不上的给“搞死”好了,这样网络可以根据任务自动的选择网络需要多少节点,自动稀疏化网络结构,听起来非常棒的。
以上可以看到,部分的稀疏化网络就引入了非线性的因素了,应该max(0,λ)本身就不是个线性操作。类比最开始提到的异或,ReLU可以很容易的完成XOR操作,所以ReLU的非线性是稳稳没毛病的。
一点点心得
- ReLU网络不深的时候,常见的激活函数差异不大。
- ReLU死了很多的时候,需要注意换成其他的激活函数,或者ReLU的变种。
- 网络深的时候,Sigmoid,tanh这种需要注意梯度消散,可以适当引入Bn。
-
Deep Pyramid Convolutional Neural Networks for Text Categorization论文笔记发布在 AI方向
概述
关于nlp的文本分类,textCNN是一个非常棒的模型,但是textCNN的本质还是词袋的模型,小瑶(夕小瑶的卖萌屋)总结说,textCNN较之前模型的收益来源于textCNN对词进行了embedding,这使得能够学习出词之前的近语义关系。那么问题来了,我们能否通过卷积获得长距离的关系呢,本文DPCNN给出了答案。
关于特征层和分类层
传送门:https://www.zhihu.com/question/270245936/answer/356176790
关于知乎上一个问题,主要讨论在图像或者文本领域,提升特征层的复杂度和提升分类层的复杂度哪个性价比高一点的问题。里面小瑶的回答已经非常不错了,这里我提出一点自己的看法。
首先看数据,如果我们假设数据足够充足的情况下,那么提取词袋词嵌入特征,那么我们利用多层fc是可以对这些相对低纬度的特征进行组合的。其等价于抽取了高纬度特征。然而,重点在于数据一般没那么好,没那么全,高层分类里面会学习出来不存在的特征,也就是过拟合,小瑶在回答中提到fc*3可以得到很好的效果,但是这个说法并不通用,在贝贝智能客服上使用不同层fc得到的效果为1层效果最佳。个人分析,1层本来就可以很好的分类拟合了,过复杂的分类层引入了针对该训练集的一些特征组合。那么如果使用复杂的特征抽取层,好像可以一定程度避免这个问题,抽取的特征在这些数据集上存在,也就是用复杂的特征层抽取的高纬度特征是真实存在的,并不是为了强行拟合训练集产生的(个人想法,也就方便理解)。这点在之后,会给出dpcnn在现有贝贝客服数据集上的表现来佐证。论文阅读
论文观点
图像领域通过不断加深网络,抽取了高纬度特征,效果提升显著。文本领域一直没有很好的抽取高纬度特征的思路,另一方面,很多人认为文本的特征就是词语,所以浅层网络就可以很好的抽取特征。本文解决两个问题:
- 使用多层网络抽取长距离的文本特征(类似于RNN)
- 类比ResNet使用深层网络抽取特征(越深越好呗)
论文关键点
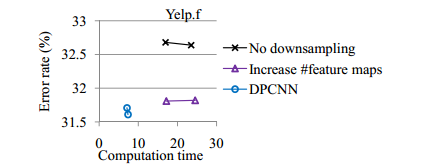
- 下采样控制特征图的数量,这样计算复杂度得到了控制,始终为一个卷积块的2倍左右(每层除2,加起来刚好2倍),同时测试也证明,如果不做这样一层下采样,复杂度提升的同时并不能带来准确率的提升。
- 短连接,类似于ResNet中的跨层恒等映射。
- 使用非监督的词向量提升准确率,比如预先使用log数据训练word2vec。
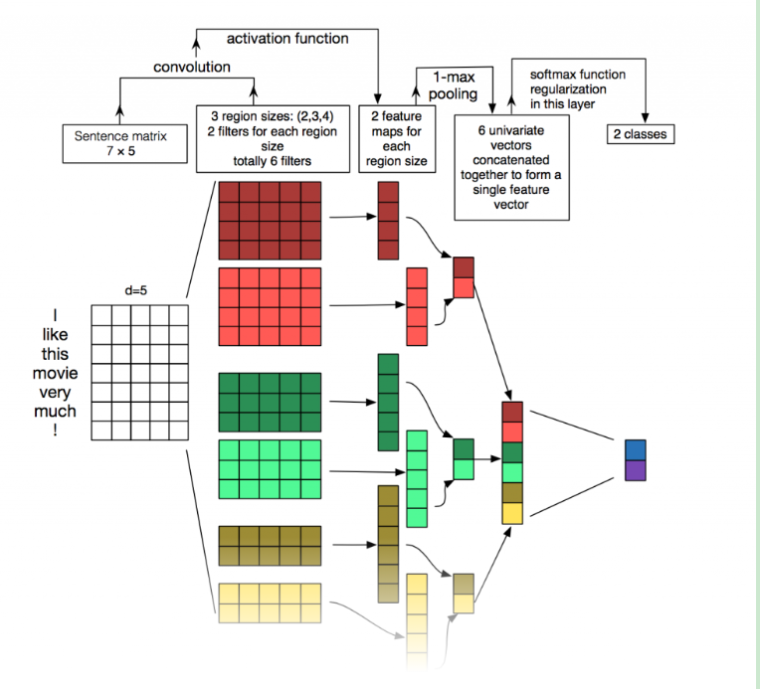
下图是文章的结构图,左边为DPCNN,中间是TextCNN,右边是ResNet
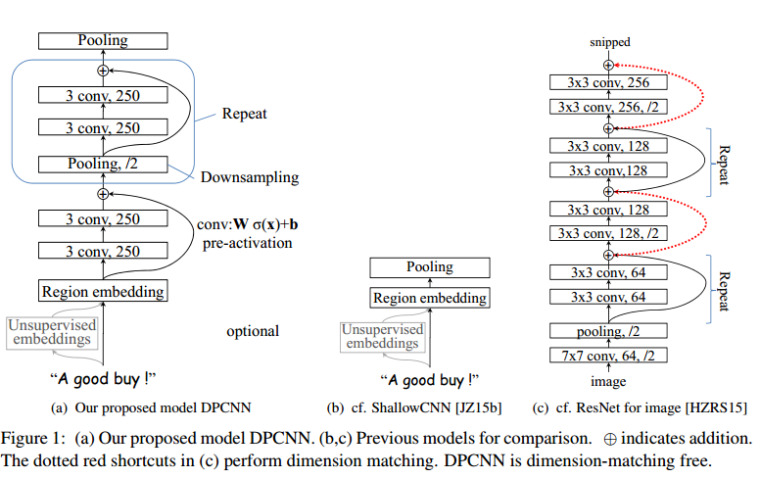
网络结构
下采样层(Downsampling with the number of feature maps fixed)
在每一个卷积层之后,使用max-pooling(size=3,stride=2)来进行采样。对于采样这个操作,一个降低计算复杂度,另一个就是很多之前不进行下采样的模型效果都不好,采样之后的图如下,一个金字塔形,这也就是论文中Pyramid的含义。
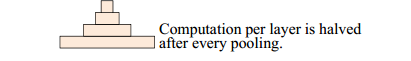
短连接(Shortcut connections with pre-activation)
为了训练更深的网络,我们使用shortcut connections(后以短连接代替)。加号的地方表示Wσ(x)+b,W的行数为特征图的数量,这里是250。σ我们使用ReLU,σ(x)=max(x,0)。这里不太过多介绍,有兴趣的去看ResNet的文章,这里只要知道这种短连接的方式可以使网络加深而不至于无法训练就Ok。
无需维度匹配
这里是ResNet中的一个章节,大家看ResNet的网络结构,每层的输出尺度都不一样,那恒等变换就需要让不同尺度的特征图相加,ResNet中使用如下公式进行匹配,而我们这里可以看到,我们是的短连接是没有过采样层的,这样避免了这个维度匹配问题,当然这里文章也考虑这样是否有不好的影响,做了相应的测试,发现还ok啦。
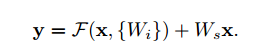
词区域嵌入(Text Region embedding)
从最上面图中的a和c的对比可以看出,DPCNN与ResNet差异还是蛮大的。同时DPCNN的底层貌似保持了跟TextCNN一样的结构,这里作者将TextCNN的包含多尺寸卷积滤波器的卷积层的卷积结果称之为Region embedding,意思就是对一个文本区域/片段(比如3gram)进行一组卷积操作后生成的embedding。对一个3gram进行卷积操作时可以有两种选择,一种是保留词序,也就是设置一组size=3*D的二维卷积核对3gram进行卷积(其中D是word embedding维度);还有一种是不保留词序(即使用词袋模型),即首先对3gram中的3个词的embedding取均值得到一个size=D的向量,然后设置一组size=D的一维卷积核对该3gram进行卷积。显然TextCNN里使用的是保留词序的做法,而DPCNN使用的是词袋模型的做法,DPCNN作者argue前者做法更容易造成过拟合,后者的性能却跟前者差不多(其实这个跟DAN网络(Deep averaging networks)中argue的原理和结论差不多,有兴趣的可以下拉到下一部分的知乎传送门中了解一下)。
通过预训练词向量增强(Enhancing region embedding with unsupervised embeddings)
这一点借用了textCNN的思路,类似语言模型的预测,输入一个词,预测左右相邻的词,然后通过这个与训练的词向量初始化模型的词向量。类似word2vec,这里仅仅使用单层网络来训练。
实验
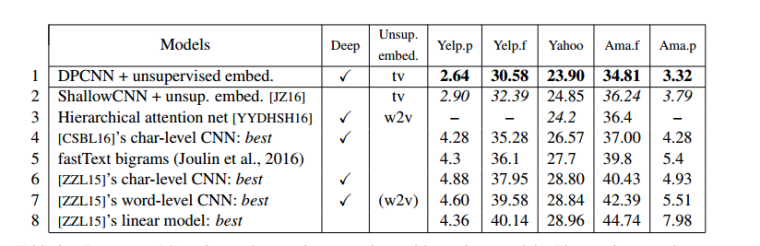
测试1:大数据集,验证有效性
测试2:耗时测试,验证计算复杂度

测试3:验证下采样的效果
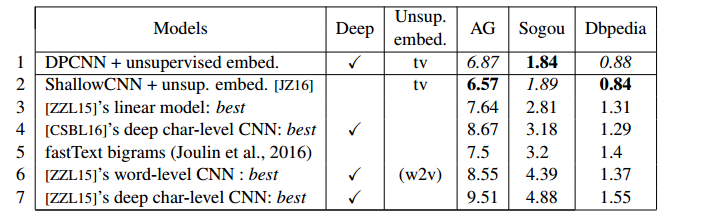
测试4:小数据集测试
测试5:非监督预训练
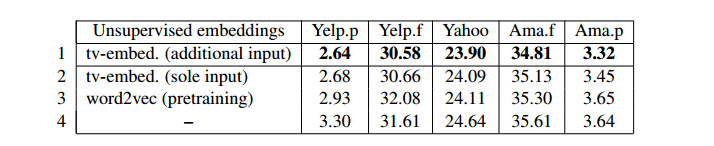
又看到了小瑶的文章:传送一个https://zhuanlan.zhihu.com/p/35457093
关于DPCNN实践与贝贝客服项目
经过一段时间的调参,回头看dpcnn原文数据使用了2分类数据。在贝贝数据集上,多分类很难调试,且二分类上特别容易过拟合。可能提取维度过高,最终放弃该方案。
-
anaconda cv2安装问题发布在 AI方向
问题 1.无法pip install cv2 2.cv2.pyd的方式anaconda下貌似不起作用,亲测下面命令可用。 解决方法: conda install --channel https://conda.anaconda.org/menpo opencv3
-
Learning to Learn: Model Regression Networks for Easy Small Sample Learning 论文笔记发布在 AI方向
概述:
响应zkjj的号召,来阅读一些前沿论文,本期第一次为zkjj推荐的Learning to learn在图像分类中的应用。
https://www.ri.cmu.edu/pub_files/2016/10/yuxiongw_eccv16_learntolearn.pdf
目标
通过之前分类器中的经验,使用小数据集完成新类别图像分类操作。
论文观点
- There exsits a generic category agnostic transformation from model learned from few samples to models learned from large enough sample sets.
- Such a transformation could be effectively learned by high-capacity regression network.
论文附图一张,这个图画的还算是,emmmm比较难以理解!!!
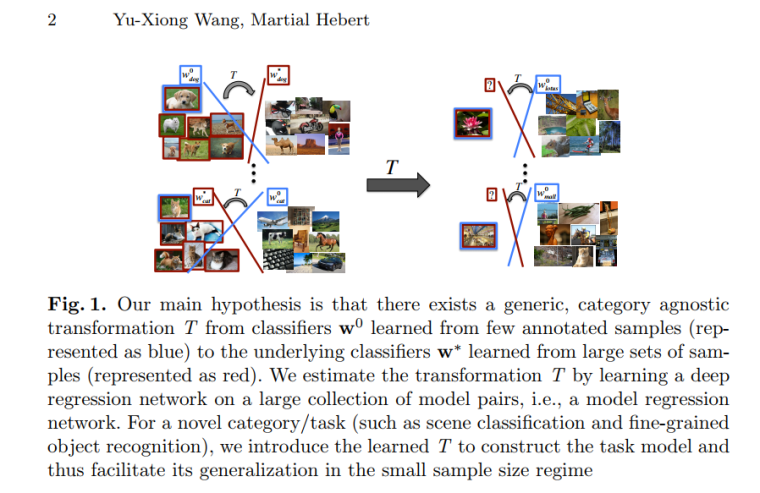
人话解释论文观点:
- 从小数据集中学习到的网络模型可以映射到从大数据集中学习到的网络模型:也就是说,有一个神奇的T函数,之前我们需要从大数据集中学习到一个网络的参数Θ_large,那么现在我们从小数据集中学习到一个网络参数Θ_little,然后我们Θ_large = T(Θ_little),是不是就比较神奇了,那我们就可以小样本学习了。
- T函数可以通过一个高容量回归网络从模型对中学习到:这里几个东西解释下
- 回归网络,之前我们的网络都是分类用的,这里任务为调整网络参数,所以变成了回归任务,就叫回归网络了,回归任务可以参考object detection里面的regression操作。
- 模型对:一个大数据集获得的模型,一个小数据集获得的模型,拿这两个model pair来训练T函数,是不是突然感觉很合理了。
- 实验的评估基于现有大数据样本的分类进行
PS:相比于之前transfer learning只迁移网络参数来说,这个思路确实有那么点learn to learn的思想在里面了,这一点论文中也给出了相应的证明,在测评上效果要优于transfer learning
看了这个图,应该就对整体的流程有所了解了吧~

如何生成模型对(Generation of Model Pairs)
PS:这里的分类器都是svm的二分类器,输入特征来自于CNN网络的特征图(后面有具体介绍)
C个类别的训练集,每个类分别选取model pair,选取的方式如下:
Lc个正样本M个负样本,训练一个w的参数,作为大样本模型的参数,
正样本选N个(N<<Lc)负样本M个训练一个w0的参数,作为小样本模型的参数,S次抽样。
最终生成Sx C个model pair(w0,w)
(选取思路没毛病)回归网络(Regression Network)
回归网络这里只是稍微简单介绍一下,论文提到,为了稳定性,把regression loss + preformance loss放一起。
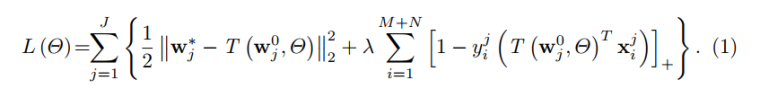
实现网络细节(Implementation Details)
- SVM的输入:Caffe Alexnet convolutional neural network (CNN) feature pre-trained on ILSVRC 2012,从fc6抽取了一个4096维度的特征向量。
- SVM训练:对于w*使用了10-fold交叉验证来训练,选取了不同的N,不同的正则系数,来做数据增强以模拟不同变化的w0。
- 每类700model pair,685训练,15验证。
新类学习方法(Learning Target Models for Novel Categories)
- 初始化,使用小样本学习一个w0。
- 使用T(W0,Θ)模拟w*
- 再训练(敲重点,敲重点,敲重点,这个在训练没在我预料之中,测试表明这个再训练过程很重要,可能是transform还是太粗糙了)
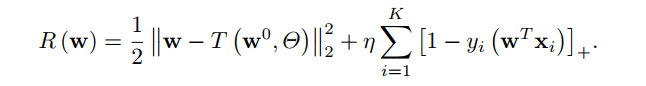
实验评估(Experimental Evaluation)
想要看具体测试数据和测试方式的去看原文!
第一测:小数据集上测评,绿色为直接在小数据集上测试,蓝色是论文结果,红色是大数据集上测试结果。提升效果还是不错的,算法有效,yeah~
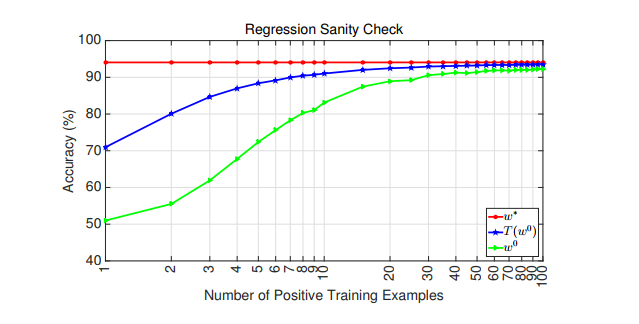
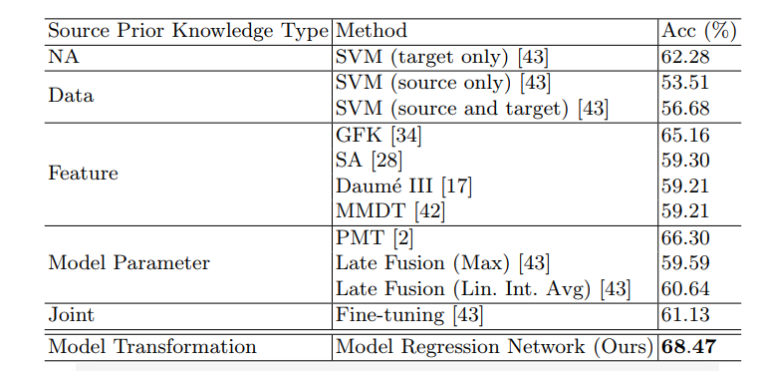
第二测:各种方案对比,当然本文方法最好啦,其他的思路也都是想用经验,不过没用好,model parameter就是之前提到的transfer learning,明显被踩了一脚。
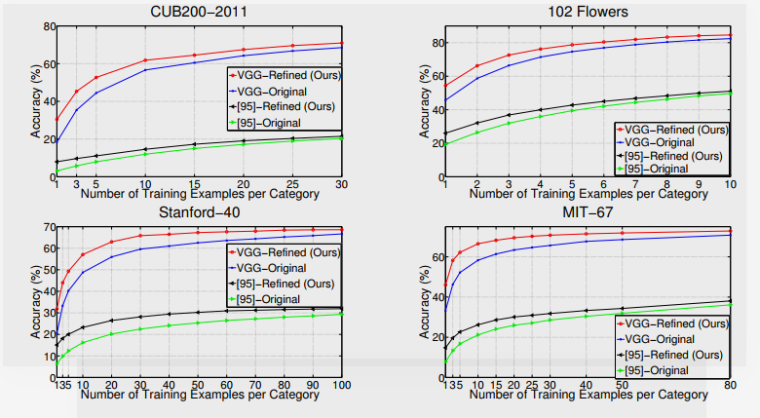
第三测:不同数据集上新类的小数据测评,效果也不错。绿色线再次踩transfer learning.

第四测:不同特征空间测评,证明该思想和特征没有绝对关系,通用性ok
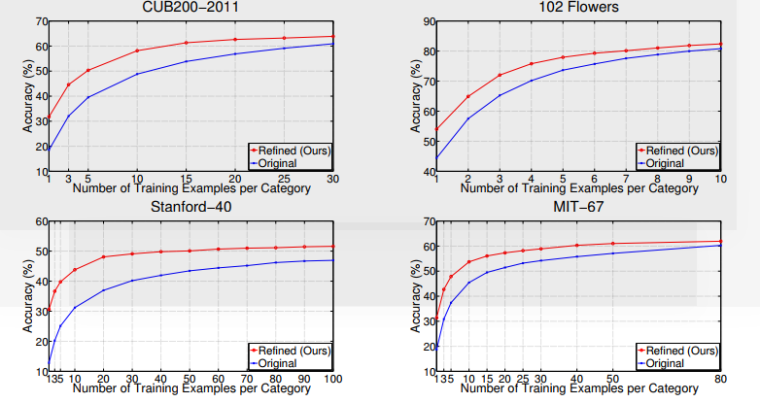
第五测:不同分类器测评,证明该思想和分类器没有多大关系,在lr上进行测试,通用性ok ok
小结
总得来说。不错的一篇文章,行为逻辑清晰,方法较为通用,并且on the level of model!
ok 翻译结束~励志做个高产up主
